Scrapeless MCP Server
公式リアルタイムのScrapeless Google SERP(Google検索、Googleフライト、Googleマップ、Google求人など)の結果をLLMアプリケーションに統合します。このサーバーは、AIワークフロー、チャットボット、リサーチツールに動的なコンテキスト取得を可能にします。
ドキュメント

Scrapeless MCP Server
公式Scrapeless Model Context Protocol (MCP) Serverへようこそ — LLM、AIエージェント、AIアプリケーションがリアルタイムにWebと対話できるようにする強力な統合レイヤーです。
オープンなMCP標準に基づいて構築されたScrapeless MCP Serverは、ChatGPT、Claude、Cursor、Windsurfなどのモデルやツールを、以下のような幅広い外部機能にシームレスに接続します。
- Googleサービス統合 (検索、トレンド)
- ページレベルのナビゲーションと操作のためのブラウザ自動化
- 動的でJavaScriptを多用するサイトのスクレイピング — HTML、Markdown、スクリーンショットとしてエクスポート
AIリサーチアシスタント、コーディングコパイロット、自律型Webエージェントのいずれを構築する場合でも、このサーバーはワークフローに必要な動的なコンテキストと実世界のデータをブロックされることなく提供します。
使用例
- Claudeを使用した自動Web操作とデータ抽出
Scrapeless MCP Browserを使用することで、Claudeは会話形式のコマンドを通じてWebナビゲーション、クリック、スクロール、スクレイピングなどの複雑なタスクを実行でき、live sessionsを介してWeb操作結果をリアルタイムでプレビューできます。
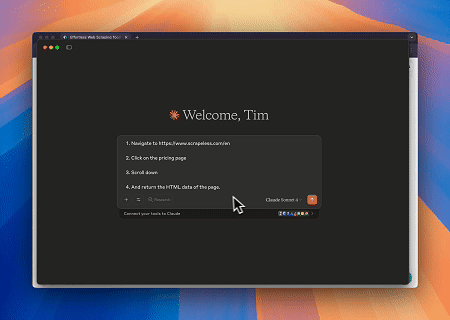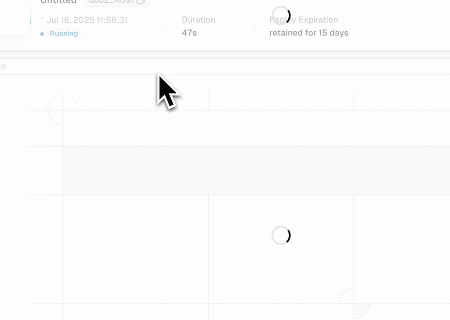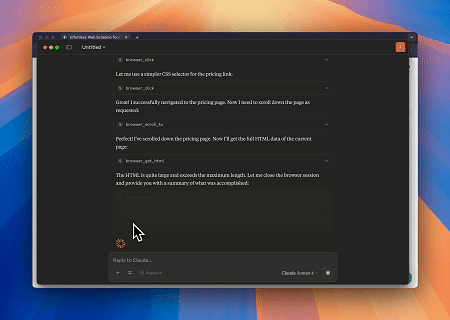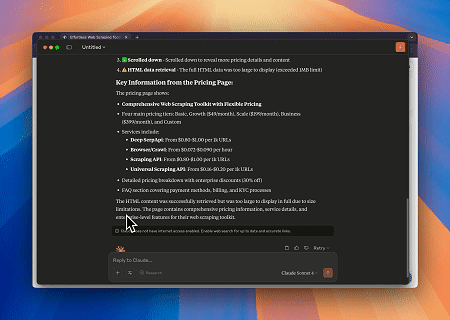
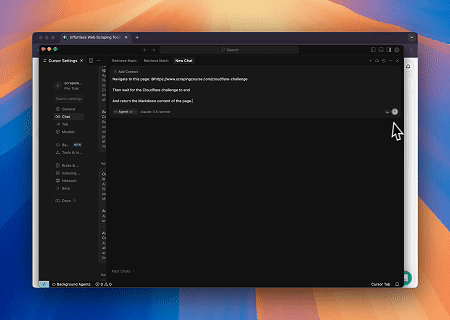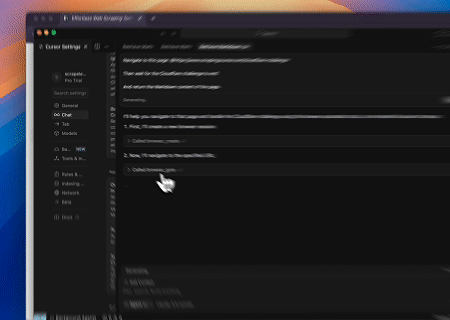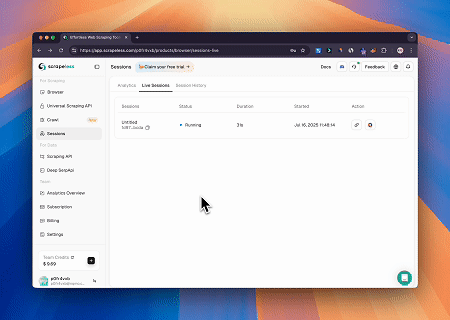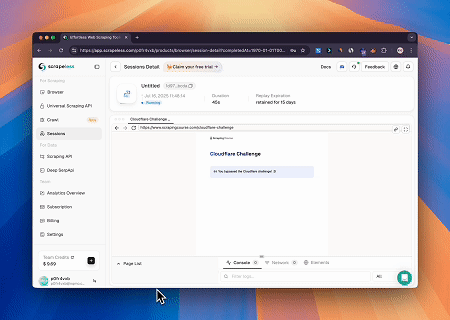
