Unerr MCP Server
unerr is operational memory—a local runtime behind your agent's MCP enforcing shared code graphs, session memory & guardrails.
Documentation
Your AI agent has read your codebase. It still can't safely change it.
Every tool built to help hands your agent advice it can ignore — a memory it has to remember to check,
a graph it has to choose to query, a reviewer that only speaks up after the break is already written.
unerr is the guardrail it can't skip. The moment your agent edits a function, unerr puts the live call graph
and the rule you pinned to that exact function into the edit itself — automatically, not on request — and re-anchors
that rule when the code moves, so it never goes quietly stale. The 24 callers and the standard it's about to break are
on screen before the function changes. Every time. Whether or not the agent thought to ask.
Works with Cursor · Claude Code · Windsurf · Gemini CLI · Antigravity · GitHub Copilot CLI · and every MCP-compatible client.
npm install -g @unerr-ai/unerr
Zero configuration. Install, restart your IDE, and the next prompt already knows your repo.
Contents
The gap nobody else closes
On a small or greenfield project the agent holds the whole repo in its head and reading the live code is enough — you don't need us. The wall is the large, existing, multi-contributor codebase, and it's the same wall every time: the agent can't fit the whole thing in context, so it acts on the slice it can see and never reads the rest. It changes a signature and breaks 7 of 24 callers it never read. It writes a fourth copy of a pattern your team standardized months ago — even with the rule spelled out in .cursorrules. Neither shows up as an error. They show up as a senior engineer's afternoon.
The knowledge that would have stopped it — who calls this function, which pattern is load-bearing — already exists. The whole market is built on getting that knowledge to the agent. And it falls into two shapes, both of which leak:
| What it does | The shape | Why it leaks |
|---|---|---|
| Tells the agent things. Memory stores, code-graph servers, context packers, rule files. | A tool the agent calls when it remembers to. | Optional context is optional. Agents skip the retrieval tool ~58% of the time even when explicitly told to use it (CodeCompass, 2026). Advice it can ignore, it ignores. |
| Checks the agent afterward. Reviewers, linters, CI gates. | A pass over the diff after the code is written. | The break already happened. Now it's a comment on a pull request and a second round of work — not a change that never broke anything. |
There's a third shape, and almost no one ships it: guidance wired into the moment of the edit, that the agent can't route around, and that re-anchors itself when the code moves so it never goes quietly stale. Not a tool it chooses to consult. Not a review after the fact. A guardrail that fires as it edits — and stays true to the code because it's recomputed from the code, not from a doc that rots.
That's unerr. The agent doesn't have to ask. Before the edit lands, it already sees the callers it would break and the standard it's about to violate.
| The old way | With unerr |
|---|---|
| The agent changes a function without reading its 24 callers — 7 sites break silently. | Cascade guard puts the call graph in front of the edit before it runs — every caller on screen, no asking required. |
You wrote the rule in .cursorrules. The agent acknowledged it, then ignored it once context filled up. | Anchored rules surface the standard the instant the agent touches that scope — and re-anchor when the code moves instead of going stale. |
| A rule or spec stays confident long after the code moved out from under it. Nothing recomputes it. | Every fact is pinned to a live entity in the graph. When the code moves, the fact fails loud instead of staying silently wrong. |
The pains this fixes
You know this feeling, and it gets worse as the repo grows, not better:
- You're babysitting it. You can't fire-and-forget, because the one time you look away is the time it quietly breaks something load-bearing. You've become its scheduler and its safety net at once.
- You don't trust it to touch anything important. It treats your codebase as a flat wall of text — locally correct, globally wrong — so the load-bearing changes still land on you.
- The rule you wrote gets acknowledged, then dropped. A few turns later the context fills up and your
.cursorrulesline may as well not exist. - Approval fatigue. You approve so many reasonable edits that the dangerous one slides through — the hundredth confirmation looks exactly like the first.
