Scrapeless MCP Server
resmiGerçek zamanlı Scrapeless Google SERP (Google Arama, Google Uçuş, Google Harita, Google İşler...) sonuçlarını LLM uygulamalarınıza entegre edin. Bu sunucu, AI iş akışları, sohbet robotları ve araştırma araçları için dinamik bağlam alımını sağlar.
Dokümantasyon

Scrapeless MCP Sunucusu
Resmi Scrapeless Model Bağlam Protokolü (MCP) Sunucusuna hoş geldiniz — Yapay zeka modellerinin, yapay zeka ajanlarının ve yapay zeka uygulamalarının web ile gerçek zamanlı etkileşim kurmasını sağlayan güçlü bir entegrasyon katmanı.
Açık MCP standardı üzerine inşa edilen Scrapeless MCP Sunucusu, ChatGPT, Claude gibi modelleri ve Cursor, Windsurf gibi araçları aşağıdakiler de dahil olmak üzere çok çeşitli harici yeteneklere sorunsuz bir şekilde bağlar:
- Google hizmetleri entegrasyonu (Arama, Trendler)
- Sayfa düzeyinde gezinme ve etkileşim için tarayıcı otomasyonu
- Dinamik, JS ağırlıklı siteleri kazıma—HTML, Markdown veya ekran görüntüsü olarak dışa aktarma
İster bir yapay zeka araştırma asistanı, ister bir kodlama yardımcı pilotu veya otonom web ajanları geliştiriyor olun, bu sunucu iş akışlarınızın ihtiyaç duyduğu dinamik bağlamı ve gerçek dünya verilerini engellenmeden sağlar.
Kullanım Örnekleri
- Claude ile Otomatik Web Etkileşimi ve Veri Çıkarma
