x-archive-rag
Local-first MCP tools for searching and drafting from your X/Twitter archive.
Documentation
x-archive-rag
Turn your X/Twitter archive into a local AI memory layer.

![]()
![]()

Unlike uploading a ZIP to ChatGPT, x-archive-rag converts your archive into reusable local infrastructure: SQLite storage, repeatable retrieval, citation IDs, persona profiling, grounded draft prompts, a local web UI, and MCP tools that AI clients can query without receiving your whole archive.
The default workflow keeps your archive local. You decide when to export data or send a small retrieved evidence set to an OpenAI-compatible model.
If this is useful for your personal AI or MCP workflow, starring the repository helps other people find it: https://github.com/mameshivaa/x-archive-rag
What is technically different?
x-archive-rag is not a bigger prompt. It is a small local data layer for your archive.
| Capability | Why it matters |
|---|---|
| Local SQLite index | Import once, query repeatedly, inspect or back up the database. |
| Keyword + semantic + hybrid retrieval | Ask narrow questions without sending the whole archive every time. |
| Citation-grounded outputs | Search and draft prompts preserve tweet IDs such as T1. |
| Persona profile as separate state | Writing patterns are computed once and reused with retrieved evidence. |
| CLI, local web UI, export, and MCP | The same archive can serve humans, scripts, and AI clients. |
| Read-only MCP tools | Claude or another MCP client can retrieve evidence without posting to X or calling a remote model. |
Local web UI
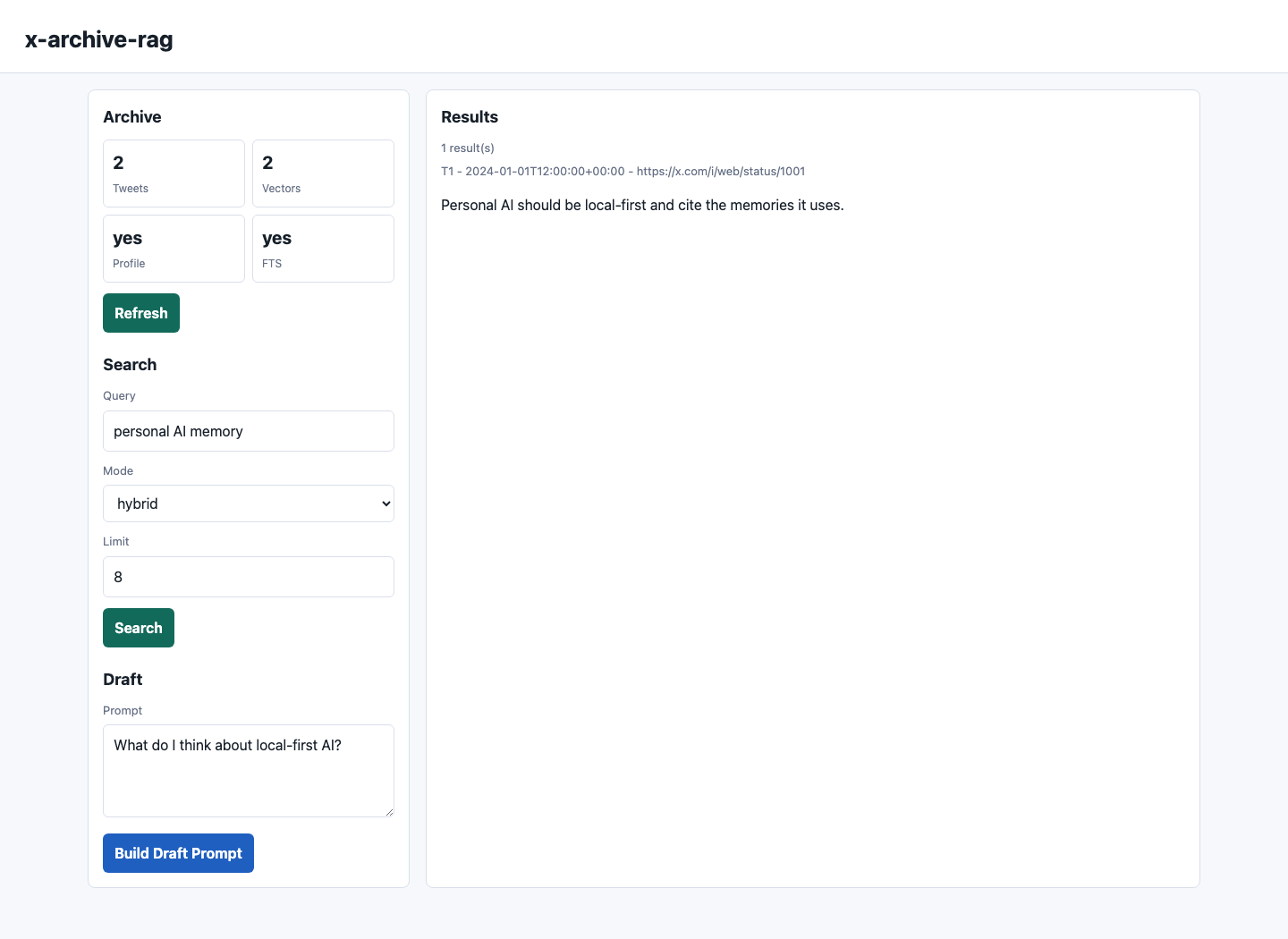
Run it locally after importing an archive:
x-archive-rag web --db ./memory.sqlite --open
Try the UI with the included sample archive before touching private data:
git clone https://github.com/mameshivaa/x-archive-rag.git
cd x-archive-rag
python3 -m pip install -e .
