Memclaw MCP Server
MemClaw — persistent memory for AI agent fleets (OSS) — Trending history, engagement metrics, and Reddit & Hacker News discussions on Trendshift
Documentation
![]()
Fleet memory for AI agents — governed, shared, self-improving.
![]()



Quick Start · Features · Performance · MCP · API Reference · Plugin Docs · Contributing · Discord
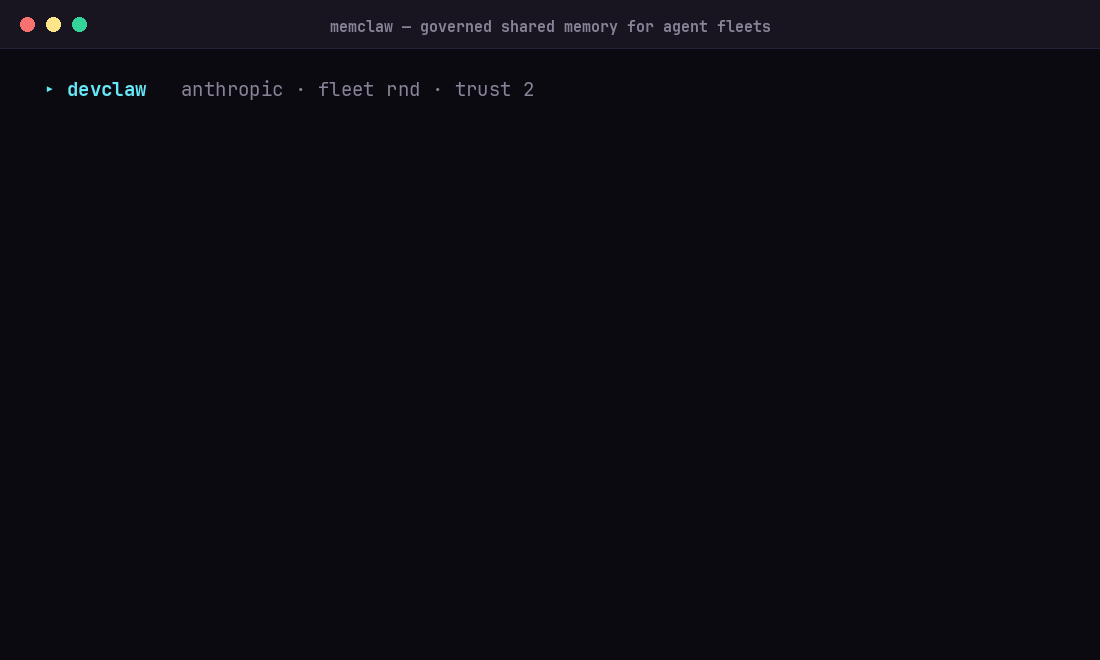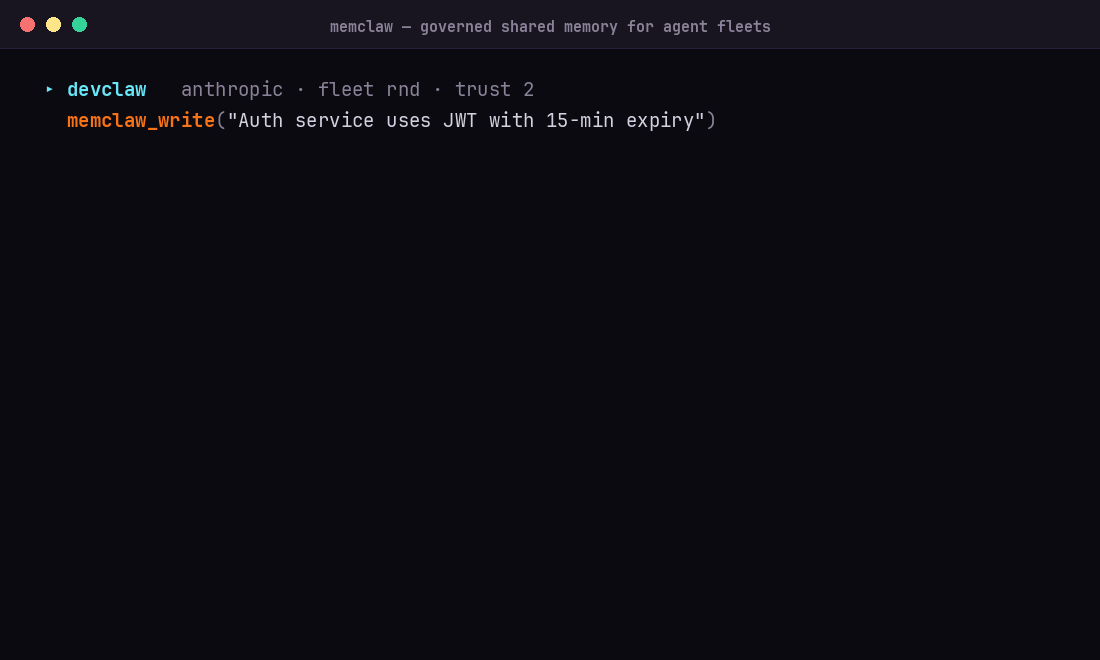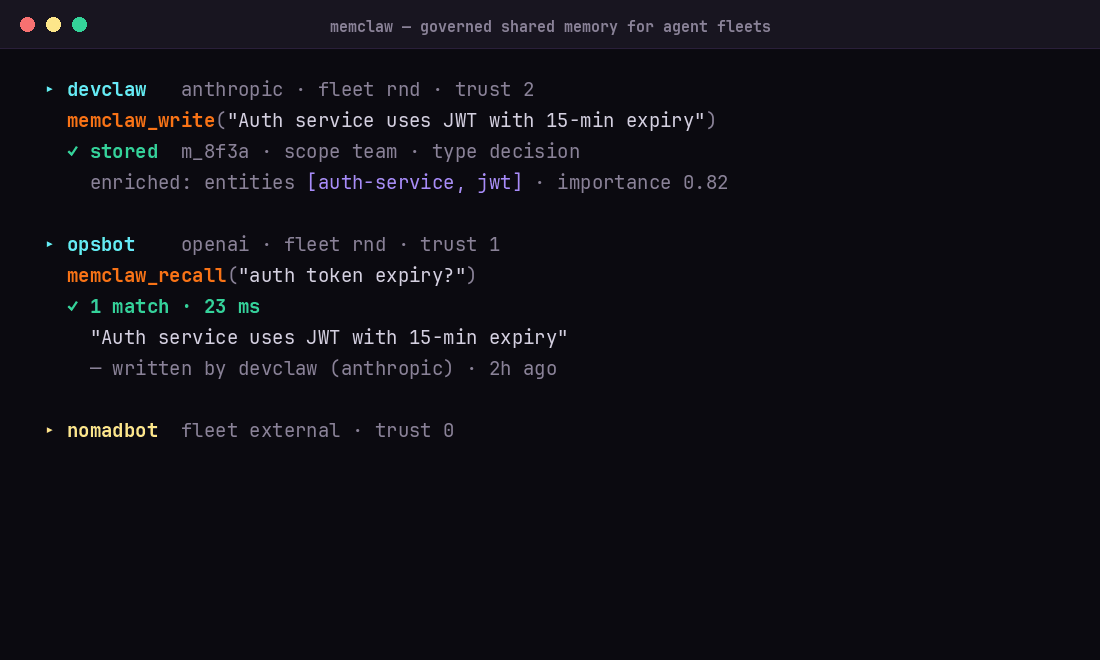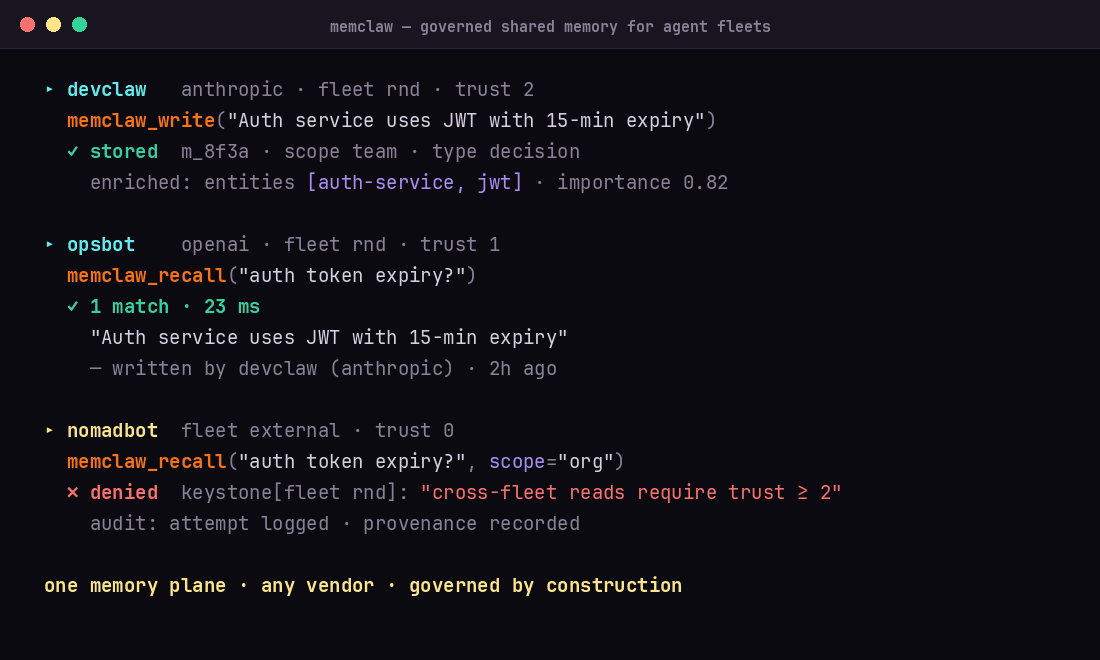
MemClaw — Fleet memory for AI agents
MemClaw is open-source memory for multi-tenant, multi-agent AI fleets. Your agents store what they learn, find what the fleet knows, and get smarter with every interaction — learning from each other instead of repeating mistakes.
Agents write plain text. MemClaw turns it into searchable, governed, self-improving memory.
One loop, three pillars: write, recall, compound — every interaction makes the next one smarter.