These aren't four problems. They're one: the agent acts on a codebase it can't hold in its head, and nothing it can't bypass is watching the change. You babysit because there's no guardrail it can't skip. unerr is that guardrail — so you can look away.
What changes when you install it
| You feel | What unerr does |
|---|---|
| You stop babysitting. The agent runs for an hour and you're not bracing for a silent break. | Every edit is preceded — automatically — by a graph lookup. All 24 callers are visible before it touches the function. The guardrail fires whether or not the agent thought to ask. |
| Your rules finally get honored. The standard you set is applied at the edit, not acknowledged and forgotten. | unerr pins each rule and decision to the file or entity it governs and surfaces it the instant the agent touches that scope — then re-anchors it when the code moves. Keep your .cursorrules and specs; unerr makes sure they're actually applied. |
| It stops thrashing. No more watching it retry the same broken fix three times. | A loop breaker watches the timeline and stops the agent re-trying a change that already failed twice — before it burns your turn and your patience. |
| The agent stays sharp at turn 50. | file_read({entity}) returns 200 lines instead of 3,000; shell output is trimmed automatically. The window stays uncluttered, so the model isn't fighting "lost in the middle." |
What it looks like in your chat — before the Edit tool runs, unerr injects this into the agent's context, on its own:
⚡ unerr · cascade guard: editing
src/payments/gateway.tschanges a signature with callers that must be updated in the same change —processPayment: 24 callers at risk across 6 files (19 source, 5 test). Callget_references({key:'processPayment', direction:'callers'})and update every caller before finishing.
The outcome: agents that behave like senior engineers — checking dependencies before editing, honoring the standard, and refusing to thrash on a function they've already failed on three times.
See it in action
Watch it run — a real Claude Code session in this repo. The agent attempts a signature change to extractFilePath; before the edit lands, unerr surfaces 12 callers at risk across 4 files, so the agent updates every one of them in the same turn instead of breaking them silently.
Cascade guard, live · unerr catches the 12 callers of extractFilePath before the edit ripples. ▶ Watch the full demo on YouTube.
Two places unerr shows up so you know it's working — inside the chat, and in a browser.
