Obsidian MCP Server
Self-hosted MCP server for Obsidian: semantic + full-text search, wikilink graph, note CRUD, OAuth, and a self-describing vault guide.
Documentation
Obsidian MCP Server
A self-hosted Model Context Protocol server that turns your Obsidian vault into shared memory between you and your AI agents. Indexed, searchable, and self-describing — agents read what you read, link what you link, and pick up your folder layout, frontmatter schema, and tag conventions on the first call instead of being briefed from scratch every session.
Stack: Python 3.12, FastAPI, PostgreSQL with pgvector. Pluggable
embeddings (Ollama bge-m3, or OpenAI text-embedding-3-{small,large}).
Contents
- Why this exists
- A session at the keyboard
- What's in the box
- vs. other Obsidian MCP servers
- Who this is for
- Control panel
- Quick start
- Cost expectations
- The self-describing vault
- Multi-user mode
- Configuration
- Architecture
- Project layout
- Development
- Security notes
Why this exists
There are three things going on here, and they're more interesting together than apart.
1. A shared memory layer between you and your agents
I think of my Obsidian vault as my exocortex. The "big me" that includes notes, calendars, scripts, search, and AI assistants is substantially more capable than the "small me" of the biological brain alone. It's also where I do most of my thinking, because writing something down is itself a form of thought.
The problem is that until recently, the vault was passive. I had to go find things. Agents that wanted to help me had to be briefed from scratch every session, and they had no way to see what I'd already written about a topic.
This server fixes that. Now the same vault feeds my own daily writing and any agent I plug into it. The agent reads what I read, links what I link, follows the same wikilinks, sees the same frontmatter. When I write a project note on Sunday, my Monday-morning briefing agent already knows about it. When the agent leaves notes from a research session, they show up in my normal Obsidian search.
A concrete version of this: I'll spend a session in Claude Code on a project, wrap up, push the commits, and then just say "update Obsidian." The agent reads the vault guide, figures out where project notes live in my structure, picks the right format and frontmatter, and leaves a session log I can later roll into a status report. No path-passing, no telling it what to write — the conventions are already in the vault, and it follows them.
That's the exocortex idea made concrete: one place that holds context, and both the human and the agents reading and writing into it on the same terms.
2. Agent memory that you can actually read
The other half is the inverse. If you let an agent run for a while, it needs memory. Most setups solve this with an opaque vector store, a SQLite blob, or a managed "memory" service that you can't see into. That works until you want to know what the agent thinks it knows about you, or you need to correct something, or you want to understand why it just made a weird suggestion.
This server gives you a different deal. Agent memory lives as markdown files in your vault. Folder structure, file names, frontmatter, all visible. You can open the file in Obsidian and read it. You can edit it. You can delete it. You can grep it. The agent's "memory" is a human-auditable artifact that sits in the same place as your own notes, with the same tools available.
The home lab is the use case that sold me on this. My vault has notes on the rack, the network, and every Home Assistant integration. I can say "set up a night-light mode in the master bathroom, 1% after 11pm" and a sysadmin agent finds the right config, makes the change, and updates the doc in the same pass. Six months later when I've forgotten how it works, the answer is in the vault, not buried in some chat history I can't search.
The semantic search and wikilink graph still work over that material, so retrieval is fast and conceptual. But the substrate is files you own, not a black box.
3. The vault follows you
The thing that still surprises me is that this is internet-facing. Same vault, same notes, reachable from anywhere I happen to be talking to an agent — Claude in a browser tab, Claude on my phone on the train, an n8n workflow firing on a schedule, a Claude Code session on whatever laptop is in front of me. All behind OAuth or a bearer key, all hitting the same source of truth.
So when I hear an interesting podcast on a commute and want to think out loud about it with Claude on my phone, the agent isn't starting cold. It can pull up what I've already written on adjacent topics, surface a note I half-finished six months ago, and at the end of the conversation suggest updates and write them in. The vault doesn't have to be near me to be the thing I'm working in.
A session at the keyboard
To make the abstract concrete, a short transcript from a real session. Tool calls inline; the user types in plain English and the agent picks the right tool.
you > find anything I've written about why retrieval-augmented
chat is hard
claude
→ semantic_search(query="why retrieval-augmented chat is hard")
• 2025-12-03 - RAG failure modes.md
• 2025-10-18 - Chunking tradeoffs.md
• 2024-06-22 - Vector recall vs precision.md
the closest hit is your December note on RAG failure modes. let
me see what it's connected to.
→ get_neighborhood(path="2025-12-03 - RAG failure modes.md",
depth=1)
8 connected notes. notable ones:
• "Hybrid search" — a re-ranking design you sketched but
didn't ship
• "Out-of-distribution queries" — a half-finished draft from
October
• "Embedding model choice" — links to bge-m3, your current
model
you have three connected pieces here: a failure-modes catalog,
an unshipped hybrid-search sketch, and an abandoned O-O-D draft.
want me to summarize all three together, or pull up the draft
so you can decide whether to finish it?
you > pull up the draft, and tag it #revisit-2026 in frontmatter
while you're there
claude
→ read_note(path="2025-10-18 - OOD queries (draft).md")
→ set_frontmatter(
path="2025-10-18 - OOD queries (draft).md",
updates={"tags": ["draft", "rag", "revisit-2026"]}
)
here's the draft, and the tag is on. you stopped right before
the section on confidence thresholds; the open question you
left yourself was…
Two things to notice. First, the agent didn't need to be told what
folder to look in or what tools to use — it picked them. Second, the
write at the end is structured (set_frontmatter mutating YAML, not
a regex over the file body), so the note round-trips cleanly. The
self-describing vault and the wikilink graph are doing the work that
makes this feel natural.