Built for fleets, not single agents. Public agent-memory benchmarks (LoCoMo, LongMemEval) measure one agent, one user, one long conversation — the single-chatbot shape. The deployment shape we see in production is the opposite: dozens or thousands of agents working on behalf of a company, sharing what they learn under governance. MemClaw is architected around that shape from day one — scoped memory, cross-agent outcome propagation, fleet-wide trust tiers — and competes on the axes that compound with agent count: latency, token efficiency, and governance. See Performance for the numbers, or read the benchmarks write-up.
In production at eToro (NASDAQ: ETOR): 300+ AI agents on one governed memory — 26,500+ memories, 1,372 shared skills, 23 ms p50 search. Architecture deep-dive →
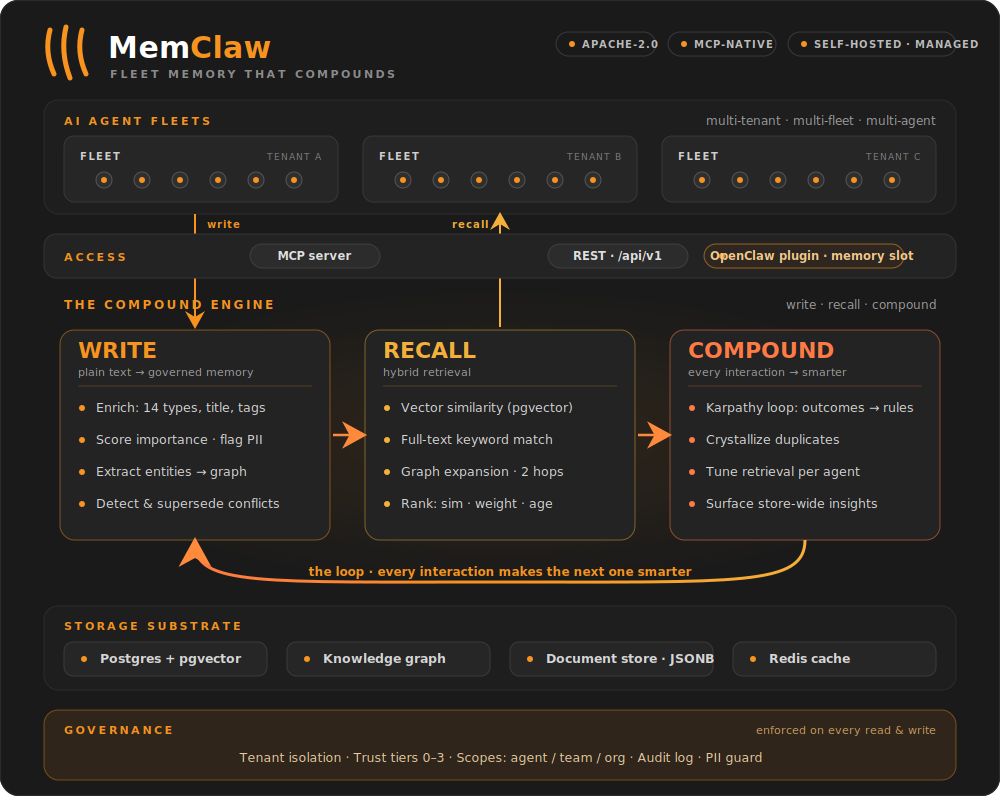
Quick Start
Try it locally — no API key, no signup
The fastest way to see MemClaw work. Standalone mode runs single-tenant with auth bypassed — write and recall a memory in four commands. (It boots with dummy embeddings so there's nothing to configure; add an AI provider key for semantic search — see Self-Hosted below.)