Inside the chat. Every coding turn opens with one line naming what unerr loaded ("loaded a convention you wrote yesterday for src/payments/gateway.ts…") and closes with one line totalling what it caught and saved ("this turn: 2 catches · ≈ 4.2k tokens saved · +5 turns of headroom this session"). Catches are named, countable events, not a ratio.
In a browser. A live dashboard at http://localhost:9847 reads from the same store the agent reads from over MCP — the graph it navigates, the facts it remembers, the breaks it caught, and the score showing which of those facts actually shaped the next answer.
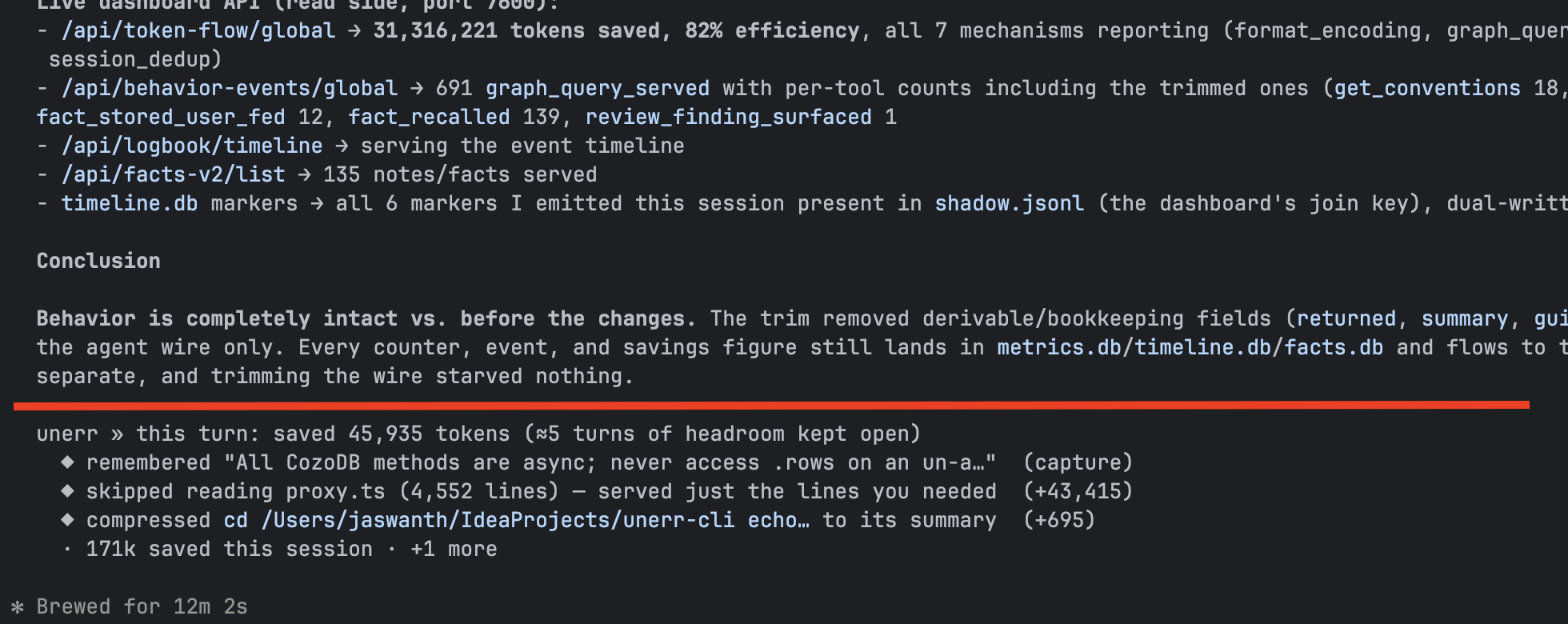
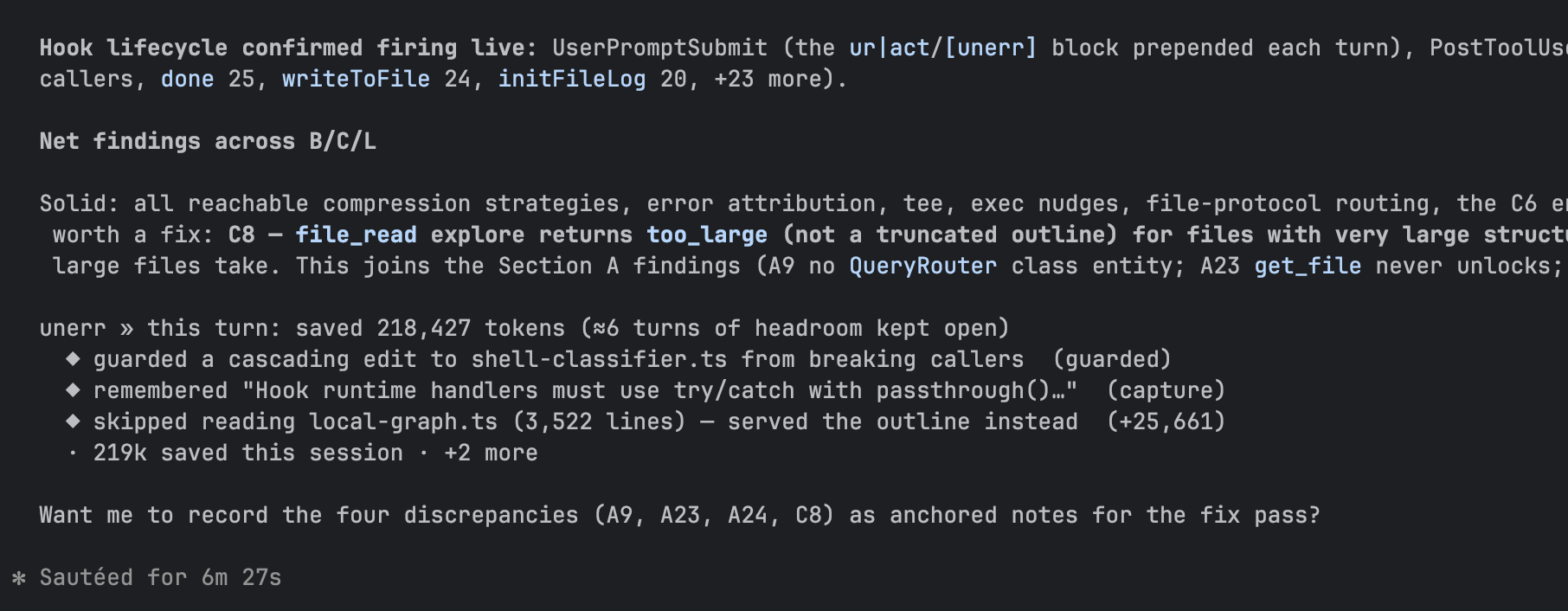
End-of-turn receipt · every coding turn closes with one line totalling what unerr caught and saved you — named, countable catches, not a ratio.
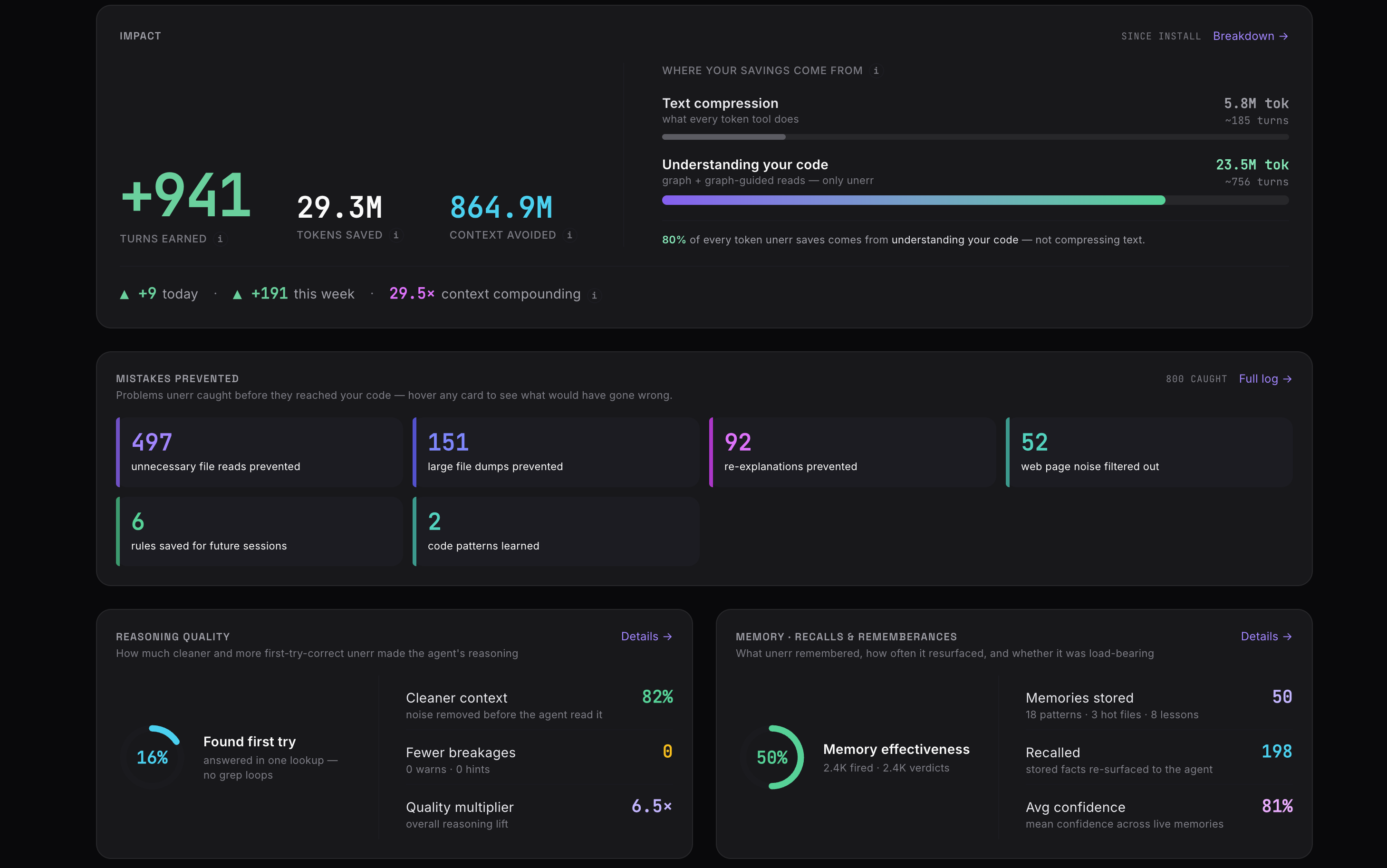
Dashboard · live overview — active sessions, recent tool calls, breaks caught, tokens the agent skipped this turn.
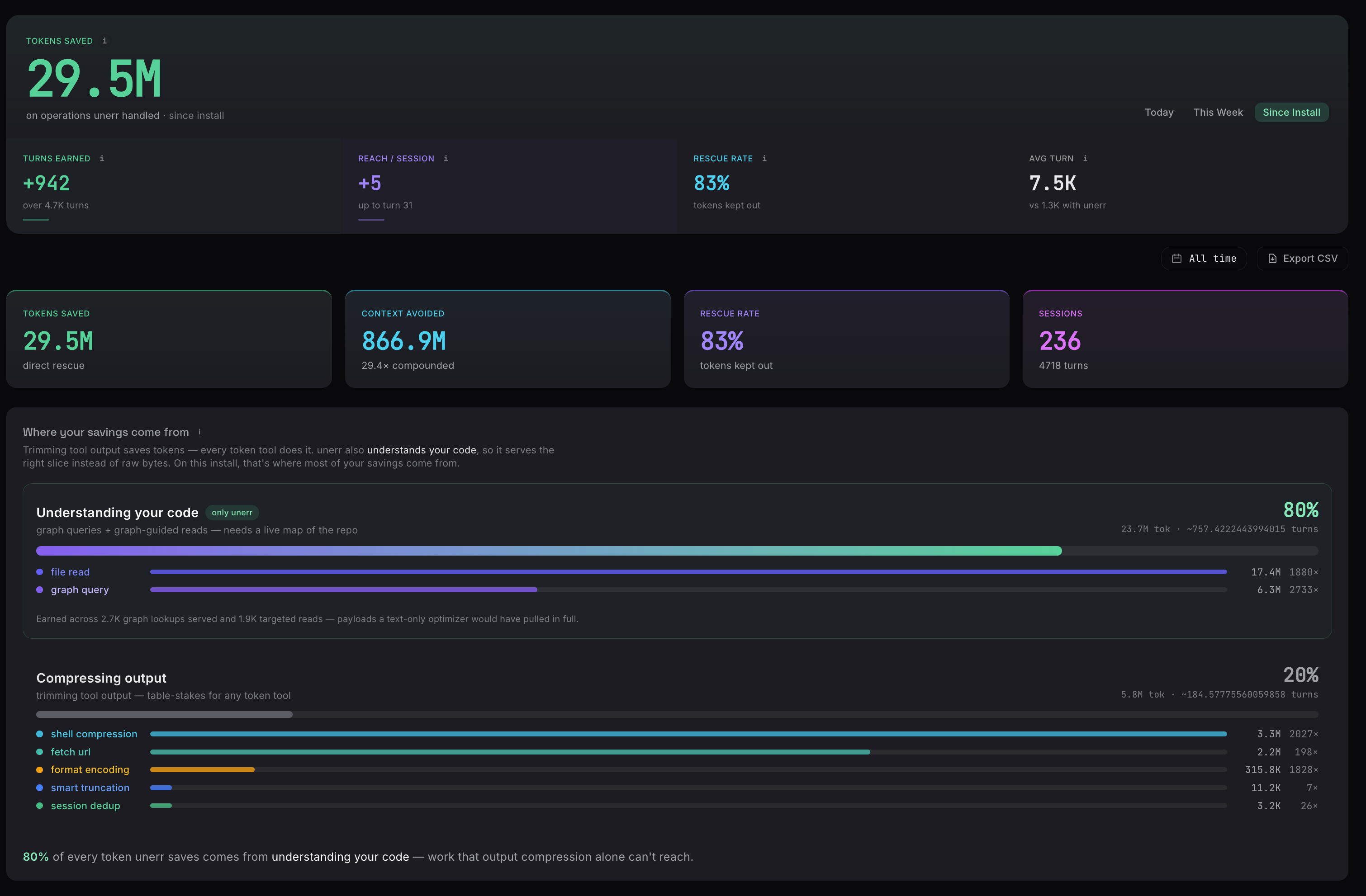
Token Trace · context kept out of the window, broken down by mechanism — graph hits, skipped re-reads, compressed shell output, deduped fetches.
More views in the full dashboard tour.
Quick Start
Three steps. Step 1 is once per machine; steps 2–3 are per repo.
1. Install the CLI
npm install -g @unerr-ai/unerr