What's in the box
The server exposes 20 MCP tools across six concerns.
Search and discovery
keyword_search(query, folder?, tags?, frontmatter?, limit=20), full-text via PostgreSQLtsvector; the text-search config(s) are configurable viaFTS_CONFIGS(see Full-text search language(s))semantic_search(query, folder?, tags?, frontmatter?, limit=15), vector similarity via pgvector, one preview chunk per notelist_notes(folder?, limit=50), sorted by modified timeget_recent(folder?, limit=20), recently changedget_tags(limit=50), tag and countget_vault_guide(), the Obsidian primer plus this vault'sCLAUDE.md, served live
Read and write
read_note(path)create_note(path, content), atomic write, refuses overwriteedit_note(path, …)with four mutually exclusive modes: full replace (default),append=True,find=…(with optionalreplace_all), orsection=<heading>(ATX headings, supportsParent/Childpath-style disambiguation).dry_run=Truereturns a unified diff without writing.move_note(from_path, to_path, rewrite_links=False), relocates and optionally rewrites incoming[[Old]],[[Old|alias]],[[Old#anchor]],![[Old]], and[[folder/Old]]references in source notesdelete_note(path, permanent=False), soft-delete to.trash/<YYYYMMDD-HHMMSS>-<basename>by default.permanent=Truedoes a hardos.unlink.set_frontmatter(path, updates, remove?), structured YAML mutation. Body is byte-identical when only frontmatter changes.
File access (non-markdown)
Raw read/write/browse of arbitrary vault files (PDFs, images, skill assets, data files) — distinct peers to the note tools, which stay markdown-only. Pure byte transport: no server-side PDF/text extraction, no embedding or indexing of non-markdown files.
read_file(path, encoding="auto"), returns text-like files as text, images as an inline image block that renders in-client, and other binaries as a base64 string.text/base64force the form. Refuses files overMAX_FILE_READ_BYTES(default 10 MB).write_file(path, content, encoding="base64", overwrite=False), lands a file in the vault; base64 for binary,textfor UTF-8. No-clobber by default, auto-creates parent dirs, atomic write. Capped atMAX_FILE_WRITE_BYTES(default 25 MB).list_files(folder=".", pattern="*", recursive=False, limit=200),ls-style browse of files and subdirectories with size and mtime, glob-filterable and result-capped.
All three reuse the path-traversal guard and exclude dot-directories
(.obsidian, .git, .trash, …), matching the indexer's visibility
rule.
Wikilink graph
get_backlinks(path, limit=50), notes linking TOpathget_links(path), outgoing links, both resolved and danglingget_neighborhood(path, depth=1, limit=50), undirected BFS over the resolved-link graph, capped at depth ≤ 5 and limit ≤ 200find_related(path, limit=10), semantic neighbors via averaged chunk embeddings and pgvector cosine distance, deduped per notefind_orphans(folder?, limit=50), notes with zero in or out resolved links
Auth and ops
- API keys with the
omcp_prefix, stored as SHA-256 hashes, withreadandreadwritepermission scopes. Write tools refuse on read-only keys. - OAuth 2.0 PKCE (S256) flow for clients like Claude Desktop and claude.ai.
- Control panel (Jinja2, htmx, Tailwind) for keys, usage logs, indexer status, embedding-provider info, and a danger-zone reset.
- Every tool call is logged to
usage_logswith name, params (truncated to 200 chars), duration, and response size.
All write tools route through src/services/vault.py::write_file,
which writes to a tmp file in the same directory and os.replace()s
it onto the destination. A crash mid-write cannot truncate a note.
vs. other Obsidian MCP servers
There are several existing MCP servers for Obsidian, and most of them solve a different problem than this one. The lightweight ones are glue over Obsidian's Local REST API plugin or the filesystem: they let an agent reach the files, but don't build any infrastructure of their own. They're great if "I just want Claude to read my notes" is the goal and you keep Obsidian running locally.
This server is on the other end of the spectrum: a real backend with a persistent index, semantic retrieval, a wikilink graph, OAuth, and an admin UI. The cost is Postgres and Docker. The benefit is everything you can build on top of that.
| This server | MarkusPfundstein/mcp-obsidian | StevenStavrakis/obsidian-mcp | jacksteamdev/obsidian-mcp-tools | |
|---|---|---|---|---|
| Persistent index (Postgres) | ✅ | — | — | — |
| Semantic search (vectors) | ✅ | — | — | — |
| Wikilink graph queries | ✅ | — | — | partial |
| Runs without Obsidian open | ✅ | — | ✅ | — |
| OAuth 2.0 client flow | ✅ | — | — | — |
| Multi-user / per-user vaults | ✅ | — | — | — |
| Admin UI + usage logs | ✅ | — | — | — |
| Atomic writes + dry-run diffs | ✅ | — | — | — |
| Setup tax | Postgres + Docker | Obsidian + REST plugin | Python only | Obsidian plugin |
Comparison reflects each project's documented features at time of writing; verify the specifics before betting on them.
Who this is for
- Homelab folks who already run Postgres and Docker, or are happy to spin them up. The setup tax is the price of admission for the semantic and graph layers.
- People who keep an opinionated vault — task placement logic, frontmatter schemas, tag taxonomy — and want agents to follow those conventions on the first call instead of being briefed every session.
- Anyone running more than one MCP client (Claude Desktop, Claude Code, Claude in a browser, n8n) against the same notes and tired of re-explaining the vault to each.
- Folks who want agent memory to live as plain markdown files they can read, edit, grep, and version-control, not in an opaque vector store or a managed memory service.
Who this isn't for
- "I just want Claude to read my notes" with the lightest possible setup. Use one of the filesystem-glue projects above; you don't need this.