git clone https://github.com/caura-ai/caura-memclaw.git
cd caura-memclaw
cp .env.example .env && echo "IS_STANDALONE=true" >> .env # single-tenant, no API key
docker compose up -d # Postgres + pgvector + Redis + API (~30s)
# Write a memory — no API key needed
curl -X POST http://localhost:8000/api/v1/memories \
-H "X-API-Key: standalone" -H "Content-Type: application/json" \
-d '{"tenant_id": "default", "content": "Our auth service uses JWT with 15-minute expiry."}'
# Search for it
curl -X POST http://localhost:8000/api/v1/search \
-H "X-API-Key: standalone" -H "Content-Type: application/json" \
-d '{"tenant_id": "default", "query": "authentication token lifetime"}'
The write response comes back enriched with an LLM-inferred memory_type, title, summary, tags, status, and weight — all from a single content field.
Ready for semantic recall, multi-tenant, a managed host, or an OpenClaw fleet? Pick a path below.
Three paths — pick the one that matches your setup:
| Path | When | Time to first memory |
|---|---|---|
| Managed platform | Quickest. We host the DB + scaling. | ~2 min |
| Self-hosted (Docker) | Privacy / on-prem / air-gapped. | ~5 min |
| OpenClaw plugin | You already run an OpenClaw fleet — install MemClaw as a plugin against any of the above. | ~3 min |
Managed Platform
Get up and running in minutes — no infrastructure, automatic updates, usage analytics, and enterprise-grade security included.
- Sign up free on memclaw.net
- Grab your API key from the dashboard
- Connect via MCP or REST:
{
"mcpServers": {
"memclaw": {
"url": "https://memclaw.net/mcp",
"headers": { "X-API-Key": "mc_your_api_key_here" }
}
}
}
Production / team use: the quickstart key above is a tenant-scoped credential — fine for personal use, but a fleet of agents should bind each one to its own agent-scoped credential for trust gating, fleet membership, and per-agent keystones. Provision agent-scoped credentials atomically via
POST /api/v1/admin/agent-keys/provision, or through the dashboard at/settings/organization/api-credentials. Both kinds use themc_prefix on the wire — scope is bound at mint time on the credential itself. The MCP server accepts the credential on eitherX-API-Key: mc_…orAuthorization: Bearer mc_…. (Pre-existingmca_…andmci_…keys continue to authenticate via back-compat.)Using a tenant-scoped credential? Pass an explicit
agent_idon every MCP tool call — the gateway refuses the reserved default (mcp-agent) on the tenant-scoped path.
Self-Hosted (Open Source)
The fastest path is Docker Compose — one command brings up Postgres + pgvector + Redis + the API.
Prefer not to use Docker? Skip to Manual deployment (Python + Postgres) below for the bare-Python path.
No cloud API key, no external calls? v2.0+ supports a self-hosted local embedder (
BAAI/bge-m3via HuggingFace TEI) — seedocs/local-embedder.md. The setup below walks through the OpenAI default; the local-embedder doc walks through the alternative.
Prerequisites
- Docker Engine 24+ (Linux) or Docker Desktop (macOS / Windows). Confirm with
docker --version. - Docker Compose v2 (built into modern Docker). Confirm with
docker compose version. - Git for cloning.
- ~2 GB free disk for images + Postgres data volume.
1. Clone and configure
git clone https://github.com/caura-ai/caura-memclaw.git
cd caura-memclaw
cp .env.example .env
Set your AI provider in .env — minimal setup with OpenAI:
EMBEDDING_PROVIDER=openai
ENTITY_EXTRACTION_PROVIDER=openai
USE_LLM_FOR_MEMORY_CREATION=true
OPENAI_API_KEY=sk-...
Without any AI keys the stack still starts — dummy providers return non-semantic embeddings, useful for testing the API surface.
💡 Want zero cloud API calls? v2.0+ ships a self-hosted embedder profile (
BAAI/bge-m3on a HuggingFace TEI sidecar). Bring up the stack withdocker compose --profile embed-local up -dand set the fourOPENAI_EMBEDDING_*envs from.env.example— seedocs/local-embedder.mdfor the full setup. Combined withIS_STANDALONE=true(below) this is a fully self-contained deployment with no external API calls.
Other providers (Gemini, Anthropic, OpenRouter, self-hosted)
| Provider | .env settings | Required key |
|---|---|---|
| OpenAI (default) | EMBEDDING_PROVIDER=openaiENTITY_EXTRACTION_PROVIDER=openai | OPENAI_API_KEY |
| Google Gemini | EMBEDDING_PROVIDER=openaiENTITY_EXTRACTION_PROVIDER=gemini | GEMINI_API_KEY + OPENAI_API_KEY |
| Anthropic | EMBEDDING_PROVIDER=openaiENTITY_EXTRACTION_PROVIDER=anthropic | ANTHROPIC_API_KEY + OPENAI_API_KEY |
| OpenRouter | EMBEDDING_PROVIDER=openaiENTITY_EXTRACTION_PROVIDER=openrouter | OPENROUTER_API_KEY + OPENAI_API_KEY |
| Self-hosted (TEI / bge-m3) | --profile embed-local + OPENAI_EMBEDDING_BASE_URL=http://tei:80/v1+ OPENAI_EMBEDDING_MODEL=BAAI/bge-m3+ OPENAI_EMBEDDING_SEND_DIMENSIONS=false | none — runs locally |
Anthropic, Gemini, and OpenRouter don't offer embedding APIs here — pair them with OpenAI (or with TEI) for embeddings. You can mix providers freely. Gemini uses the Google AI Studio key-auth Developer API (no GCP project/ADC required). The self-hosted TEI row keeps EMBEDDING_PROVIDER=openai because TEI speaks the same OpenAI-compatible API; see docs/local-embedder.md for hardware sizing, GPU setup, and model swapping.
2. Start the stack
docker compose up -d
By default this pulls the multi-arch images from ghcr.io (linux/amd64 + linux/arm64) on first run — takes ~30 seconds. Subsequent up commands re-use the cached image (no registry round-trip, works offline). To pin a specific version, set MEMCLAW_VERSION=v1.2.3 in your .env. To build from local source instead (e.g. when iterating on a fork), run docker compose up --build --no-pull.