Puts the unerr binary on your PATH. If your shell can't find it (common with nvm, fnm, volta, pnpm), run unerr doctor once — it patches your shell config and won't need to run again.
2. Install for your agent (per repo)
cd ~/your-project
unerr install cursor
Writes the MCP config, skills, hooks, and instructions for that agent in the current repo. Swap cursor for any of the supported agents:
unerr install claude-code
unerr install cursor
unerr install antigravity
unerr install windsurf
unerr install gemini-cli
unerr install github-copilot-cli
Install multiple agents in the same repo — each writes its own config. Idempotent: re-running updates if content changed, skips if identical. Remove with unerr uninstall.
3. Restart your IDE
Close and reopen your IDE (or start a new chat session). Your agent picks up unerr through MCP — graph-backed tools, persistent memory, the edit-time guardrail all available immediately.
Dashboard: http://localhost:9847 — open any time to watch unerr at work in real time.
Need manual setup or any other MCP client?
unerr install --show-instructions <agent>prints copy-pasteable steps.
Who it's for
- Engineers on large, existing codebases. The dependency graph, the load-bearing patterns, and the prior incidents a senior engineer carries in their head — handed to the agent before every edit, so it stops breaking callers it never read.
- Teams with conventions worth enforcing. The standard you agreed on once, applied every time the agent touches that scope — no
.cursorrulesfile to hand-maintain, re-paste, or merge-conflict over, and no hoping the agent remembers to look. - Solo builders shipping into a codebase that's already grown. The continuous thread across tools — switch from Claude Code in the terminal to Cursor in the IDE and the graph, rules, and history come with you, instead of relearning the repo every session.
Why a guardrail has to be one runtime, not five tools
A guardrail the agent can't skip can't be a tool the agent chooses to call. That's the whole reason unerr is one local runtime sitting behind the MCP every agent already speaks — not a fifth server in the agent's tool list.
Every coding agent on your machine — Claude Code, Cursor, Windsurf, Antigravity — speaks MCP. MCP carries tool calls; it does not carry context, and it does not fire anything on its own. So a memory server, a graph server, and a compressor sit there waiting to be invoked — and an agent under context pressure skips them. unerr instead intercepts at the moment that matters — the read, the edit — and injects the one scoped thing that's relevant, automatically. The agent can't forget to call something that isn't waiting to be called.