- Anyone unwilling to run a database. There is no SQLite fallback; pgvector is doing real work, and a managed Postgres with pgvector support is part of the stack.
- People who want a turnkey hosted product. This is a self-hosted server you run yourself.
Control panel
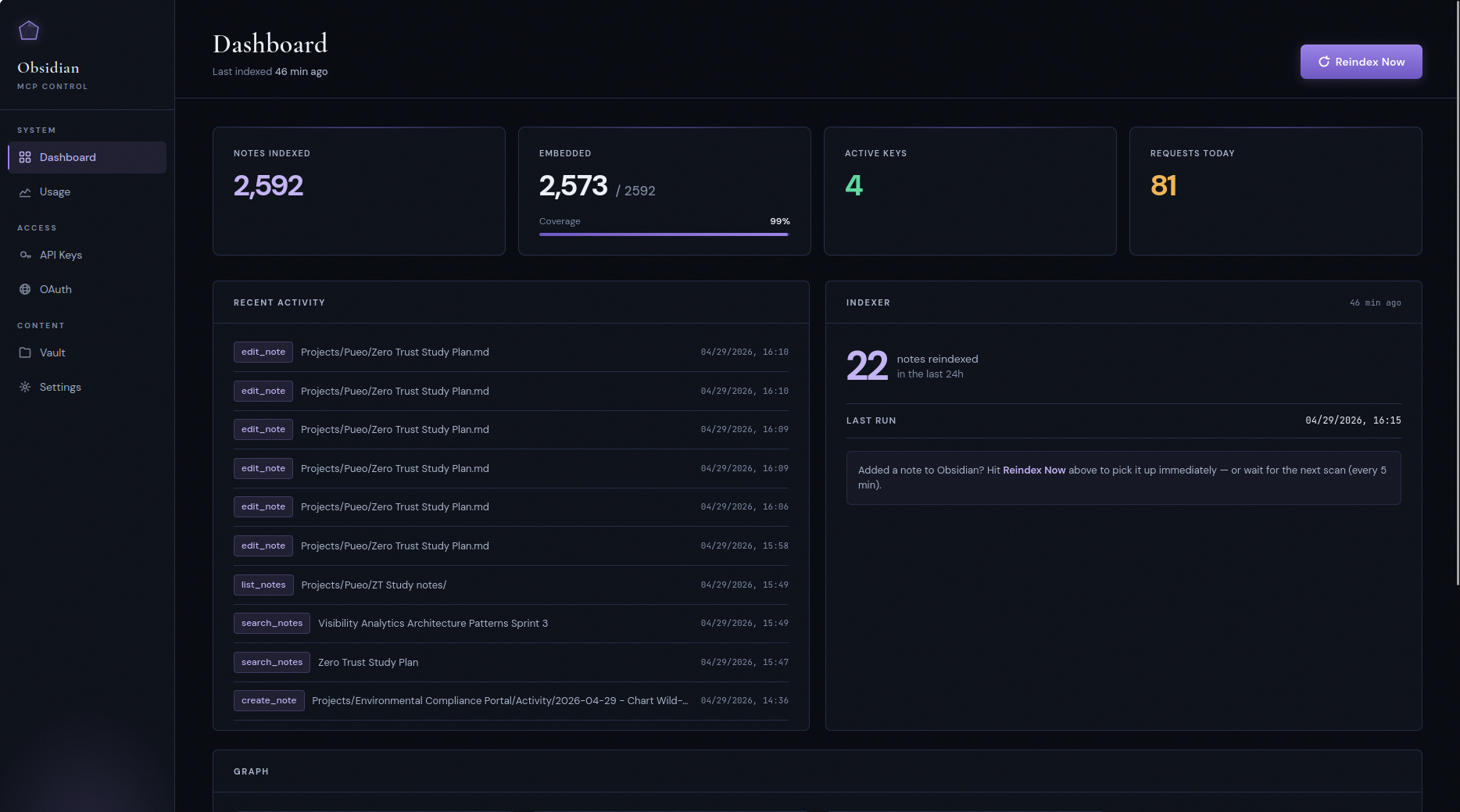
The server ships with a built-in admin UI for the parts of operations that are easier to look at than to query: minting keys, watching the indexer, eyeballing tool-call traffic, and resetting embeddings when you switch providers.
Usage
Per-tool-call audit log with a 14-day request histogram. Every MCP call is recorded with the calling key, tool name, duration, and response size — useful for noticing a misbehaving agent burning tokens on something it shouldn't.