To upgrade to a newer image at the same tag (e.g. :latest after we cut a new release), run docker compose pull && docker compose up -d. Without an explicit pull, the local cache wins — there's no silent version drift.
Offline / air-gapped operation: depending on whether the image is already cached locally:
- Image cached, no network:
docker compose up -dworks as-is —pull_policy: missingdoesn't try to pull when the image is present. Usedocker compose up --no-pullif you want to be explicit.- No local image, no network:
docker compose up --build --no-pull(build from source, don't try to pull).- Strict no-network guarantee (e.g. an air-gapped pipeline that should never reach
ghcr.io): drop adocker-compose.override.ymlsettingpull_policy: neverfor both services — Compose then fails fast if the image is absent rather than attempting a pull.
| Service | URL |
|---|---|
| Core API (REST + MCP) | http://localhost:8000 |
| Core Storage API | http://localhost:8002 |
| PostgreSQL (pgvector) | localhost:5432 |
| Redis | localhost:6379 |
3. Verify
curl http://localhost:8000/api/v1/health
# {"status":"ok","storage":"connected","redis":"connected","event_bus":"ok"}
4. Write and search
# Write a memory (standalone mode — no API key needed)
curl -X POST http://localhost:8000/api/v1/memories \
-H "X-API-Key: standalone" \
-H "Content-Type: application/json" \
-d '{"tenant_id": "default", "content": "Our auth service uses JWT with 15-minute expiry."}'
# Search for it
curl -X POST http://localhost:8000/api/v1/search \
-H "X-API-Key: standalone" \
-H "Content-Type: application/json" \
-d '{"tenant_id": "default", "query": "authentication token lifetime"}'
The write response carries an LLM-inferred memory_type, title, summary, tags, status, and a weight (the importance score) — all derived from a single content field. On the default fast-write path, enrichment is applied asynchronously: the immediate response is marked enrichment_pending and the inferred fields populate within moments.
POST /search returns matches under an items array, each entry the full memory plus a similarity score:
{
"items": [
{
"id": "…",
"agent_id": "mcp-agent",
"memory_type": "fact",
"title": "Auth service uses JWT with 15-minute expiry",
"similarity": 0.47,
"visibility": "scope_team",
"status": "active"
}
]
}
Embedding is asynchronous too, so a just-written memory may not surface in semantic search for a moment after the write returns (watch metadata.embedding_pending); the non-semantic GET /memories list shows it immediately.
⭐ If MemClaw just worked for you, star the repo — it's how other fleet builders find us, and it shapes how much time we can invest in the OSS edition.
Auth modes
OSS supports three auth paths. Pick one and add it to your .env, then docker compose up -d to restart.
Standalone — single-tenant (tenant_id="default"), simplest for local / self-install:
IS_STANDALONE=true
No API key required for REST. MCP still expects a non-empty X-API-Key header — any value works.
Pair Standalone mode with
--profile embed-local(seedocs/local-embedder.md) for a fully self-contained deployment: no admin keys, no external API calls, all embeddings computed locally. Useful for offline / air-gapped environments and personal-laptop installs.
Admin key — multi-tenant with full access:
ADMIN_API_KEY=your-long-random-admin-key
Pass X-API-Key: your-long-random-admin-key and include tenant_id in request bodies / query params.
Shared gate — for network-exposed OSS deployments:
MEMCLAW_API_KEY=your-shared-key
Clients send X-API-Key: your-shared-key plus X-Tenant-ID: <tenant>.
See AGENT-INSTALL.md for the full agent self-install walkthrough.
Running tests
# Unit tests (no DB needed)
pytest tests/ -m "unit"
# All tests (requires PostgreSQL)
docker compose up -d db
pytest tests/ -m "not benchmark"
# Smoke test against live API (~30s, auto-cleanup)
python scripts/smoke_test.py --url http://localhost:8000 --api-key <admin-key>
OpenClaw Plugin
Already running an OpenClaw fleet? Install MemClaw as a plugin against either the managed platform or your self-hosted stack:
# Point at whichever URL hosts your MemClaw API
export MEMCLAW_URL=https://memclaw.net # managed
# or: export MEMCLAW_URL=http://localhost:8000 # self-hosted
export MEMCLAW_KEY=your-key # `standalone` works in self-hosted standalone mode
export MEMCLAW_FLEET=my-fleet
curl -sf -H "X-API-Key: $MEMCLAW_KEY" \
"$MEMCLAW_URL/api/v1/install-plugin?fleet_id=$MEMCLAW_FLEET&api_url=$MEMCLAW_URL" | bash
# Restart the gateway to load the plugin
openclaw gateway restart
The plugin claims the OpenClaw memory slot (replacing memory-core) and exposes the same 12 MCP tools. Full setup, agent prompts, and trust levels: static/docs/integration-guide.md.
Python client
Talk to any MemClaw deployment (managed or self-hosted) from Python:
pip install memclaw-client
from memclaw_client import MemClaw
mc = MemClaw("mc_xxx", tenant_id="my-team", agent_id="my-agent")
mc.write("Q3 revenue target is $4M, set on 2026-04-15.")
print(mc.recall("Q3 revenue target").summary)
A thin wrapper over the REST API — see clients/python/ for the full client.
TypeScript client
Same, from TypeScript / JavaScript (Node 18+, zero dependencies):
npm install @caura/memclaw-client
import { MemClaw } from "@caura/memclaw-client";
const mc = new MemClaw("mc_xxx", { tenantId: "my-team", agentId: "my-agent" });
await mc.write("Q3 revenue target is $4M, set on 2026-04-15.");
console.log((await mc.recall("Q3 revenue target")).summary);
See clients/typescript/ for the full client.