x-archive-rag demo --open
Terminal demo

What you can do
- Import your official X archive ZIP or extracted directory into a local SQLite database.
- Search it with keyword, semantic, or hybrid retrieval.
- Generate a persona profile from your own posts.
- Build citation-grounded draft prompts that show the tweets used as evidence.
- Expose the same local memory to AI clients through MCP tools.
Interface
The main interface is a small CLI with nine commands:
ingestturns an archive into a reusable local database.searchretrieves relevant posts with citation IDs.profilesummarizes recurring topics, tone, and writing patterns.draftbuilds a grounded prompt from retrieved evidence.mcpexposes the same memory to AI clients that support MCP.webruns a local browser UI for search, profile inspection, and draft prompts.democreates a sample database and can open the local web UI.doctorchecks whether a database is ready for search, draft, and MCP use.exportwrites imported tweets as JSONL or Markdown for inspection and reuse.
Text output is designed for humans. JSON and Markdown output are designed for scripts, agents, and repeatable workflows.
Status
Alpha. The current release is intentionally small:
- Import
tweets.js/tweet.jsfrom an extracted archive directory or archive ZIP, including common long-form tweet text fields and expanded URL entities. - Store normalized tweets in SQLite.
- Search with SQLite FTS5, dependency-free semantic retrieval, or hybrid retrieval.
- Generate a persona profile from your own posts.
- Build grounded RAG prompts with cited tweets.
- Expose archive search and draft prompts through a minimal MCP stdio server.
- Optionally call OpenAI-compatible chat completions using
OPENAI_API_KEY.
Why
Most archive tools help you search old posts. This project focuses on a different workflow:
"Given what I have said before, draft something that sounds like me, while showing the evidence."
The assistant is designed for drafting and reflection, not impersonation or automated posting.
Why not just upload the ZIP to ChatGPT?
Uploading a ZIP is a one-off context dump. x-archive-rag is a reusable memory layer.
| ZIP upload | x-archive-rag |
|---|---|
| Sends the archive to a remote chat session. | Imports the archive into a local SQLite database. |
| Relies on one model pass over a large attachment. | Retrieves only relevant tweets per question. |
| Hard to reproduce or inspect later. | Keeps repeatable search, export, and doctor checks. |
| Evidence can disappear into a summary. | Preserves citation IDs such as T1 in search and draft output. |
| Works only inside that chat session. | Exposes CLI, JSON, Markdown export, and MCP tools. |
For a deeper technical comparison, see docs/comparison.md.
Install
From a local checkout:
python3 -m pip install -e .
No runtime dependencies are required.
Quick start
Want to test without private archive data first?
x-archive-rag demo --open
The shortest path is:
x-archive-rag ingest ./twitter-archive.zip --db ./memory.sqlite
x-archive-rag profile --db ./memory.sqlite
x-archive-rag search "personal AI memory" --db ./memory.sqlite --mode hybrid
x-archive-rag draft "What do I think about OSS personal AI?" --db ./memory.sqlite
x-archive-rag web --db ./memory.sqlite --open
Use the sections below when you need more control over import format, date filters, exports, OpenAI-compatible calls, or MCP.
Want the Claude Desktop Extension artifact instead? Download the latest .mcpb from Releases and follow docs/mcpb.md.
AI coding agents and MCP marketplace reviewers can start from llms.txt or llms-install.md.
Prefer a browser surface? Run the local web UI and follow docs/web.md.
Import an extracted X archive directory:
x-archive-rag ingest ./twitter-archive --db ./x-archive-rag.sqlite
Retweets are excluded by default so profiles and drafts focus on your own statements. Add --include-retweets if you want to index retweets too.