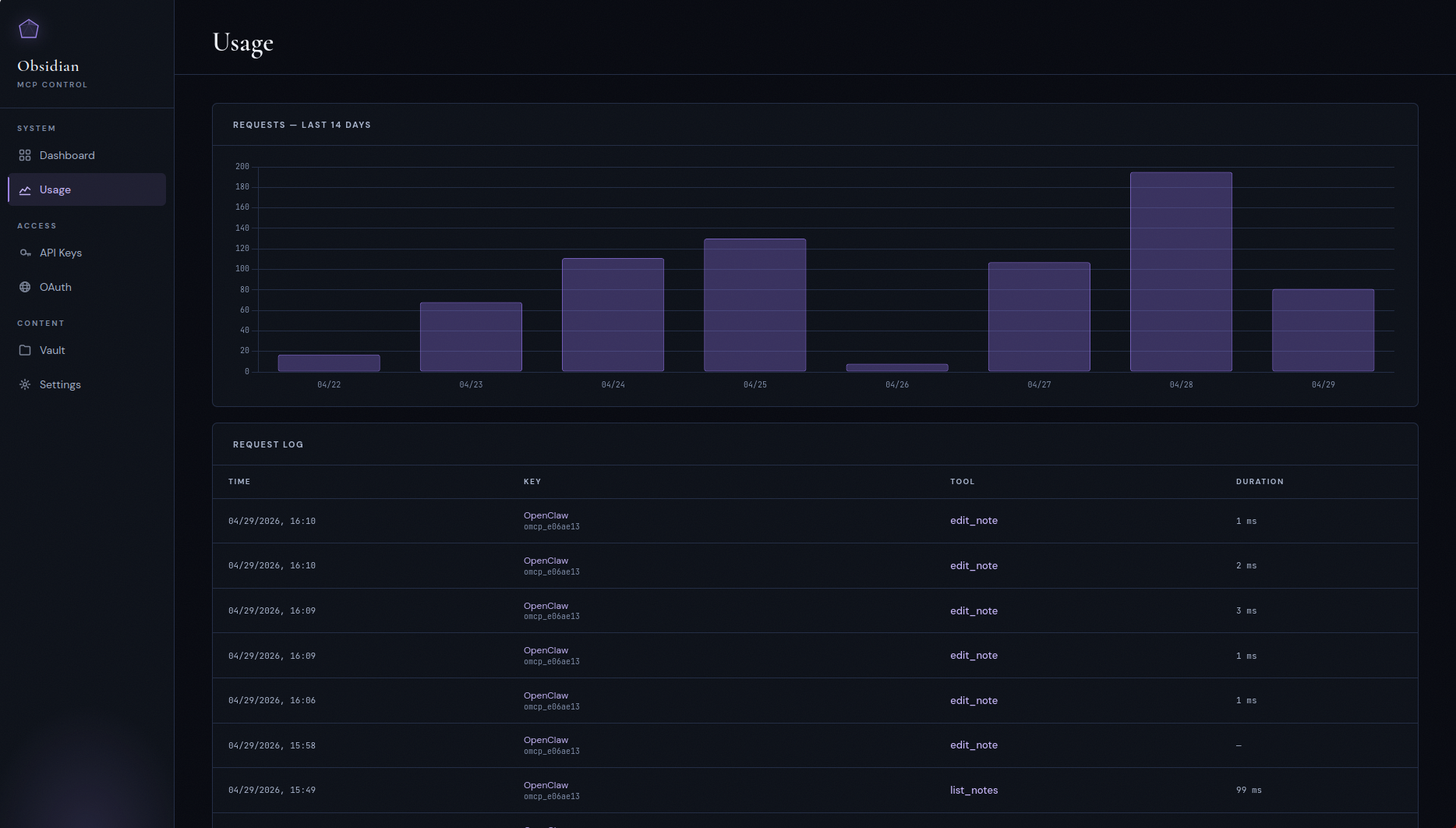
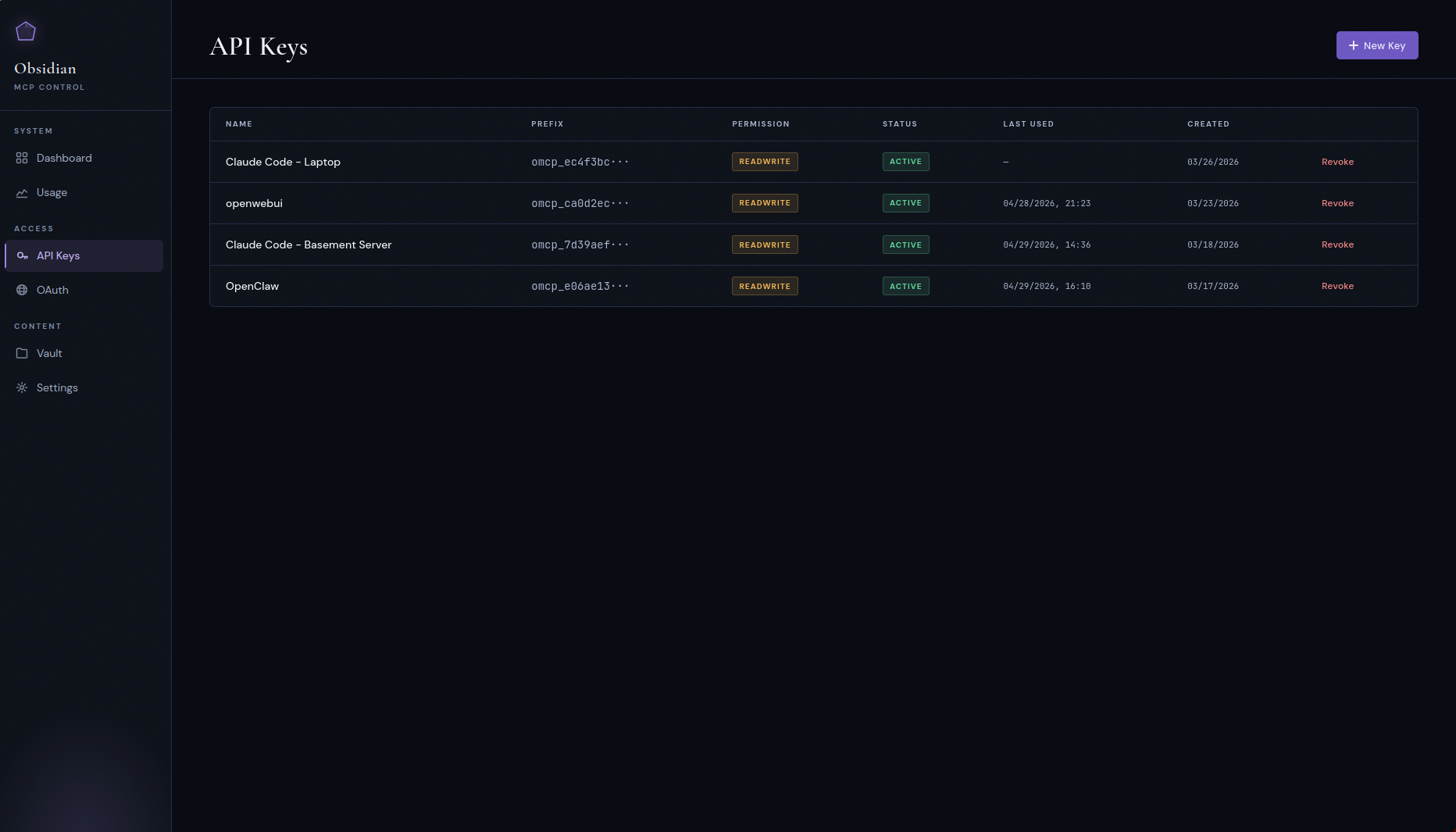
API keys and OAuth clients
Bearer keys with read / readwrite scopes for API clients, and a
separate OAuth 2.0 PKCE flow for clients like Claude Desktop and
claude.ai that expect a proper authorization-code dance.