Scrapeless MCP Tarayıcı'yı kullanarak Claude, web'de gezinme, tıklama, kaydırma ve kazıma gibi karmaşık görevleri konuşma komutlarıyla gerçekleştirebilir ve web etkileşim sonuçlarının gerçek zamanlı önizlemesini live sessions aracılığıyla görebilir.
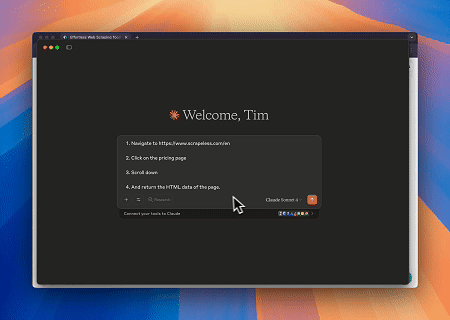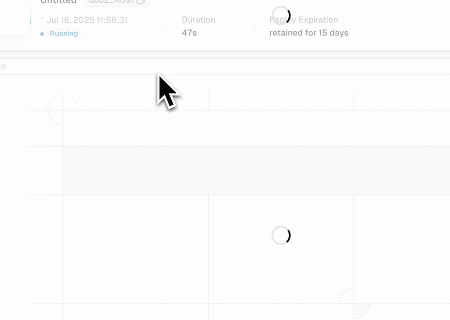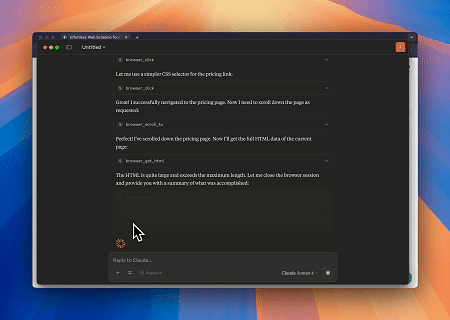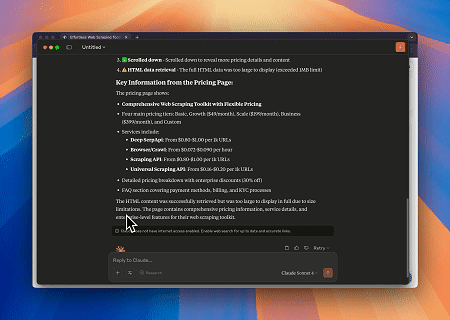
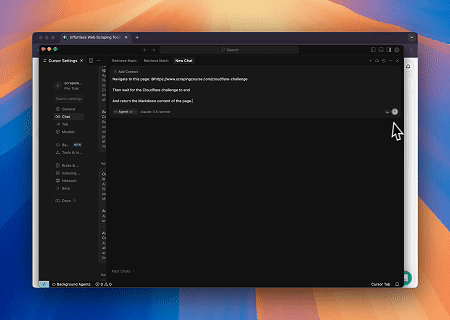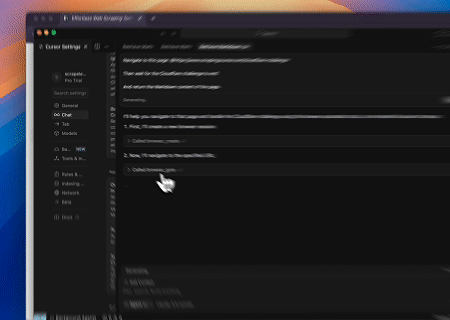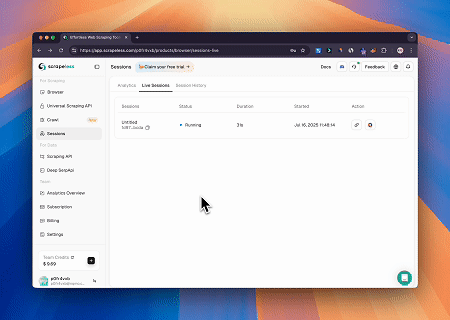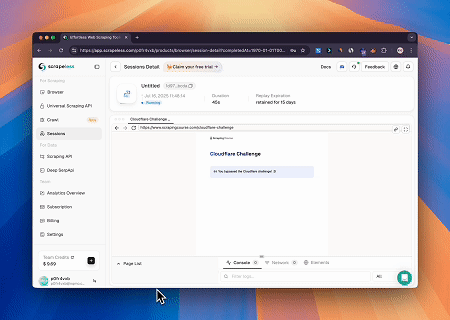
- Hedef Sayfa İçeriğini Almak için Cloudflare'ı Atlama
Scrapeless MCP Tarayıcı hizmeti kullanılarak Cloudflare sayfasına otomatik olarak erişilir ve işlem tamamlandıktan sonra sayfa içeriği çıkarılır ve Markdown formatında döndürülür.
- Dinamik Olarak Oluşturulan Sayfa İçeriğini Çıkarma ve Dosyaya Yazma
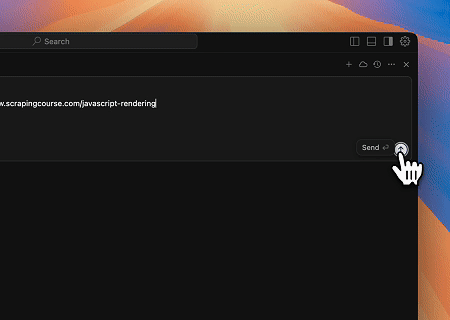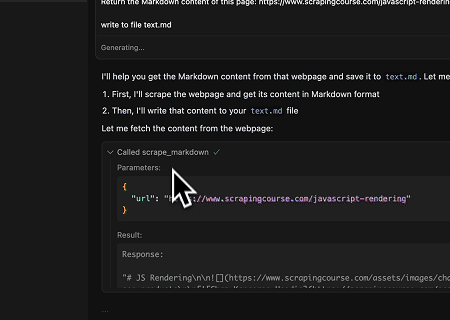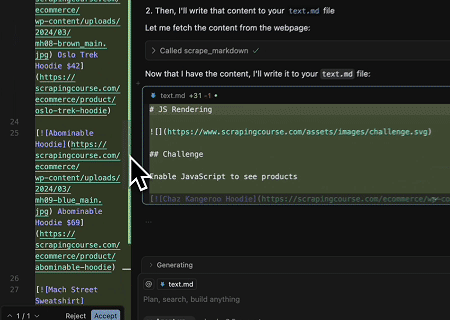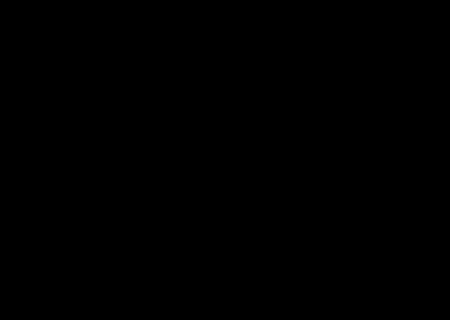
Scrapeless MCP Evrensel API'si kullanılarak yukarıdaki hedef sayfanın JavaScript ile oluşturulan içeriği kazınır, Markdown formatında dışa aktarılır ve son olarak text.md adlı yerel bir dosyaya yazılır.