Or import the original ZIP:
x-archive-rag ingest ./twitter-archive.zip --db ./x-archive-rag.sqlite
Search your archive:
x-archive-rag search "AI agents and personal tools" --db ./x-archive-rag.sqlite
Search and draft outputs include citation IDs such as T1, so generated text can refer back to specific retrieved posts.
Example search output:
[T1] 2024-01-01T12:00:00+00:00 https://x.com/i/web/status/1001
Personal AI should be local-first and cite the memories it uses.
JSON output is available for scripts:
x-archive-rag search "AI agents and personal tools" \
--db ./x-archive-rag.sqlite \
--json
Semantic and hybrid search are available without external services:
x-archive-rag search "grounded memory for drafts" \
--db ./x-archive-rag.sqlite \
--mode hybrid
Limit retrieval to a time range when older views should not influence a draft:
x-archive-rag search "personal AI" \
--db ./x-archive-rag.sqlite \
--since 2024-01-01 \
--until 2024-12-31
Build a persona profile:
x-archive-rag profile --db ./x-archive-rag.sqlite
Profiles include the number of tweets analyzed and the covered date range.
Draft with retrieved context:
x-archive-rag draft "What do I think about OSS personal AI?" \
--db ./x-archive-rag.sqlite \
--mode hybrid \
--output ./draft.md
The draft command builds an evidence-grounded prompt. It does not call a remote model unless --call-openai is set.
Retrieved tweets:
[T1] 2024-01-01T12:00:00+00:00 https://x.com/i/web/status/1001
Personal AI should be local-first and cite the memories it uses.
Task:
Draft a response that is grounded in the retrieved tweets and consistent with the persona profile.
Call an OpenAI-compatible model:
export OPENAI_API_KEY="..."
x-archive-rag draft "What do I think about OSS personal AI?" \
--db ./x-archive-rag.sqlite \
--call-openai \
--model gpt-4.1-mini
Use an OpenAI-compatible endpoint:
x-archive-rag draft "What do I think about local-first AI?" \
--db ./x-archive-rag.sqlite \
--call-openai \
--model local-model \
--base-url http://localhost:8000/v1
Run as an MCP stdio server:
x-archive-rag mcp --db ./x-archive-rag.sqlite
Available MCP tools:
search_archivedraft_from_archiveget_persona_profile
Check database readiness:
x-archive-rag doctor --db ./x-archive-rag.sqlite
Export imported tweets for inspection or backup:
x-archive-rag export \
--db ./x-archive-rag.sqlite \
--format jsonl \
--output ./tweets.jsonl
See docs/cli.md for the full CLI reference.
Design
The pipeline is deliberately simple:
X archive ZIP or directory
-> tweet normalization
-> persistent SQLite memory + FTS5 + lightweight semantic vectors
-> per-prompt retrieval with citation IDs
-> persona profile
-> grounded draft prompt, optional LLM call, or MCP tool response
Future releases can add external embedding providers, thread reconstruction, and local model providers without changing the core import/search model. The current release already includes CLI, MCP, export, and local web UI surfaces over the same SQLite memory layer.
Safety and ethics
Use this with your own archive or with explicit permission. The project is meant to help a person understand and draft from their own history. It should not be used to impersonate someone, automate posting as someone else, or hide AI-generated output as human-authored speech.
Generated drafts should cite the retrieved posts they used. Treat the output as a draft that needs human review.
See docs/privacy.md for local data flow and remote-call details.
Privacy Policy
x-archive-rag is local-first. Archive ZIPs, extracted archive directories, SQLite databases, persona profiles, draft prompts, and exports stay on the user's machine unless the user explicitly exports them or uses an optional remote LLM call.
MCP mode is read-only: it reads from the configured local SQLite database and returns retrieved tweets, the stored persona profile, or grounded draft prompts to the connected AI client. It does not post to X and does not call a remote LLM provider.
The full privacy policy is in docs/privacy.md.
Development
Run the full local verification suite:
make verify
Run the CLI without installing:
PYTHONPATH=src python3 -m x_archive_rag --help
PYTHONPATH=src python3 -m x_archive_rag --version
Run the sample archive smoke test:
make smoke
See docs/architecture.md for the module layout and planned extension points. See docs/cli.md for the full CLI reference. See docs/mcp.md for MCP setup examples. See docs/mcpb.md for the Claude Desktop Extension bundle. See docs/web.md for the local browser UI. See docs/privacy.md for local data flow and remote-call details. See docs/directory-submission.md for Claude and ChatGPT directory submission notes. See docs/launch.md for public launch copy and sharing assets. See server.json for official MCP Registry metadata. See docs/release/checklist.md before publishing a release. See docs/release/publishing.md for first public repository steps. See CODE_OF_CONDUCT.md, CONTRIBUTING.md, and SECURITY.md before opening issues or pull requests. See CITATION.cff if you need citation metadata.
License
MIT