Vault browser
A read-only file tree of the mounted vault, mostly for sanity-checking that the container sees what you think it sees.
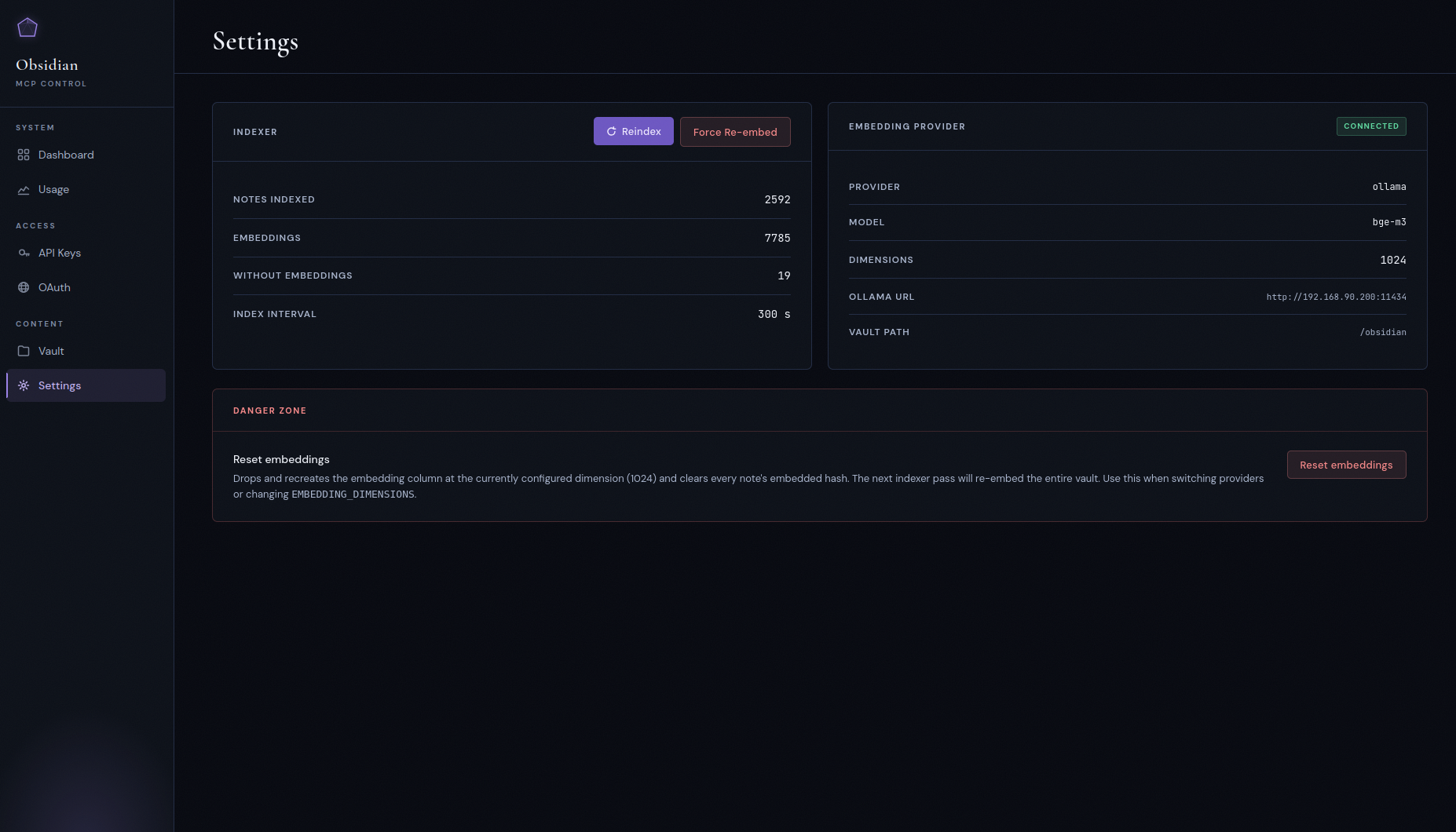
Settings
Indexer status, current embedding provider and model, vault path, and the danger-zone reset that drops and recreates the embeddings column at the configured dimension. Use this when switching providers.
Quick start
Deploying on a VPS from scratch? See
DEPLOYMENT.mdfor the full walkthrough: Postgres setup, Caddy and TLS, vault sync via Nextcloud, and the gotchas that bite first-time deploys.