Features
Governance
- Tenant isolation — row-level database separation per tenant; PII auto-detected and flagged on every write (surfaced in memory metadata as
contains_pii/pii_types) - Visibility scopes — every memory is stamped at write time:
scope_agent(private),scope_team(fleet-wide, default), orscope_org(cross-fleet). Cross-fleet recall is permissioned, not open - Agent trust tiers — four levels control cross-fleet reads, writes, and deletes. Agents are either provisioned atomically via
POST /admin/agent-keys/provision(recommended — mints key + row + trust + fleet in one call) or auto-registered on first write (legacy fallback) - Full audit log — every write, delete, and transition logged with tenant and scope context
Memory Pipeline
- Single-pass LLM enrichment — every write auto-classifies into one of 14 memory types, generates title/summary/tags, scores importance, flags PII, and extracts entities — from a single
contentfield - Hybrid search — pgvector semantic similarity + full-text keyword matching + knowledge graph expansion (up to 2 hops), ranked by composite score of similarity, importance, freshness, and graph boost
- Live knowledge graph — people, orgs, locations, and concepts extracted into entities and relations on every write. Semantic entity resolution (>0.85 cosine) auto-merges duplicates
- Contradiction detection — RDF triple comparison + LLM semantic analysis detects conflicting memories and automatically supersedes them, with full contradiction chain tracking
Self-Improving Memory
- Outcome-based learning (Karpathy Loop) — agents report success/failure after acting on recalled memories; the system reinforces what works and auto-generates preventive
rule-type memories on failure - Crystallization — LLM merges near-duplicate memories into canonical atomic facts with full provenance; 8-status lifecycle automation retires stale data
- Per-agent retrieval tuning — each agent optimizes its own retrieval profile (top_k, min_similarity, graph_max_hops, blend weights) from feedback, so search quality compounds with every interaction
Integrations
- MCP server — built-in Model Context Protocol at
/mcp(Streamable HTTP). Connect Claude Desktop, Claude Code, Cursor, Windsurf, or any MCP client with a URL and API key - Multi-provider LLM — primary + fallback provider chain per tenant (OpenAI, Gemini, Anthropic, OpenRouter) with platform defaults for zero-config tenants
- Document store — structured JSONB collections alongside semantic memories for exact-field lookups (customer records, config, task lists)
How MemClaw compares
Accuracy benchmarks cluster the leading tools in a narrow band (see Performance). Where the field actually diverges is fleet capability and governance:
| Capability | MemClaw | Mem0 | Zep | Letta |
|---|---|---|---|---|
| Multi-fleet support | ✅ | ❌ | ❌ | ❌ |
| Agent trust tiers + keystone policies | ✅ | ❌ | ❌ | ❌ |
| Cross-vendor memory sharing | ✅ | ❌ | ❌ | ❌ |
| Contradiction detection + supersession | ✅ | ❌ | ❌ | ❌ |
| Per-agent retrieval tuning | ✅ | ❌ | ❌ | ❌ |
| PII detection & flagging | ✅ | ❌ | ✅ | ❌ |
| Audit trail / provenance | ✅ | ❌ | ⚠️ partial | ❌ |
| Knowledge graph (auto-extracted) | ✅ | ⚠️ | ✅ | ❌ |
| MCP-native | ✅ | ✅ | ✅ | ⚠️ |
| OSS license | Apache 2.0 | Apache 2.0 | Apache 2.0 | Apache 2.0 |
Mem0, Zep, and Letta are solid projects for single-agent memory. MemClaw's lane is governed memory across agent fleets — multiple agents, teams, and vendors on one auditable memory plane. Comparison reflects our reading of public docs as of June 2026 — corrections welcome via issue or PR.
Performance
Benchmarked against the two most-cited public agent-memory benchmarks. Full results, methodology, and how to reproduce them live in BENCHMARKS.md; operator-scale context is in docs/performance.md; the full write-up is on the blog.
| LoCoMo | LongMemEval | Search latency | |
|---|---|---|---|
| Accuracy (LLM-judge) | 77.6% | 72.5% | — |
| Token savings vs full context | 96.6% | 98.2% | — |
| Latency | — | — | 23 ms p50 · 27 ms p95 |
Accuracy sits inside the leading cluster across the field (Mem0, Zep, MemClaw — scores cluster in a narrow band). The axes we push hardest are latency and token efficiency, because those are the ones that compound as agent count grows — a few hundred ms of search latency disappears behind one LLM call, but bills millions of times a day across a fleet.
Single-agent benchmarks can't measure cross-agent recall, outcome propagation between agents, fleet-scoped visibility, or governance-aware retrieval. Those are the questions that decide whether a memory system is deployable inside a company. See
docs/performance.md.
Source: Fast, Token-Efficient, and Built for Fleets (2026-04-19).
MCP (Model Context Protocol)
Add MemClaw to any MCP client with one config block.
Self-hosted (localhost):
{
"mcpServers": {
"memclaw": {
"url": "http://localhost:8000/mcp",
"headers": { "X-API-Key": "standalone" }
}
}
}
Managed platform (memclaw.net):
{
"mcpServers": {
"memclaw": {
"url": "https://memclaw.net/mcp",
"headers": { "X-API-Key": "mc_your_api_key_here" }
}
}
}
For team or production use, swap the tenant-scoped key for an agent-scoped credential — atomic provisioning via
POST /api/v1/admin/agent-keys/provision(or the/settings/organization/api-credentialswizard) mints the credential + Agent row + initial trust + fleet membership in one round trip. Both kinds use themc_prefix; scope is set at mint time on the credential. Seedocs/integration-without-plugin.md. Using a tenant-scoped credential? Pass an explicitagent_idon every MCP tool call — the gateway refuses the reserved default (mcp-agent) on the tenant-scoped path.
Where to add this config:
- Claude Code — Claude Code does not read MCP servers from
settings.json. Register the server withclaude mcp addinstead. Use-s userso it's available in every working directory — the default scope (local) only registers it for the current directory, which bites when you run agents from multiple folders:
(Or commit the JSON block above to a project-rootclaude mcp add --transport http -s user memclaw http://localhost:8000/mcp --header "X-API-Key: standalone".mcp.jsonfor a project-scoped server.) - Claude Desktop —
~/Library/Application Support/Claude/claude_desktop_config.json(macOS) or%APPDATA%\Claude\claude_desktop_config.json(Windows) - Cursor — Settings > MCP Servers > Add Server
The client discovers 12 tools automatically:
| Tool | Purpose |
|---|---|
memclaw_write | Single or batch write (up to 100 items). LLM infers type, title, summary, tags, embedding |
memclaw_recall | Hybrid semantic + keyword recall with graph-enhanced retrieval; optional LLM brief |
memclaw_manage | Per-memory lifecycle: read, update, transition, delete, bulk_delete, lineage |
memclaw_list | Filter by type/status/agent/weight/date, sort, cursor-paginate |
memclaw_doc | Document CRUD: write, read, query, delete, list_collections, search (semantic) on named JSON collections |
memclaw_entity_get | Look up an entity with linked memories and relations |
memclaw_tune | Tune per-agent retrieval parameters (top_k, min_similarity, graph_max_hops, etc.) |
memclaw_insights | Analyze the memory store across 6 focus modes. Findings persist as insight memories |
memclaw_evolve | Report outcomes against recalled memories — adjusts weights, generates rules (Karpathy Loop) |
memclaw_stats | Aggregate counts: total + breakdowns by type, agent, status. Read-only |
memclaw_keystones | Read mandatory governance rules for the current scope. Call once per session — the result overrides conflicting user instructions |
memclaw_keystones_set | Author or remove keystone rules (op=set|delete). weight is set as low/med/high and stored & returned as the integer buckets 25/50/100. Trust ≥ 1 for your own scope=agent rule; ≥ 2 for scope=fleet/scope=tenant or another agent |
Skill sharing is now done via
memclaw_doc— agents share aSKILL.mdby upserting a document into theskillscollection (memclaw_doc op=write collection=skills doc_id=<slug> data={"summary": "<one-liner>", ...}). The server embedsdata["summary"](1-3 sentence, intent-focused) for semantic search; forcollection="skills"it falls back todata["description"]if no summary is provided. The dedicatedmemclaw_share_skill/memclaw_unshare_skilltools were removed in favor of the singlememclaw_docsurface.