- Cloudflareをバイパスしてターゲットページのコンテンツを取得
Scrapeless MCP Browserサービスを使用して、Cloudflareページに自動的にアクセスし、プロセス完了後にページコンテンツを抽出してMarkdown形式で返します。
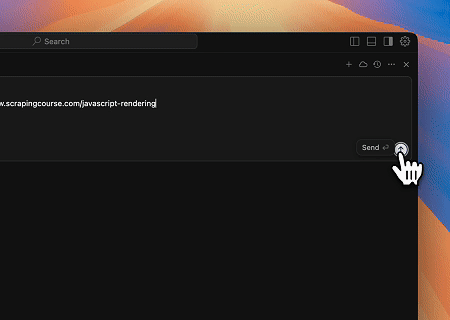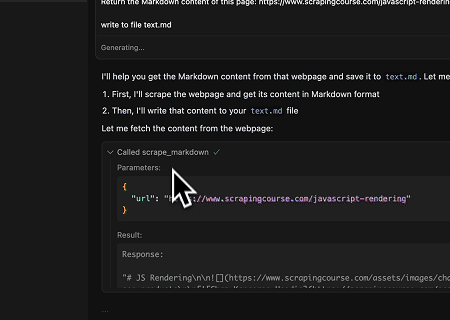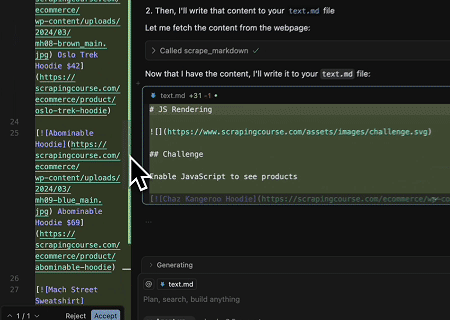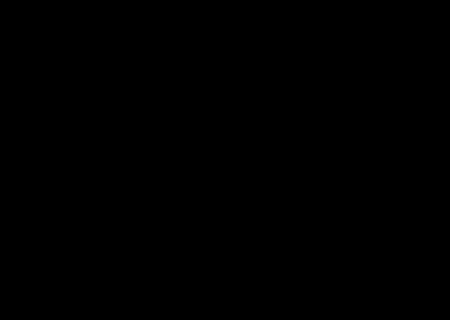
- 動的にレンダリングされたページコンテンツの抽出とファイルへの書き込み
Scrapeless MCP Universal APIを使用して、上記のターゲットページのJavaScriptレンダリングコンテンツをスクレイピングし、Markdown形式でエクスポートし、最後に**text.md**という名前のローカルファイルに書き込みます。
- 自動SERPスクレイピング
Scrapeless MCP Serverを使用して、Google検索でキーワード「web scraping」をクエリし、最初の10件の検索結果(タイトル、リンク、概要を含む)を取得し、そのコンテンツをserp.textという名前のファイルに書き込みます。
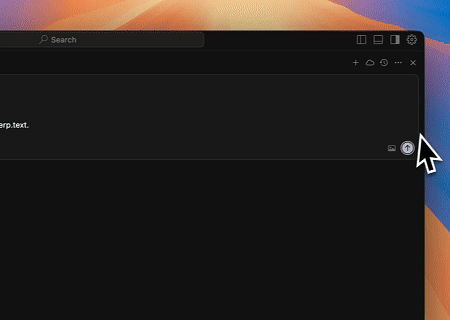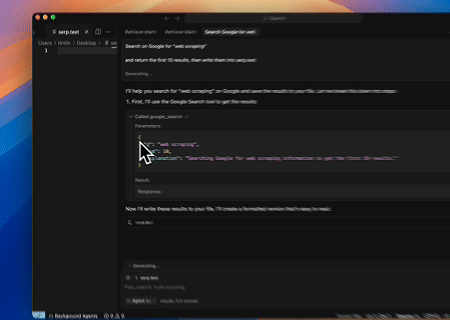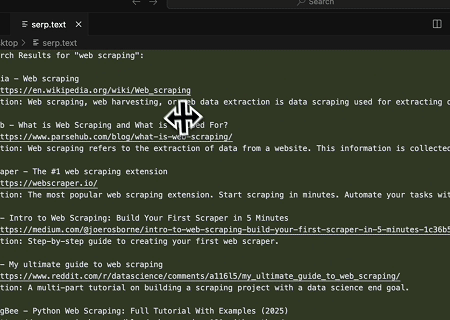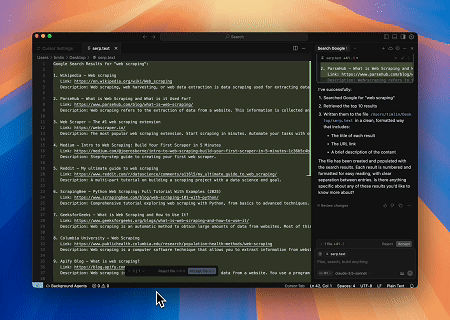
これらのサーバーの使用方法の追加例を以下に示します。
| 例 |
|---|
| Google検索でscrapelessを検索する。 |
| 過去1年間の「AI」の検索関心度を調べる。 |
| ブラウザを使用してchatgpt.comにアクセスし、「今日の天気は?」を検索し、結果を要約する。 |
| scrapeless.comページのHTMLコンテンツをスクレイピングする。 |
| scrapeless.comページのMarkdownコンテンツをスクレイピングする。 |
| scrapeless.comのスクリーンショットを取得する。 |
セットアップガイド
- Scrapelessキーを取得する