Prerequisites
- Docker and Docker Compose
- A PostgreSQL 16 instance reachable from the container, with the
pgvectorextension installed - Either an Ollama instance running
bge-m3, or an OpenAI API key. Anything that speaks the OpenAI embeddings protocol works (Azure OpenAI, OpenRouter, Together, etc.).
1. Clone, configure, point at your vault
git clone https://github.com/maxkuminov/obsidian-mcp.git
cd obsidian-mcp
cp .env.example .env
$EDITOR .env
In docker-compose.yml, point the /obsidian volume at your vault:
volumes:
- /path/to/your/vault:/obsidian
2. Pick an embedding backend
Option A, OpenAI (zero local infra):
EMBEDDING_PROVIDER=openai
OPENAI_API_KEY=sk-...
EMBEDDING_DIMENSIONS=1024
OPENAI_EMBEDDING_MODEL=text-embedding-3-small
The server validates OPENAI_API_KEY at startup and refuses to boot
if it's missing.
Option B, Ollama (self-hosted, GPU recommended):
EMBEDDING_PROVIDER=ollama
OLLAMA_URL=http://your-ollama-host:11434
EMBEDDING_MODEL=bge-m3
EMBEDDING_DIMENSIONS=1024
This is the default. Omitting EMBEDDING_PROVIDER falls back to
Ollama.
3. Deploy
make init # data dirs and .env from template (skip if you've already edited)
make db-init # create database, user, and pgvector extension
make deploy # build, push to local registry, run migrations, recreate container
The first deploy backfills the index, the wikilink graph, and the
embeddings. For a 2 to 3k-note vault on Ollama with a GPU this takes
a few minutes. On text-embedding-3-small it's seconds.
4. Connect a client
Mint an API key in the control panel, then point your MCP client at:
URL: https://obsidian-mcp.<your-domain>/mcp
Auth: Bearer omcp_...
For Claude Desktop, add to claude_desktop_config.json:
{
"mcpServers": {
"obsidian": {
"url": "https://obsidian-mcp.<your-domain>/mcp",
"headers": { "Authorization": "Bearer omcp_..." }
}
}
}
For Claude Code:
claude mcp add obsidian --transport http \
--url "https://obsidian-mcp.<your-domain>/mcp" \
--header "Authorization: Bearer omcp_..."
The first thing any agent should do in a new session is call
get_vault_guide(). That's how it learns your folder structure,
naming conventions, and YAML schema before it writes anything.
Cost expectations
If you go the OpenAI route (the realistic path on a CPU-only VPS), the first-index spend is small and the steady state is nearly free. Rough numbers assuming an average note around 1,500 tokens (three 512-token chunks), at OpenAI's published rate at time of writing:
| Model | $/1M tokens | 1k notes | 10k notes | 100k notes |
|---|---|---|---|---|
text-embedding-3-small | $0.02 | ~$0.05 | ~$0.50 | ~$5.00 |
text-embedding-3-large | $0.13 | ~$0.30 | ~$3.00 | ~$30.00 |
After the first index, only changed notes are re-embedded. Ongoing cost is proportional to edits — pennies a month for a typical vault.
If you self-host Ollama with a GPU, embedding cost is whatever your power bill is. Ollama on CPU works but is too slow to be usable on a vault of more than a few hundred notes.
The self-describing vault
This is the part most "MCP for Obsidian" projects miss. They stop at read, write, and list. The interesting question isn't "can the agent reach the files," it's "does the agent know the rules?"
If you have an opinionated vault — task placement logic, folder conventions, required frontmatter, tag taxonomy — an agent with write access can do real damage without that context. Tasks land in the wrong folder. Bare-date filenames collide with templates. Wrong tags break Dataview queries. The data layer works fine; the context layer is where the failures show up.
The fix is small. Keep a machine-readable instruction file
(CLAUDE.md at the vault root) that describes the system's own rules.
Expose it as a dedicated tool. Every connecting agent calls it once at
the start of a session and immediately knows how the vault works.
Update the file, every agent sees the change on the next call. No
client-side config. No system-prompt injection. The vault is
authoritative about its own rules.
get_vault_guide() does exactly this. It returns a generic Obsidian
primer (wikilink syntax, embed syntax, tag conventions, common plugin
literals) plus the vault's CLAUDE.md live. The hint to call it first
is baked into the write-tool descriptions so the agent gets pulled
into the right behavior even without prompting.
Multi-user mode
Single-user mode is the default and works exactly as described above — one vault, one set of API keys, no in-app user concept. Multi-user mode is an opt-in flag that turns the same container into a small multi-tenant deployment: in-app username/password login, per-user vault scoping, an admin role for troubleshooting, and a regular-user role that sees only its own keys/OAuth clients/usage. One container, one Postgres, strict isolation between users.
Enable it on an existing deployment with no data loss — your current vault and keys carry over to the bootstrap admin.
Enabling
- Set
MULTI_USER_MODE=trueand a strongSECRET_KEYin.env(openssl rand -hex 32is fine). The app refuses to start with the placeholder value when the flag is on. make deploy(ordocker compose up -d --force-recreate).- Visit the panel. Because the
userstable is empty, you're routed to/admin/register— the one-time bootstrap form. It's still behind Traefik'schain-oauth@filemiddleware, so only people Traefik already trusts can claim admin. - Register with a chosen username and password. The bootstrap form
pre-fills
vault_pathwith whateverVAULT_PATHwas set to, so your existing notes immediately belong to this new admin. No re-index, no re-embed, no data loss — every previously indexed note, API key, OAuth client, and usage log row gets backfilled to the bootstrap user in a single transaction.