That only works if the pieces live in one process. The guardrails worth having each fire on a join no single tool can make:
- Cascade guard needs the call graph and the edit-intent ledger on the same process, at the same instant.
- Drift needs memory that's anchored to a live graph — so the fact knows the moment its code moved.
- Convention drift needs the auto-detected pattern store and the new-code stream in the same memory space.
- Loop breaker needs the full timeline of what the agent already tried.
These aren't features you can buy individually and bolt together. They're emergent properties of one runtime — and they're exactly what turns "context the agent might read" into "a guardrail it can't skip."
How the runtime works
One local process per repo. Four mechanisms, joined deterministically — the mechanisms are how; the guardrail is what you get.
| Mechanism (the how) | What's inside | What it powers (the what) |
|---|---|---|
| Live code graph | CozoDB · tree-sitter ASTs · SCIP-verified call graphs · 18+ languages · <5ms queries | The agent opens 50 targeted lines and a caller list — not 3,000 lines and a guess. Read before every file read, so cascade guard knows what an edit breaks. |
| Anchored memory | Typed facts · conventions auto-detected at ≥70% adherence · decay-adjusted confidence | Every fact is pinned to a file or entity in the graph. When the code moves, the fact gets a drift signal — never silent staleness. |
| Context delivery | Shell output compression (645+ command classifiers) · web fetches (5–10× via Defuddle + BM25) · entity-targeted file reads | The relevant slice arrives automatically at the read — the agent never has to remember which tool to invoke for which content. |
| Behaviour modules | cascade guard · convention drift · loop breaker · session continuity · auto-doc · change narrative · architecture guard | Each guardrail fires on a join of the three above, at the moment of the edit — not as a tool the agent chose, not as a review after the fact. |
The unifying point. Drift detection requires memory anchored to a live graph. Cascade guard requires the graph and the edit-intent ledger on one process. Convention drift requires the pattern store and the new-code stream in the same memory space. Spread these across five disconnected MCP servers and none of them can fire — they can only sit and wait to be called, which is the failure mode this whole thing exists to fix. That's the difference between a stack of tools and a guardrail.
Fewer tokens, as a side effect
unerr was built to stop bad changes, not to save tokens. But a guardrail that only ever hands over the one scoped fact that matters — the rule for the entity in front of the agent, 50 lines instead of 3,000 — spends far fewer tokens almost by accident. So you get this for free:
- 86–90% of an agent's code-navigation tokens removed in head-to-head benchmarks vs grep+read — real tokenizer, fidelity-gated (any "saving" that lost the answer is discarded), reproducible on any repo. See the benchmarks →
- ~84% of an AI coding agent's tokens are tool output, mostly file reads (JetBrains, NeurIPS 2025) — unerr intercepts at the read layer, so the window isn't diluted.
- Tool-selection accuracy collapses 58% → 26% as MCP tools go from 9 to 51 (LangChain ReAct benchmark) — unerr is one runtime instead of five servers, so it doesn't eat the agent's tool-selection budget. Anthropic itself acknowledged this in Jan 2026 by shipping MCP Tool Search.
- 0 LLM calls per query in the core — facts, conventions, drift signals, and graph lookups are all algorithmic. No API keys, no per-turn inference cost, no telemetry.
The point was never the token number. It's that the agent lands on the right code, sees the right guardrail, and you stop paying — in tokens and in afternoons — for the changes it would otherwise have to undo.