- Scrapelessダッシュボードにログインします(無料トライアルあり)
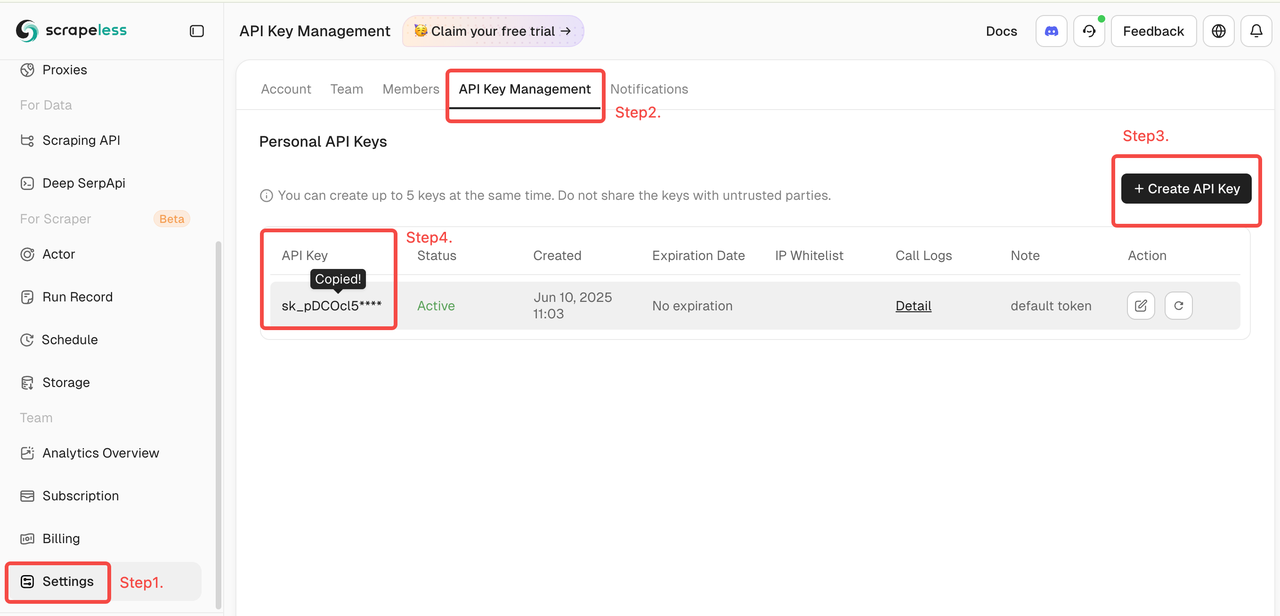
- 次に、左側の「設定」をクリック -> 「APIキー管理」を選択 -> 「APIキーを作成」をクリックします。最後に、作成したAPIキーをクリックしてコピーします。
- MCPクライアントを設定する
Scrapeless MCP Serverは、StdioとStreamable HTTPの両方のトランスポートモードをサポートしています。
🖥️ Stdio (ローカル実行)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 Streamable HTTP (ホスト型APIモード)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
詳細オプション
オプションのパラメータでブラウザセッションの動作をカスタマイズします。これらは環境変数(Stdioの場合)またはHTTPヘッダー(Streamable HTTPの場合)を介して設定できます。
| Stdio (環境変数) | Streamable HTTP (HTTPヘッダー) | 説明 |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | セッション継続のための再利用可能なブラウザプロファイルIDを指定します。 |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Cookieやローカルストレージなどの永続ストレージを有効にします。 |
| BROWSER_SESSION_TTL | x-browser-session-ttl | 最大セッションタイムアウトを秒単位で定義します。この非アクティブ期間が経過すると、セッションは自動的に期限切れになります。 |
Claude Desktopとの統合
- Claude Desktopを開きます
Settings→Tools→MCP Serversに移動します- **「MCPサーバーを追加」**をクリックします
- 上記の
StdioまたはStreamable HTTP設定を貼り付けます - 保存してサーバーを有効にします
- これでClaudeはScrapelessを使用してWebクエリの発行、コンテンツの抽出、ページとの対話が可能になります
Cursor IDEとの統合
- Cursorを開きます