Inviting users
-
Edit
docker-compose.ymlto add a volume mount for the new user's vault under/vaults/<username>. Host paths with spaces must be quoted as a single YAML string:volumes: - "/storage/vaults/alice:/vaults/alice" - "/storage/shared/bob/Obsidian:/vaults/bob"make deployto apply. -
In the panel,
/admin/users/create— pick a username and set an initial password. -
/admin/users/{id}/edit— set the user'svault_pathto the container path you just mounted (e.g./vaults/bob). The form shows a dropdown of unassigned/vaults/*directories that exist on disk. -
Share the credentials out-of-band. The user logs in at
/admin/auth/login, gets their own keys/OAuth/usage views, and cannot see other users' notes.
What admins see
Admins see API keys, OAuth clients, and usage logs for all users; they
own the Settings page (embedding provider, indexer trigger, danger
zone) and the Users page. Admins do not browse other users' vault
contents through the panel — that's intentional. Troubleshooting
another user's vault means either inspecting it via docker exec or
temporarily reassigning their vault_path, not UI snooping.
Rolling back
Set MULTI_USER_MODE=false, restart. Existing API keys keep working
(per-user filters skip when no user context is set), the login UI and
session cookies disappear, and the panel falls back to its
Traefik-OAuth-only mode. The schema stays in place, so flipping back
to multi-user later resumes where you left off without re-bootstrapping
(the users table is non-empty, so /admin/register is closed).
Constraints and known limits
- The indexer iterates active users sequentially each cycle. Fine for tens of users; hundreds would need parallelization.
- Password reset is admin-driven only — there's no email-based self-service flow.
- No rate limiting on
/admin/auth/login. The Traefik OAuth gate in front of the panel is the main brute-force defense; if you expose/admin/auth/loginto the open internet, put a rate-limit middleware in front of it. - The
vault_pathvalidator does not resolve symlinks, so an admin can technically point a user at host files via a symlinked/vaults/<name>. Treat/vaults/as an admin-trust boundary.
Configuration
| Variable | Default | Purpose |
|---|---|---|
DATABASE_URL | — | postgresql+asyncpg://user:pass@host/db |
VAULT_PATH | /obsidian | In-container vault mount |
SECRET_KEY | — | itsdangerous signer key |
INDEX_INTERVAL_SECONDS | 300 | Periodic reindex cadence |
MAX_FILE_READ_BYTES | 10485760 | read_file cap (10 MB); bounds inline/base64 responses |
MAX_FILE_WRITE_BYTES | 26214400 | write_file cap (25 MB), decoded byte length |
FTS_CONFIGS | english | Keyword-search text-search config(s). JSON or CSV. See Full-text search language(s). |
EMBEDDING_PROVIDER | ollama | ollama or openai |
EMBEDDING_DIMENSIONS | 1024 | pgvector column width |
OLLAMA_URL | — | Used when provider is Ollama |
EMBEDDING_MODEL | bge-m3 | Ollama model name |
OPENAI_API_KEY | — | Required when provider is OpenAI |
OPENAI_BASE_URL | https://api.openai.com/v1 | Override for Azure or proxies |
OPENAI_EMBEDDING_MODEL | text-embedding-3-small | OpenAI model |
CHUNK_SIZE | 512 | Approx tokens per chunk (4-char heuristic) |
CHUNK_OVERLAP | 0 | Token overlap between chunks |
MCP_SANDBOX_MODE | false | Registry-eval only. Skips DB, indexer, embedding provider, and /mcp auth so introspection works without external deps. Do not enable in production. |
See .env.example for the full set with comments. For first-index
spend on OpenAI, see Cost expectations above.
Switching providers
Different models produce non-comparable vectors, so a provider switch requires reindexing.
make down- Update
.env. ChangeEMBEDDING_PROVIDER, set credentials, optionally changeEMBEDDING_DIMENSIONS. make reset-embeddingsmake up. The next indexer pass re-embeds the vault.
You can also use Settings → Danger zone → Reset embeddings in the control panel, which performs the same SQL while the server is running (pauses the indexer, runs the SQL, resumes).
If you change EMBEDDING_DIMENSIONS without running the reset, the
server detects the mismatch at startup and exits non-zero with a
pointer to the reset target.
Full-text search language(s)
keyword_search runs over a PostgreSQL tsvector. The text-search
configuration it uses — the stemmer and stop-word dictionary — is
controlled by FTS_CONFIGS. It defaults to english, which reproduces
the historical behavior exactly, so existing deployments need no action.
FTS_CONFIGS is a list, settable as JSON
(FTS_CONFIGS=["simple","norwegian"]) or comma-separated
(FTS_CONFIGS=simple,norwegian). Each note is indexed under every
listed config, and a query matches if any listed config's parse hits.
This is what makes a mixed-language vault work:
FTS_CONFIGS | Behavior |
|---|---|
english | English Snowball stemmer (default; running ↔ run). |
simple | Language-agnostic. No stemming or stop-words — matches exact word forms. A principled default for mixed-language vaults: keyword search is the exact-match arm, while semantic_search (bge-m3 is multilingual) handles morphological recall. |
english,norwegian | Both stemmers applied — keyword-side morphology for two languages at once. |
simple,norwegian | Verbatim lexemes plus Norwegian stems. |
The setting is global — applied to every vault (consistent with
EMBEDDING_MODEL, CHUNK_SIZE, etc., which are global too). For a
mixed-language multi-user instance, set a superset (e.g.
["english","norwegian"], or ["simple"]). Per-user FTS config is a
clean future extension but is not implemented.
A typo'd or uninstalled config name fails fast at startup with a message listing the configs available in your Postgres instance, rather than producing silent zero-result searches.
Changing FTS_CONFIGS requires a rebuild. Stored tsvectors are
computed at index time, so they go stale when the config list changes.