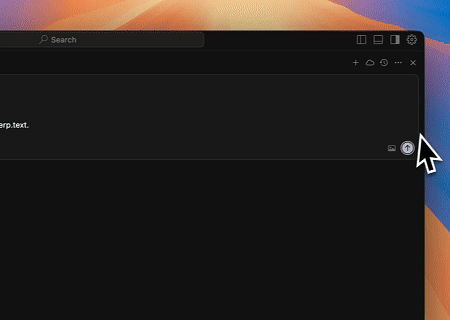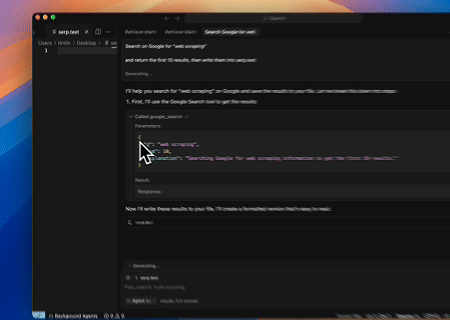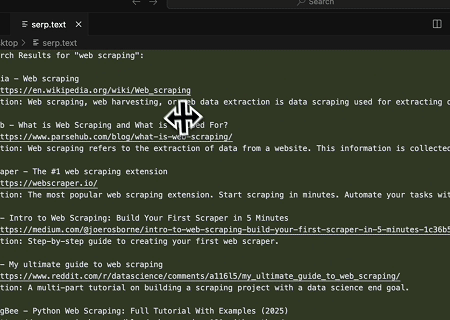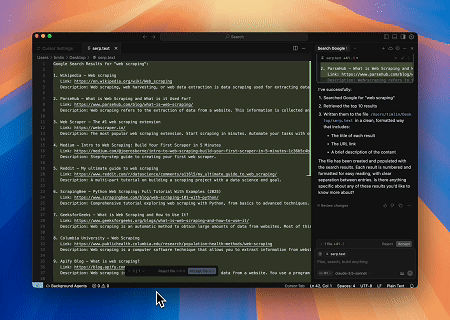
- Otomatik SERP Kazıma
Scrapeless MCP Sunucusu kullanılarak Google Arama'da "web scraping" anahtar kelimesi sorgulanır, ilk 10 arama sonucu (başlık, bağlantı ve özet dahil) alınır ve içerik serp.text adlı dosyaya yazılır.
Bu sunucuların nasıl kullanılacağına dair bazı ek örnekler aşağıda verilmiştir:
| Örnek |
|---|
| Google araması ile scrapeless'ı ara. |
| Geçen yıl boyunca "AI" için arama ilgisini bul. |
| chatgpt.com adresini ziyaret etmek, "Bugün hava nasıl?" diye sormak ve sonuçları özetlemek için bir tarayıcı kullan. |
| scrapeless.com sayfasının HTML içeriğini kazı. |
| scrapeless.com sayfasının Markdown içeriğini kazı. |
| scrapeless.com ekran görüntülerini al. |
Kurulum Kılavuzu
- Scrapeless Anahtarı Edinin
- Scrapeless Kontrol Paneline giriş yapın (Ücretsiz deneme mevcuttur)
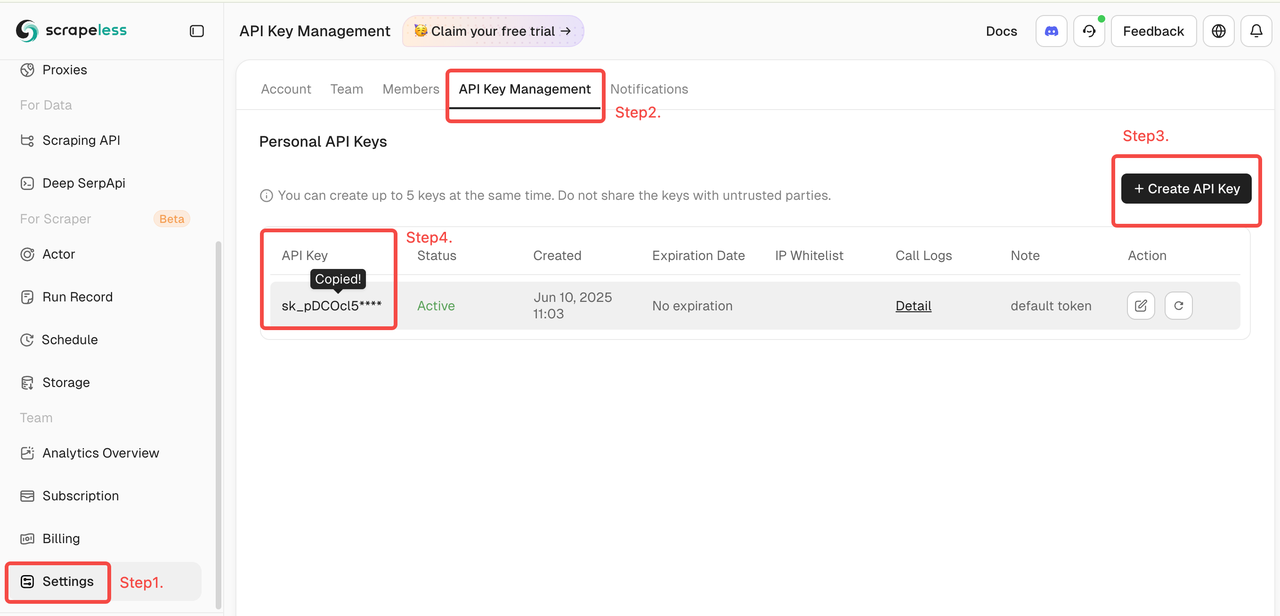
- Ardından soldan "Ayarlar"a tıklayın -> "API Anahtar Yönetimi"ni seçin -> "API Anahtarı Oluştur"a tıklayın. Son olarak, oluşturduğunuz API Anahtarına tıklayarak kopyalayın.
- MCP İstemcinizi Yapılandırın
Scrapeless MCP Sunucusu hem Stdio hem de Akışlı HTTP aktarım modlarını destekler.
🖥️ Stdio (Yerel Yürütme)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 Akışlı HTTP (Barındırılan API Modu)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
