Urlbox Full Page Screenshots MCP Server
официальныйMCP-сервер для Urlbox Screenshot API. Он позволяет вашему клиенту делать скриншоты, создавать PDF-файлы, извлекать HTML/markdown и многое другое с веб-сайтов.
Документация
Urlbox MCP-сервер
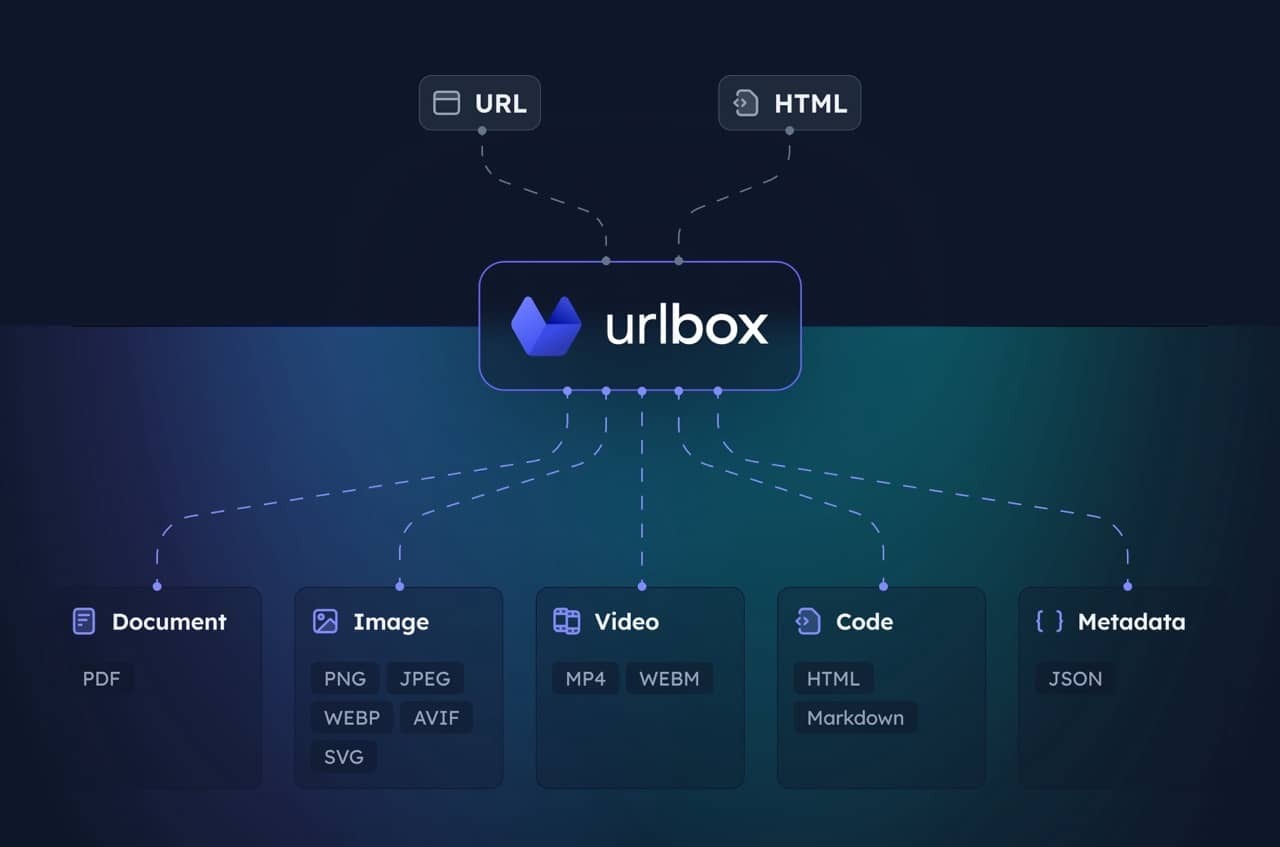
MCP-сервер для Urlbox Screenshot API. Позволяет вашему клиенту делать скриншоты, генерировать PDF, извлекать HTML/markdown и многое другое с веб-сайтов.
Посетите Urlbox для получения дополнительной информации, ознакомьтесь с нашей документацией или пообщайтесь с вашей LLM после установки, чтобы хорошо понять его возможности и опции.
Настройка
-
Установите зависимости и выполните сборку:
npm install npm run build -
Получите учетные данные Urlbox API:
- Зарегистрируйтесь на urlbox.com
- Получите ваш API Secret в панели управления
-
Установите переменные окружения:
claude_desktop_config.json
{
"mcpServers": {
"screenshot": {
"command": "npx",
"args": ["-y", "@urlbox/screenshot-mcp"],
"env": {
"SECRET_KEY": "your_api_key_here"
}
}
}
}
Использование
Сервер предоставляет инструмент render, который может:
- Делать скриншоты в различных форматах (PNG, PDF, MP4 и другие)
- Конвертировать страницы в HTML, markdown
- Извлекать метаданные и cookies
- Сохранять файлы локально в ваши загрузки с помощью
store_renders: true
Claude будет автоматически использовать это, когда вы попросите его сделать скриншот веб-сайта или конвертировать веб-контент.
Полезные промпты
Сделать чистый скриншот без рекламы и баннеров cookie:
Take a screenshot of https://example.com but block ads and hide cookie banners
Сделать скриншот и сохранить побочные рендеры, такие как HTML/markdown:
Take a screenshot of https://example.com and also save it as HTML and markdown. Download the result to my computer.
Сгенерировать PDF всей страницы:
Convert https://urlbox.com to a PDF and save it to my computer. Make sure to generate a PDF that has an outline and is tagged.