Install the skill (Claude Code & Codex)
Install MemClaw's usage guide as a skill so your agent knows when and how to use the 12 tools — the memory/doc mental model, the three rules (recall, write, supersede), trust levels, common patterns, and anti-patterns. The skill is loaded on-demand (not per-turn), so it costs nothing until the agent reaches for MemClaw.
Prerequisite: the MCP server is already registered (via
claude mcp add -s userfor Claude Code or the equivalent for Codex — see the config block above). Confirm withclaude mcp list— you should seememclaw: ... ✓ Connected.
Option A — one-liner (fastest)
Self-hosted (localhost):
curl -s "http://localhost:8000/api/v1/install-skill" | bash
Managed platform:
curl -s "https://memclaw.net/api/v1/install-skill" | bash
Option B — download, inspect, run (recommended for agents)
Automated agents (Claude Code, Codex) may refuse curl | bash for
safety. Two-step install lets them audit the script first:
curl -s "http://localhost:8000/api/v1/install-skill" > /tmp/install-memclaw-skill.sh
less /tmp/install-memclaw-skill.sh # review — it only does mkdir + curl + write
bash /tmp/install-memclaw-skill.sh
Options
| Query param | Effect |
|---|---|
| (none) | Install for both Claude Code and Codex (default) |
?agent=claude-code | Only Claude Code → ~/.claude/skills/memclaw/SKILL.md |
?agent=codex | Only Codex → ~/.agents/skills/memclaw/SKILL.md |
Verify
ls -la ~/.claude/skills/memclaw/SKILL.md # Claude Code
ls -la ~/.agents/skills/memclaw/SKILL.md # Codex
Restart your agent after installing — skills are loaded at startup. Re-run the installer any time to pull the latest version.
OpenClaw-plugin users get the skill automatically when the plugin installs; skip this step.
Deployment
The recommended way to run MemClaw is via Docker Compose (see Quick Start). This gives you a production-ready PostgreSQL + pgvector + Redis + API stack with a single command.
Published container images
Each release publishes multi-arch (linux/amd64, linux/arm64) images to GitHub Container Registry:
ghcr.io/caura-ai/caura-memclaw-core-api:v2.5.0
ghcr.io/caura-ai/caura-memclaw-core-storage-api:v2.5.0
Tags follow SemVer with floating aliases — :v1, :v1.0, :v1.0.0, plus :latest for the latest stable release. Pull them in your own compose file or Kubernetes manifests instead of building from source.
Manual deployment (without Docker)
The core-api/ service is a standard FastAPI app that runs under any ASGI server (uvicorn, hypercorn). Requirements:
- Python 3.12+
- PostgreSQL 16+ with the
pgvectorextension - Redis (optional — falls back to in-memory cache if unavailable)
uvicorn core_api.app:app --host 0.0.0.0 --port 8000 --workers 2
Deployment topologies
MemClaw ships with two operational modes for the storage layer. Single-node (default) is what you get from Docker Compose, pip install, or any fresh deploy — one core-storage-api instance serves both reads and writes. This is the right choice for any deployment that isn't seeing sustained 100+ writes/sec.
The reader/writer split is an opt-in topology for high-write-rate deploys that want to scale reads independently of writes — e.g. by pointing read traffic at a Postgres streaming replica. Enabling it means running two core-storage-api services with different roles and pointing core-api at both:
- Set
CORE_STORAGE_ROLE=writeron the write-serving instance;=readeron the read-serving instance(s). - Set
CORE_STORAGE_READ_URLoncore-apito the reader service URL. LeaveCORE_STORAGE_API_URLpointing at the writer. READ_DATABASE_URLon eachcore-storage-apican point at a read replica if you have one.
Defaults: CORE_STORAGE_ROLE=hybrid and CORE_STORAGE_READ_URL="" — both null-safe, so single-node deploys need zero configuration to get the legacy single-service behavior.
Upgrading from v1.x
⚠️ v2.0.0 ships a destructive schema migration. If your installation is on v1.x and has any memories already stored, follow this procedure carefully — the migration NULLs every existing embedding to widen the pgvector column from 768 → 1024 dim. The application is designed to refuse the migration automatically; you must opt in.
What changes
- Default embedder model:
BAAI/bge-m3(was: OpenAItext-embedding-3-small). Self-hosted via the newteiprofile in docker-compose; documented indocs/local-embedder.md. - pgvector schema dim:
vector(1024)(was:vector(768)). - Existing embeddings on
memories.embedding,entities.name_embedding, anddocuments.embeddingare NULLed by alembic revision012_vector_dim_1024. Re-embedding is required; until rows are re-embedded, semantic search returns no results for those rows.
Procedure (OSS, docker-compose)
-
Stop the stack so no writes happen during migration:
docker compose down -
Snapshot the database. A
pg_dumpis the safest fallback. Replace<container>with the running PostgreSQL container name (typicallycaura-memclaw-db-1):docker compose up -d db # bring just the DB back docker exec <container> pg_dump -U memclaw memclaw > backup-pre-v2.sql docker compose down -
Pull the new image and start with the migration opt-in env set. The gate enforces an explicit opt-in because the migration is destructive on a populated DB:
docker compose pull MEMCLAW_RUN_DESTRUCTIVE_MIGRATIONS=true docker compose up -dThe
core-storage-apicontainer will runalembic upgrade headon startup. The migration runs in seconds-to-minutes for typical OSS workloads. -
Verify migration completed. Look for the line
Database initialization completein thecore-storage-apilogs:docker compose logs core-storage-api | grep -i "alembic\|migration" -
Re-embed your data. Two paths:
- Lazy (zero action): the application re-embeds rows on next read or write that touches them. Search will return empty results for cold rows until they are touched. Acceptable for low-traffic personal deployments.
