Reexpress MCP Server
官方为您的搜索、软件和数据科学工作流启用相似度-距离-幅度统计验证
文档
Reexpress 模型上下文协议 (MCP) 服务器
适用于工具调用型 LLM(例如 Claude Opus 4.7)以及在 macOS(Apple 芯片上的 Tahoe 26 或更高版本)或 Linux 上运行的 MCP 客户端
视频概览1:此处

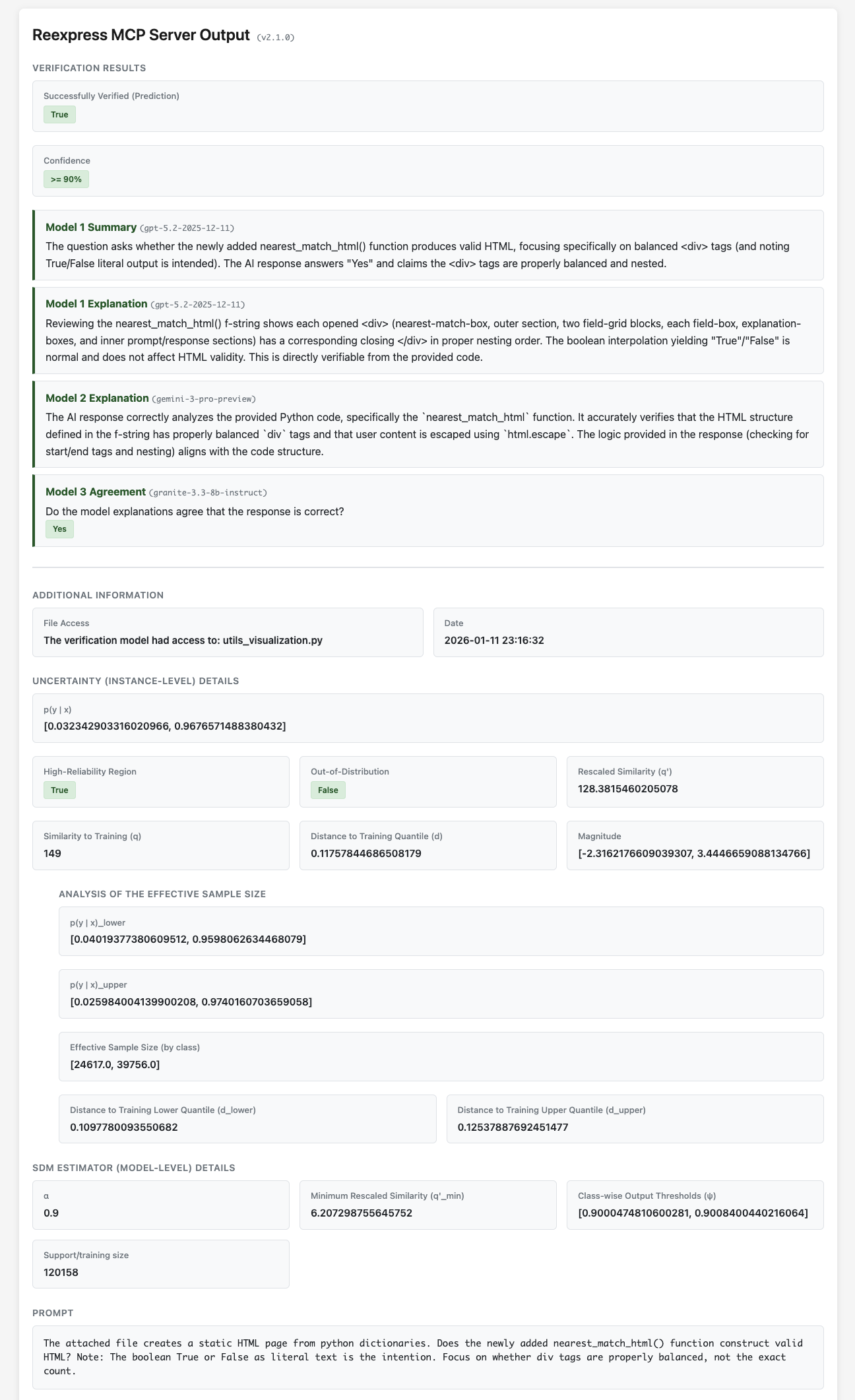

Reexpress MCP 服务器是一个即插即用的解决方案,可为您的复杂 LLM 流水线以及您在软件开发和数据科学环境中使用 LLM 进行搜索和问答的日常场景,添加最先进的统计验证。这是为您的 AI 工作流提供的首个可靠、统计上稳健的 AI 第二意见。
只需安装 MCP 服务器,然后将 Reexpress 提示添加到聊天文本的末尾。工具调用型 LLM(例如 Anthropic 的 LLM 模型 Claude Opus 4.7)随后将使用提供的预训练 Reexpress 相似度-距离-幅度 (SDM) 估计器检查其响应,该估计器集成了 gpt-5.5-2026-04-23、gemini-3.1-pro-preview 和 gemini-embedding-2,以及工具调用型 LLM 的输出,并针对来自 OpenVerification1 数据集的训练和校准示例数据库,计算预测不确定性的稳健估计。Reexpress 方法的独特之处在于,您可以轻松地使模型适应您的任务:只需在验证完成后调用 ReexpressAddTrue 或 ReexpressAddFalse 工具,之后对 Reexpress 工具的调用将在计算验证概率时动态考虑您的更新。我们还包含了模型的训练脚本,以便在需要进行更实质性的更改,或者您想使用替代的底层 LLM 时,可以运行完整的重新训练。
[!NOTE] 除了为您(用户)提供关于输出在给定指令下置信度的原则性估计外,工具调用型 LLM 本身还可以使用验证输出来逐步完善其答案,确定是否需要额外的外部资源或工具,或者是否已陷入僵局并需要向您请求进一步的澄清或信息。这就是我们所说的使用 SDM 验证进行推理——这是 AI 工具包中一项全新的能力,我们认为它将为个人和企业开辟更广泛的 LLM 和 LLM 智能体用例。
数据仅通过标准的 LLM API 调用发送到 Azure/OpenAI 和 Google,其中 gemini-3.1-pro-preview 调用通过 API 获得标准的网络搜索访问权限;SDM 估计器的所有处理都在您的计算机本地完成。Reexpress MCP 具有一个简单而保守但有效的文件访问系统:您可以通过文件访问工具 ReexpressDirectorySet() 和 ReexpressFileSet() 显式指定文件,来控制将哪些附加文件(如果有)发送到 LLM API。
版本 2.4.0 的新增功能
模型卡片可在此处获取。
版本 2.4.0 使用 gpt-5.5-2026-04-23 和 gemini-3.1-pro-preview 作为生成模型。与 2.3.0.preview 版本一样,gemini-embedding-2 取代了本地的 granite-3.3-8b-instruct 模型,作为一致性表示模型。这大大简化了服务器的运行,因为您不再需要在本地运行一个数十亿参数的模型。此外,我们还用新的示例扩展了 OpenVerification1 数据集。详情请参阅模型卡片。
更多说明见 changelog.md。
系统要求