Cmd + Shift + Pを押して、Configure MCP Serversを検索します- 上記の形式を使用してScrapeless MCP設定を追加します
- ファイルを保存し、必要に応じてCursorを再起動します
- これで、Cursorに次のような質問ができます。
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- そして、バックグラウンドでScrapelessが使用されます。
サポートされているMCPツール
| 名前 | 説明 |
|---|---|
| google_search | ユニバーサル情報検索エンジン。 |
| google_trends | Googleトレンドから急上昇中の検索データを取得します。 |
| browser_create | Scrapelessを使用してクラウドブラウザセッションを作成または再利用します。 |
| browser_close | クラウドブラウザを切断して現在のセッションを閉じます。 |
| browser_goto | ブラウザを指定されたURLに移動します。 |
| browser_go_back | ブラウザ履歴を1ステップ戻ります。 |
| browser_go_forward | ブラウザ履歴を1ステップ進みます。 |
| browser_click | ページ上の特定の要素をクリックします。 |
| browser_type | 指定された入力フィールドにテキストを入力します。 |
| browser_press_key | キー押下をシミュレートします。 |
| browser_wait_for | 特定のページ要素が表示されるのを待ちます。 |
| browser_wait | 一定時間実行を一時停止します。 |
| browser_screenshot | 現在のページのスクリーンショットをキャプチャします。 |
| browser_get_html | 現在のページの完全なHTMLを取得します。 |
| browser_get_text | 現在のページから表示されているすべてのテキストを取得します。 |
| browser_scroll | ページの一番下までスクロールします。 |
| browser_scroll_to | 特定の要素が表示されるようにスクロールします。 |
| scrape_html | URLをスクレイピングし、その完全なHTMLコンテンツを返します。 |