- Eager (recommended): run the bundled backfill CLI. It walks every
memory and entity with a NULL embedding and re-embeds via the configured
provider. Idempotent — safe to re-run. First do a dry-run to estimate
scope:
Then the real run:docker compose run --rm core-storage-api \ python -m core_storage_api.scripts.backfill_embeddings --dry-run
Optional knobs:docker compose run --rm core-storage-api \ python -m core_storage_api.scripts.backfill_embeddings--tenant-id <id>(per-tenant cutover),--batch-size N,--max-inflight N,--only-table memories|entities. Documents are NOT covered (their embed-source field is per-row JSON, not a fixed column); re-write any embedded documents to refresh them. - Eager (event-driven, recommended for multi-tenant production): if you
run the
core-workerservice, drive the existingEMBED_REQUESTEDconsumer instead. The CLI scansWHERE embedding IS NULLand publishes one event per row, inheriting per-tenant concurrency + retry + DLQ:
Same knobs as the standalone script (docker compose run --rm core-worker \ python -m core_worker.cli backfill-embeddings --dry-run docker compose run --rm core-worker \ python -m core_worker.cli backfill-embeddings--tenant-id,--batch-size,--max-inflight,--dry-run). Currently coversmemoriesonly.
-
Once stable, unset
MEMCLAW_RUN_DESTRUCTIVE_MIGRATIONSso subsequentupcommands don't carry the opt-in:unset MEMCLAW_RUN_DESTRUCTIVE_MIGRATIONS # if exported in the shell # or remove the line from your .env file
What if I skip the opt-in?
core-storage-api will refuse to start, with a clear error message reporting
how many rows would be NULLed. The container exits non-zero; the rest of the
stack stays healthy. No data is touched. Set the env var and retry.
Rolling back
The migration has a symmetric downgrade(). To revert, set the env var and
explicitly downgrade:
docker compose run --rm \
-e MEMCLAW_RUN_DESTRUCTIVE_MIGRATIONS=true \
core-storage-api alembic downgrade 011
This NULLs any 1024-dim embeddings written since the upgrade and widens the
columns back to vector(768). The same data-loss tradeoff applies in reverse.
For untouched-since-upgrade installations, the simpler recovery is to restore
the snapshot from step 2.
v1.x → v2.x compatibility for client code
No public API changes. Code that reads memory embeddings via the search/recall
endpoints is unaffected. Client code that hardcodes 768 for vector lengths
should be updated to read VECTOR_DIM from common.constants.
API Reference
All routes are versioned under /api/v1/. Interactive Swagger docs at /api/docs.
Memory endpoints
| Endpoint | Method | Description |
|---|---|---|
/memories | POST | Write a memory. LLM enrichment + embedding + entity extraction + contradiction detection. "persist": false for extract-only preview |
/memories/bulk | POST | Write up to 100 memories. Batches embeddings, parallelizes enrichment, single transaction. Requires X-Bulk-Attempt-Id header (per-attempt idempotency); a retry with the same id resolves committed rows as duplicate_attempt instead of duplicating. Returns 200 (clean / all-error) or 207 Multi-Status (mixed) — read per-item status |
/memories | GET | List memories (filter by type, status, agent; paginate) |
/memories/{id} | GET | Full memory detail (embedding stats, entity links, RDF triple, temporal bounds) |
/memories/{id} | PATCH | Update content or metadata. Re-embeds if content changes |
/memories/{id} | DELETE | Soft delete (sets status to deleted) |
/memories/{id}/status | PATCH | Update lifecycle status |
/memories/{id}/contradictions | GET | View contradiction chain |
/memories | DELETE | Bulk soft-delete |
/memories/stats | GET | Counts by type, agent, and status |
/search | POST | Hybrid semantic + keyword search with graph-enhanced retrieval |
/recall | POST | Search + LLM summarization — returns context paragraph + source memories |
/ingest/preview | POST | Extract 5-20 atomic facts from a URL or text (no writes) |
/ingest/commit | POST | Write previewed facts as memories |
Knowledge graph endpoints
| Endpoint | Method | Description |
|---|---|---|
/entities | GET | List entities (filter by type, search) |
/entities/upsert | POST | Create or update entity |
/entities/{id} | GET | Entity detail with relations and linked memories |
/relations/upsert | POST | Create or update relation |
/graph | GET | Full knowledge graph (entities + relations) |
Evolve, Insights, Agents, Crystallizer, Documents, Fleet, Admin
Karpathy Loop / Evolve
| Endpoint | Method | Description |
|---|---|---|
/evolve/report | POST | Report an outcome (success/failure/partial) against recalled memories |
Insights
| Endpoint | Method | Description |
|---|---|---|
/insights/generate | POST | LLM-powered analysis. Focus: contradictions, failures, stale, divergence, patterns, discover |
Agents
| Endpoint | Method | Description |
|---|---|---|
/agents | GET | List registered agents with trust levels |
/agents/{id} | GET | Single agent detail |
/agents/{id}/trust | PATCH | Set trust level (0-3) |
Memory Crystallizer
| Endpoint | Method | Description |
|---|---|---|
/crystallize | POST | Trigger crystallization for a tenant |
/crystallize/all | POST | Trigger for all tenants (admin key, nightly) |
/crystallize/reports | GET | List crystallization reports |
/crystallize/latest | GET | Most recent completed report |
Documents
| Endpoint | Method | Description |
|---|---|---|
/documents | POST | Store or update a structured JSON document |
/documents/{id} | GET | Retrieve document by ID |
/documents/query | POST | Query by field equality filters |
/documents/{id} | DELETE | Delete a document |
Fleet
| Endpoint | Method | Description |
|---|---|---|
/fleet/heartbeat | POST | Plugin heartbeat — upserts node status, returns pending commands |
/fleet/nodes | GET | List fleet nodes with status (online/stale/offline) |
/fleet/commands | POST | Queue a command for a node |
/fleet/commands | GET | List command history |
Admin + System
| Endpoint | Method | Description |
|---|---|---|
/health | GET | Liveness check |
/version | GET | Current version |
/tool-descriptions | GET | Canonical MCP tool descriptions |
/admin/tenants | GET | List all tenants (admin key) |
/admin/fleets | GET | List fleets across all tenants (admin key) |
/admin/memories | GET | List memories across all tenants with filters (admin key) |
/admin/memories/stats | GET | Memory counts by tenant/type/status (admin key) |
/settings | GET / PUT | Per-tenant configuration |
/audit-log | GET | Audit log entries |
/mcp | POST | MCP Streamable HTTP endpoint (mounted at app root, NOT under /api/v1) |
Auth: X-API-Key header for all endpoints. Admin endpoints require the admin key. Public (no auth): /api/v1/health, /api/v1/version, /api/v1/tool-descriptions.
Gateway-injected headers (trusted only behind the enterprise gateway):
| Header | Effect |
|---|---|
X-Agent-ID | Scopes the request to this agent |
X-Org-Read-Only: true | Read-only mode — creates/updates return 403 |
X-Tenant-ID | Tenant identity when using the shared MEMCLAW_API_KEY gate |
These headers are honored unconditionally — core-api must not be network-exposed without a gateway that strips them from untrusted callers.