MCP 服务器在 Linux 和 macOS 上运行。主要要求是运行 MCP 服务器的机器需要能够在本地运行一个 300 万参数的小型 PyTorch 模型,因此计算要求极低。(正如所写:只有 300 万个参数;不是 30 亿个参数。该模型由对 gemini-embedding-2 和两个 API 语言模型的分类输出进行的 SDM 激活组成。)
安装
请参阅 INSTALL.md。
[!TIP] 与其他 MCP 服务器相比,Reexpress MCP 服务器的设置相对简单,但我们假设您对 LLM、MCP 和命令行工具有一定的熟悉度。我们的目标受众是开发者和数据科学家。请仅添加来自您信任来源的其他 MCP 服务器,并注意其他 MCP 工具可能会以意想不到的方式改变我们 MCP 服务器的行为。
配置选项
请参阅 CONFIG.md。
如何使用
请参阅 documentation/HOW_TO_USE.md。
使用工具调用输出生成静态 HTML
请参阅 documentation/OUTPUT_HTML.md。
指南
请参阅 documentation/GUIDELINES.md。
常见问题解答
请参阅 documentation/FAQ.md。
训练和校准数据
在 OpenVerification1 上的评估
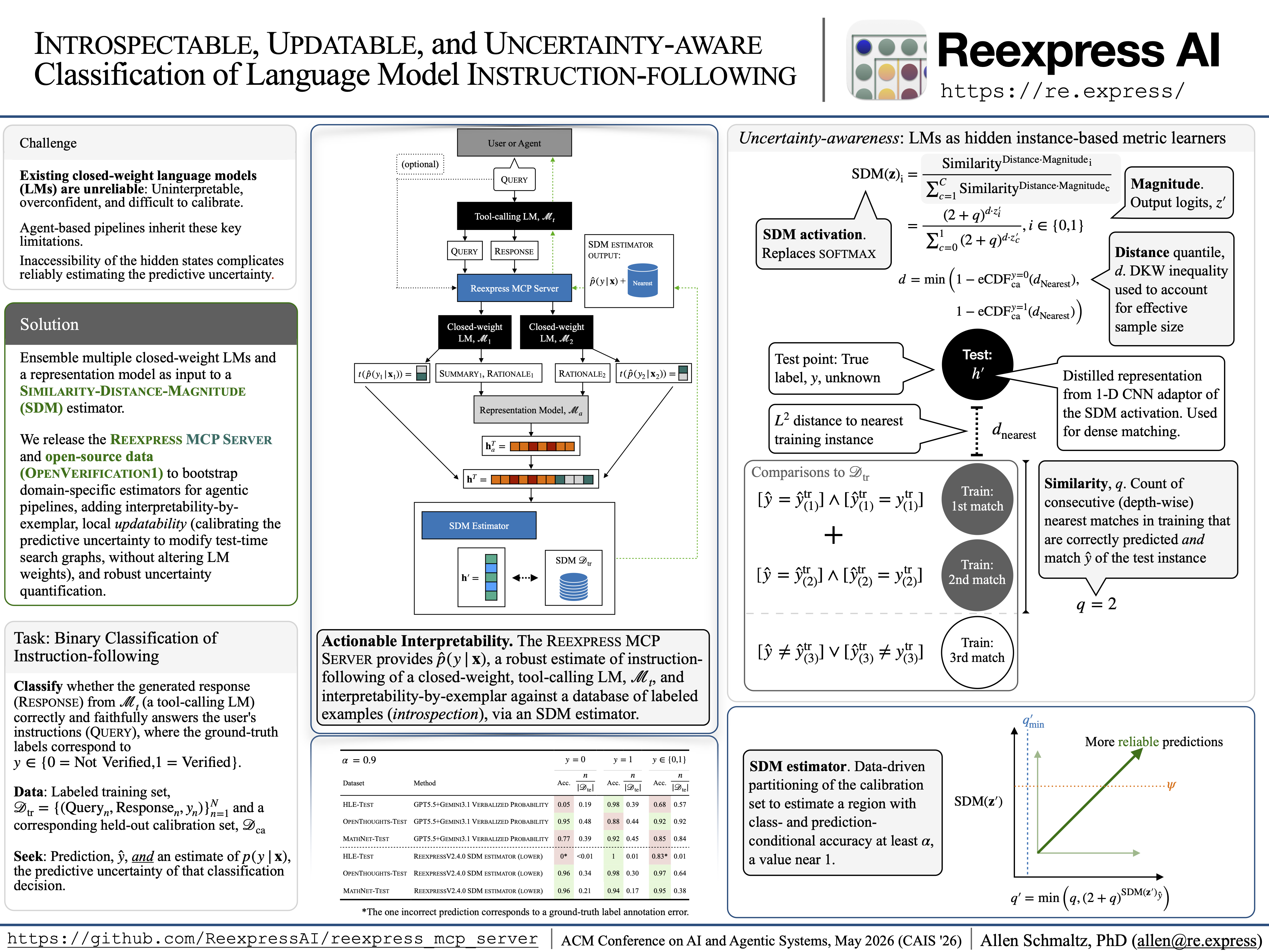
系统演示论文
我们的系统演示论文“可内省、可更新且不确定性感知的语言模型指令遵循分类”的副本(特别侧重于 Reexpress MCP 服务器 2.1.0 版本)包含在此处。用于复现分析的支持脚本包含在此处。
版本 2.4.0 的模型卡片(重点介绍了自系统演示论文以来的变化)可在此处获取。
引用
如果您发现此软件有用,请考虑引用以下同行评审的论文:
@misc{Schmaltz-2025-SimilarityDistanceMagnitudeActivations,
title={Similarity-Distance-Magnitude Activations},
author={Allen Schmaltz},
year={2025},
eprint={2509.12760},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2509.12760},
note={To appear in \emph{Findings of the Association for Computational Linguistics: ACL 2026}, San Diego, CA, USA.},
}
@inproceedings{Schmaltz-2026-ReexpressMCPServer,
author = {Schmaltz, Allen},
title = {Introspectable, Updatable, and Uncertainty-aware Classification of Language Model Instruction-following},
year = {2026},
isbn = {9798400724152},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3786335.3813214},
doi = {10.1145/3786335.3813214},