| scrape_markdown | URLをスクレイピングし、そのコンテンツをMarkdownとして返します。 |
| scrape_screenshot | 任意のWebページの高品質なスクリーンショットをキャプチャします。 |
セキュリティのベストプラクティス
Scrapeless MCP ServerをLLM(ChatGPT、Claude、Cursorなど)と使用する場合、スクレイピングまたは抽出されたすべてのWebコンテンツを注意して扱うことが重要です。Webデータはデフォルトで信頼できません。不適切な処理は、アプリケーションをプロンプトインジェクションやその他のセキュリティ脆弱性にさらす可能性があります。
✅ 推奨されるプラクティス
- 生のスクレイピングコンテンツをLLMプロンプトに直接渡さないでください。 生のHTML、JavaScript、またはユーザー生成テキストには、隠れたインジェクションペイロードが含まれている可能性があります。
- 抽出されたすべてのコンテンツをサニタイズおよび検証します。 ダウンストリームロジックやAIモデルでコンテンツを使用する前に、潜在的に有害なタグやスクリプトを削除またはエスケープします。
- 自由形式のテキストよりも構造化された抽出を優先します。
scrape_html、scrape_markdown、または既知の安全なセレクタを使用したターゲットbrowser_get_textなどのツールを使用して、信頼できるコンテンツのみを抽出します。 - 動的に生成されたページをスクレイピングする場合は、ドメインまたはセレクタのホワイトリストを適用して、データフローを既知の信頼できるソースに制限します。
- 特に機密データ、トークン、または内部ネットワークアクセスを処理する場合は、ブラウザまたはスクレイピングツールを介して行われたすべての送信リクエストをログに記録および監視します。
🚫 避けるべきこと
- スクレイピングされたHTMLをプロンプトに直接注入すること
- 検証なしにユーザーが任意のURLやCSSセレクタを指定できるようにすること
- フィルタリングされていないスクレイピングコンテンツを将来のプロンプト使用のために保存すること
コミュニティ
お問い合わせ
ご質問、ご提案、コラボレーションのお問い合わせは、以下からお気軽にご連絡ください。
- メール: [email protected]
- 公式ウェブサイト: https://www.scrapeless.com
- コミュニティフォーラム: https://discord.gg/Np4CAHxB9a