After editing .env and redeploying, run:
make rebuild-tsvectors
This re-reads each note and recomputes its content_tsvector under the
new config(s). It rebuilds the keyword index only — it does not
touch embeddings/vectors and makes no API calls, so it finishes in
seconds for a few thousand notes. (Do not confuse it with the expensive
make reset-embeddings flow.)
Tokenization caveat: the tsvector parser still splits on punctuation and hyphens regardless of config, so
bge-m3tokenizes tobge+m3.simplepreserves word forms, not punctuation-bearing strings; exact-string-with-punctuation matching would need a trigram index and is out of scope.
Architecture
┌──────────────┐ ┌──────────────────────┐
│ MCP clients │ HTTP + Bearer key │ FastAPI app │
│ Claude Desk │ ────────────────────▶ │ ┌────────────────┐ │
│ Claude Code │ │ │ MCP server │ │
│ n8n agents │ │ │ (20 tools) │ │
│ OpenWebUI │ │ └─────┬──────────┘ │
└──────────────┘ │ ▼ │
│ ┌────────────────┐ │
│ │ Services: │ │
│ │ - vault │ │
│ │ - search │ │
│ │ - embeddings │ │
│ │ - links │ │
│ │ - indexer │ │
│ └─────┬──────────┘ │
│ ▼ │
│ ┌────────────────┐ │
│ │ Postgres + │ │
│ │ pgvector │ │
│ └────────────────┘ │
└──────────┬───────────┘
▼
┌────────────────────┐
│ Embedding │
│ provider │
│ (Ollama / OpenAI) │
└────────────────────┘
Indexing pipeline
.md files in vault
↓ skip dot-dirs
parse frontmatter, extract tags (YAML + inline #hashtags)
↓ SHA-256 hash
skip if unchanged
↓
UPSERT notes_metadata (path, title, tags[], frontmatter JSONB,
content_hash, tsvector, modified_at)
↓
extract wikilinks/embeds/markdown-links → resolve targets →
note_links (source_id, target_id or NULL for dangling)
↓
chunk content (512 tokens, no overlap) → embed via provider →
note_embeddings (note_id, chunk_index, chunk_text, embedding[N])
↓
set embedded_content_hash = content_hash
The indexer runs on startup and every INDEX_INTERVAL_SECONDS (5
minutes by default). Hashes are content-only, so the change detector
ignores mtime jitter. Stale embeddings are caught by the
embedded_content_hash != content_hash mismatch.
Database schema
| Table | Purpose |
|---|---|
notes_metadata | Path, title, tags, frontmatter, content hash, embedded hash, tsvector, modified time |
note_embeddings | One row per chunk. embedding is vector(EMBEDDING_DIMENSIONS). |
note_links | Wikilink graph: source/target IDs, target_path, kind (link, embed, markdown) |
api_keys | Hashed bearer tokens, prefix for display, permission, expiry |
usage_logs | Per-tool-call audit |
oauth_clients, oauth_codes, oauth_tokens | OAuth 2.0 PKCE state |
GIN indexes on content_tsvector and tags[]. B-tree indexes on the
hot foreign keys. pgvector HNSW index on the embedding column
(vector_cosine_ops, m=16, ef_construction=64); queries set
hnsw.ef_search=80 and dedupe per note in Python after a 5x overfetch.
Project layout
src/
main.py FastAPI app, lifespan, MCP mount
config.py pydantic-settings
database.py async SQLAlchemy engine/session
models/db.py ORM models
mcp_server/ MCP server, tools, auth middleware
services/ vault ops, search, embeddings, links, indexer
api/ control-panel REST endpoints
control_panel/ Jinja2 templates and static assets
oauth/ OAuth 2.0 authorization-code flow
alembic/ database migrations
scripts/ one-off ops scripts (e.g. reset_embeddings.py)
tests/ pytest suite + smoke-test docs
openspec/ change proposals (spec-driven workflow)
Development
pip install -r requirements-dev.txt
pytest
The unit-test suite covers the embedding-provider abstraction, OpenAI
batching and retry behavior, config validation, and the
dimension-mismatch startup check. Network-bound tests use respx to
mock httpx, so no real network access is required.
To run the server outside Docker:
DATABASE_URL=... SECRET_KEY=... VAULT_PATH=... uvicorn src.main:app --reload
Make targets
make init First-time setup (data dirs, .env)
make build Build Docker image (no cache)
make deploy Build, push, backup, recreate container
make db-init Create database, user, and pgvector extension
make db-migrate Run alembic migrations
make db-backup Dump database to backups dir
make logs Tail container logs
make reindex Trigger a reindex via the API
make reset-embeddings Drop and recreate embedding column at configured dim
make rebuild-tsvectors Recompute keyword index for FTS_CONFIGS (no embeddings, no API calls)
make status Show container and health status
Security notes
- API keys use the
omcp_prefix and are stored as SHA-256 hashes. The raw key is shown exactly once at creation. - The control panel is intended to sit behind an external auth
gateway. The included
docker-compose.ymluses Traefik with an OAuth chain. Don't expose/admindirectly to the internet. - The OpenAI key is rendered on the settings page as
key[:8] + "..." + key[-4:]and never appears in full in HTML or JS sources. - Path traversal is blocked at the service layer. All write paths
resolve through
Path.resolve().relative_to(vault_root). - Parameterized queries everywhere. No string interpolation into SQL.
- Response headers include HSTS,
X-Content-Type-Options: nosniff, andX-Frame-Options: DENY.
Status
Single-author, in active use as the maintainer's personal exocortex (2,500+ notes, multiple connecting agents). Public for anyone who wants to fork it. Issues and PRs welcome but expect opinionated review. This is a working system, not a generic platform.
License
MIT. See LICENSE.