Under the hood — architecture, CLI commands, MCP tools, dev setup
Architecture
AI Agent (Claude Code / Cursor / Windsurf / any MCP client)
│
├── stdio MCP ──→ unerr --mcp (bridge, per IDE session)
│ │
│ └── UDS ──→ unerrd (one lightweight Node process
│ per machine, auto-spawned,
│ exits after 30 min idle)
│ │
│ └── per-repo unerr process(es)
│ ├── CozoDB graph (in-process, <5ms)
│ ├── Fact store (cross-session memory)
│ ├── Timeline + ledger (every tool call)
│ ├── File watcher (incremental reindex)
│ ├── Convention engine
│ ├── Compression engine
│ └── Behavior modules
│
└── Dashboard ──→ http://localhost:9847 (SSE-streamed live)
One local DB per repo. Zero network calls. No API keys. No cloud. Your code never leaves the machine.
Full module map and source-tree breakdown: ARCHITECTURE.md.
Design principles — zero network calls; stdout is sacred (MCP JSON-RPC only, everything else to stderr); <5 ms query responses; first useful output <5 s (shallow index first, deep enrichment in background); graceful degradation (the agent still works if unerr is down, you just lose the guardrail layer).
Tech stack TypeScript (ESM) · CozoDB (Rust/NAPI) · web-tree-sitter (WASM) · MCP SDK · Ink (React CLI) · React + Vite (dashboard) · tsup · Vitest
CLI commands
unerr install <agent> # MCP config + skills + hooks + instructions for one agent
unerr uninstall # Remove unerr integration from this repo
unerr doctor # Check PATH + environment, auto-fix if unerr isn't on all shells
unerr status # Proxy health, entity count, graph age
unerr stats # Session statistics (tokens, tool calls, compression)
unerr --mcp # Stdio bridge — what your IDE invokes via .mcp.json
unerr pm status # Process manager: PID, uptime, repos, memory, idle countdown
unerr pm logs # Tail ~/.unerr/logs/unerrd.log
unerr pm dashboard # Open http://localhost:9847
unerrd is a lightweight Node process that supervises every registered repo. Your IDE invocation auto-spawns it; it exits cleanly after 30 minutes of no MCP activity. unerr pm --help lists the rest.
MCP tools (22)
Grouped by what the agent gets, not by file:
- Graph intelligence (8) —
get_entity,get_file,get_references,get_imports,search_code,get_conventions,get_critical_nodes,get_cross_boundary_links. - Structural analysis (3) —
get_project_stats,file_connections,get_test_coverage. - File protocol (2) —
file_read(context-aware, auto-injects conventions and facts),file_outline(structure without body). - Persistent memory (3) —
unerr_remember(user-stated facts with verbatim quote + confidence),record_fact(agent-detected conventions / decisions / anti-patterns),recall_facts(hierarchical scope + decay-adjusted confidence). - Session markers (4) —
mark_intent,mark_decision,mark_blocker,mark_resolution. Inline as the agent works; powers turn titles and the cross-session resume strip. - Web fetch (1) —
fetch_url(DOM-extracted markdown, BM25 re-ranking, content-hash cache). Replaces built-in WebFetch. - Code review (1) —
review_changes(graph-evidenced review of a diff — flags breaking callers, contract drift, duplicate logic).
Every response carries inline ur|<tag> signals for high-priority guidance — drift, blast-radius warnings, circuit-breaker halts — so the agent acts on what it just learned without burning a turn.
Manual MCP config (any MCP-compatible client)
{
"mcpServers": {
"unerr": {
"command": "npx",
"args": ["@unerr-ai/unerr", "--mcp"]
}
}
}
Benchmarks
unerr removes 86–90% of the tokens an agent would otherwise spend navigating and reading code — measured, not estimated, across the same questions and the same tokenizer, with a fidelity gate that discards any "saving" that lost the answer. Methodology, reproduction commands, and per-repo results: benchmarks/README.md.
Contributing
See CONTRIBUTING.md for setup, day-to-day commands, code conventions, and pre-PR checklist.
License
Apache License 2.0 — free to use, modify, and distribute, including commercially. Includes an explicit patent grant.
npm install -g @unerr-ai/unerr
unerr.dev · npm registry · Discord · X · LinkedIn · Fully local. No account. No cloud. Free.