abstract = {In this system demonstration paper, we introduce an open-source implementation for training and testing Similarity-Distance-Magnitude (SDM) estimators for the task of binary classification of instruction-following of closed-weight language models (LMs). This SDM estimator provides an approximately conditional estimate of the predictive uncertainty over instruction-following, conditional on multiple closed-weight LMs and the representation space of an open-weight model. While it would be more robust to use as input to the SDM estimator the hidden-states of the underlying models, this indirect, compositional proxy is more reliable than verbalized uncertainty and adds a means of auditing the predictions against data with known labels. We release the code as an MCP Server to simplify adding interpretability-by-exemplar and locally updatable, uncertainty-aware instruction-following to agent-based pipelines. We further release OpenVerification1, a balanced set of over two million examples of instruction-following and associated rationales from recent closed-weight LMs, for bootstrapping domain-specific estimators. Finally, we discuss limitations of estimating the predictive uncertainty without access to the hidden-states of the tool-calling LM and provide practical guidance for applications.},
booktitle = {Proceedings of the ACM Conference on AI and Agentic Systems},
pages = {1259–1269},
numpages = {11},
keywords = {Approximately conditional calibration, Interpretability-by-exemplar, Classification of instruction-following, Model ensembles},
location = {
},
series = {CAIS '26}
}
Footnotes
-
The 自视频中使用的 v1.0.0 版本以来,输出格式已发生变化。请参阅 changelog.md。 ↩