Gelişmiş Seçenekler
İsteğe bağlı parametrelerle tarayıcı oturum davranışını özelleştirin. Bunlar ortam değişkenleri (Stdio için) veya HTTP başlıkları (Akışlı HTTP için) aracılığıyla ayarlanabilir:
| Stdio (Ortam Değişkeni) | Akışlı HTTP (HTTP Başlığı) | Açıklama |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | Oturum sürekliliği için yeniden kullanılabilir bir tarayıcı profili kimliği belirtir. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Çerezler, yerel depolama vb. için kalıcı depolamayı etkinleştirir. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | Saniye cinsinden maksimum oturum zaman aşımını tanımlar. Oturum, bu hareketsizlik süresinden sonra otomatik olarak sona erer. |
Claude Desktop ile Entegrasyon
- Claude Desktop'ı açın
- Şuraya gidin:
Settings→Tools→MCP Servers - **"MCP Sunucusu Ekle"**ye tıklayın
- Yukarıdaki
StdioveyaStreamable HTTPyapılandırmasını yapıştırın - Kaydedin ve sunucuyu etkinleştirin
- Claude artık Scrapeless kullanarak web sorguları yapabilecek, içerik çıkarabilecek ve sayfalarla etkileşim kurabilecek
Cursor IDE ile Entegrasyon
- Cursor'ı açın
Cmd + Shift + Ptuşlarına basın ve şunu arayın:Configure MCP Servers- Yukarıdaki formatı kullanarak Scrapeless MCP yapılandırmasını ekleyin
- Dosyayı kaydedin ve Cursor'ı yeniden başlatın (gerekirse)
- Artık Cursor'a şunun gibi şeyler sorabilirsiniz:
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- Ve arka planda Scrapeless'ı kullanacaktır.
Desteklenen MCP Araçları
| Ad | Açıklama |
|---|---|
| google_search | Evrensel bilgi arama motoru. |
| google_trends | Google Trends'ten trend olan arama verilerini alın. |
| browser_create | Scrapeless kullanarak bir bulut tarayıcı oturumu oluşturun veya yeniden kullanın. |
| browser_close | Bulut tarayıcının bağlantısını keserek mevcut oturumu kapatır. |
| browser_goto | Tarayıcıyı belirtilen bir URL'ye yönlendirin. |
| browser_go_back | Tarayıcı geçmişinde bir adım geri gidin. |
| browser_go_forward | Tarayıcı geçmişinde bir adım ileri gidin. |
| browser_click | Sayfadaki belirli bir öğeye tıklayın. |
| browser_type | Belirtilen bir giriş alanına metin yazın. |
| browser_press_key | Bir tuşa basmayı simüle edin. |
| browser_wait_for | Belirli bir sayfa öğesinin görünmesini bekleyin. |
| browser_wait | Yürütmeyi sabit bir süre duraklatın. |
| browser_screenshot | Mevcut sayfanın ekran görüntüsünü yakalayın. |
| browser_get_html | Mevcut sayfanın tam HTML'ini alın. |
| browser_get_text | Mevcut sayfadaki tüm görünür metni alın. |
| browser_scroll | Sayfanın en altına kaydırın. |
| browser_scroll_to | Belirli bir öğeyi görünüme kaydırın. |
| scrape_html | Bir URL'yi kazıyın ve tam HTML içeriğini döndürün. |
| scrape_markdown | Bir URL'yi kazıyın ve içeriğini Markdown olarak döndürün. |
| scrape_screenshot | Herhangi bir web sayfasının yüksek kaliteli ekran görüntüsünü yakalayın. |
Güvenlik En İyi Uygulamaları
Scrapeless MCP Sunucusunu YZ modelleriyle (ChatGPT, Claude veya Cursor gibi) kullanırken, kazınan veya çıkarılan tüm web içeriğini dikkatle ele almak kritik önem taşır. Web verileri varsayılan olarak güvenilmezdir ve uygunsuz kullanım, uygulamanızı istem enjeksiyonuna veya diğer güvenlik açıklarına maruz bırakabilir.
✅ Önerilen Uygulamalar
- Ham kazınmış içeriği asla doğrudan YZ istemlerine aktarmayın. Ham HTML, JavaScript veya kullanıcı tarafından oluşturulan metin, gizli enjeksiyon yükleri içerebilir.
- Çıkarılan tüm içeriği sterilize edin ve doğrulayın. İçeriği sonraki mantıkta veya yapay zeka modellerinde kullanmadan önce potansiyel olarak zararlı etiketleri ve betikleri temizleyin veya kaçış karakterleri ekleyin.
- Serbest biçimli metin yerine yapılandırılmış çıkarmayı tercih edin. Yalnızca güvendiğiniz içeriği çıkarmak için bilinen güvenli seçicilerle
scrape_html,scrape_markdownveya hedeflenmişbrowser_get_textgibi araçları kullanın. - Dinamik olarak oluşturulan sayfaları kazırken, veri akışını bilinen ve güvenilen kaynaklarla kısıtlamak için alan adı veya seçici beyaz listesi uygulayın.
- Özellikle hassas veriler, belirteçler veya dahili ağ erişimiyle uğraşıyorsanız, tarayıcı veya kazıma araçları aracılığıyla yapılan tüm giden istekleri günlüğe kaydedin ve izleyin.
🚫 Kaçının
- Kazınmış HTML'i doğrudan istemlere enjekte etmek
- Kullanıcıların doğrulama olmadan rastgele URL'ler veya CSS seçicileri belirtmesine izin vermek
- Gelecekteki istem kullanımı için filtrelenmemiş kazınmış içeriği depolamak
Topluluk
Bize Ulaşın
Sorularınız, önerileriniz veya iş birliği talepleriniz için bizimle şu yollarla iletişime geçmekten çekinmeyin:
- E-posta: [email protected]
- Resmi Web Sitesi: https://www.scrapeless.com
- Topluluk Forumu: https://discord.gg/Np4CAHxB9a