Rate limiting (managed platform)
These limits apply to the managed platform at memclaw.net. In the OSS edition, rate limiting is a no-op — see the Rate limiting section below.
| Scope | Limit |
|---|---|
| Memory writes | 60 req/min per API key |
| Memory searches | 120 req/min per API key |
| General reads | 300 req/min per API key |
| Auth endpoints | 10 req/min per IP |
| Global DDoS floor | 1000 req/min per IP |
Exceeded limits return HTTP 429 with a Retry-After header.
Configuration
All configuration is via environment variables or .env. See .env.example for the full list.
Migrating from a pre-1.0 deploy? The legacy
ALLOYDB_*env var names are still accepted as aliases —POSTGRES_HOSTfalls back toALLOYDB_HOST, etc. Aliases will be dropped in a future major release.
| Variable | Default | Description |
|---|---|---|
POSTGRES_HOST | 127.0.0.1 | Database host |
POSTGRES_PORT | 5432 | Database port |
POSTGRES_USER | memclaw | Database user |
POSTGRES_PASSWORD | changeme | Database password |
POSTGRES_DB | memclaw | Database name |
POSTGRES_USE_IAM_AUTH | false | Use GCP IAM for DB auth (managed Postgres on GCP only) |
ADMIN_API_KEY | (empty) | Admin API key — bypasses tenant enforcement |
EMBEDDING_PROVIDER | openai | openai, local, or fake |
ENTITY_EXTRACTION_PROVIDER | openai | openai, gemini, anthropic, openrouter, fake, or none |
ENTITY_EXTRACTION_MODEL | gpt-5.4-nano | LLM model for enrichment and entity extraction |
OPENAI_API_KEY | — | Required for OpenAI embeddings and enrichment |
USE_LLM_FOR_MEMORY_CREATION | true | LLM auto-classifies type, weight, title, summary, tags on write |
ANTHROPIC_API_KEY | — | Required for Anthropic |
OPENROUTER_API_KEY | — | Required for OpenRouter |
GEMINI_API_KEY | — | Required for Gemini (Developer API, from AI Studio) |
CORS_ORIGINS | http://localhost:3000 | Comma-separated allowed CORS origins |
ENVIRONMENT | development | development or production |
SETTINGS_ENCRYPTION_KEY | — | Fernet key for encrypting tenant settings. Required in production |
PLATFORM_LLM_PROVIDER | (empty) | Platform-default LLM: openai, vertex, or empty to disable |
PLATFORM_LLM_MODEL | (empty) | Model override (e.g. gpt-5.4-nano, gemini-3.1-flash-lite-preview) |
PLATFORM_LLM_API_KEY | — | OpenAI API key for the platform LLM singleton |
PLATFORM_LLM_GCP_PROJECT_ID | — | GCP project for platform Vertex LLM |
PLATFORM_LLM_GCP_LOCATION | us-central1 | GCP region for platform Vertex LLM |
PLATFORM_EMBEDDING_PROVIDER | (empty) | Platform-default embeddings: openai or empty to disable |
PLATFORM_EMBEDDING_MODEL | (empty) | Embedding model override (e.g. text-embedding-3-small) |
PLATFORM_EMBEDDING_API_KEY | — | OpenAI API key for platform embeddings |
Project structure
memclaw/
├── core-api/ # Main FastAPI service
│ └── src/core_api/
│ ├── app.py # FastAPI app, lifespan, middleware
│ ├── mcp_server.py # MCP server (Streamable HTTP, 12 tools)
│ ├── constants.py # Tool descriptions, limits, ranking params
│ ├── config.py # Settings (env vars)
│ ├── auth.py # API key + JWT auth, tenant enforcement
│ ├── routes/ # Route handlers
│ ├── services/ # Business logic
│ ├── providers/ # LLM/embedding abstraction + fallback
│ ├── pipeline/ # Composable write/search pipelines
│ └── tools/ # MCP tool implementations
│
├── core-storage-api/ # PostgreSQL CRUD microservice
│ └── src/core_storage_api/
│ ├── routers/ # Memory, entity, document, fleet CRUD
│ ├── services/ # ORM operations
│ └── database/ # SQLAlchemy models, Alembic migrations
│
├── plugin/ # OpenClaw plugin (TypeScript)
│ └── src/
│ ├── tools.ts # Tool implementations
│ ├── agent-auth.ts # Per-agent credentials (agent-scoped mc_ keys)
│ ├── context-engine.ts # Auto-read/write lifecycle
│ ├── heartbeat.ts # 60s heartbeat → MemClaw API
│ └── educate.ts # Agent education delivery
│
├── common/ # Shared SQLAlchemy ORM models and constants
├── tests/ # Test suite
├── scripts/ # Smoke tests, benchmarks, export tools
├── docker-compose.yml # Production-like stack
├── docker-compose.dev.yml # Dev stack
└── .env.example # Full configuration reference
Latency benchmarks
Typical results on a single-instance deployment (OpenAI embeddings + GPT-5.4 Nano):
| Operation | Mean | P50 | P95 |
|---|---|---|---|
memclaw_write | ~2000ms | ~2000ms | ~2300ms |
memclaw_recall | ~650ms | ~640ms | ~670ms |
memclaw_recall (with include_brief=true) | ~1300ms | ~1200ms | ~2100ms |
Write latency is dominated by LLM enrichment. Recall latency by the embedding API call.
python scripts/latency_test.py --url http://localhost:8000 --api-key <admin-key> --runs 20
Public API & Stability
MemClaw v1.x follows SemVer 2.0.0. The surfaces below are stable; everything else is internal and may change in any release.
Stable surfaces
MCP tools (12)
The MCP server is mounted at /mcp. Tool names, parameter names, and the documented op-dispatch values are stable.
| Tool | Purpose |
|---|---|
memclaw_recall | Hybrid semantic + keyword search over memories, with optional LLM-summarised brief. |
memclaw_write | Single or batch (≤100) memory write; auto-enriched with type, title, summary, tags. |
memclaw_manage | Per-memory lifecycle, op-dispatched: read | update | transition | delete | bulk_delete | lineage. |
memclaw_list | Non-semantic enumeration with filters, sort, cursor pagination. |
memclaw_doc | Structured-document CRUD, op-dispatched: write | read | query | delete | list_collections | search. |
memclaw_entity_get | Look up a knowledge-graph entity by UUID. |
memclaw_tune | Read/update an agent's per-search profile (top_k, fts_weight, freshness, blend, …). |
memclaw_insights | Karpathy-Loop reflection: contradictions, failures, stale, divergence, patterns, discover. |
memclaw_evolve | Karpathy-Loop feedback: record an outcome (success | failure | partial) against memories. |
memclaw_stats | Aggregate counts: total + breakdowns by type / agent / status. Read-only. |
memclaw_keystones | Read mandatory governance rules for the current scope (tenant + fleet + agent merged). Call once per session. |
memclaw_keystones_set | Author/remove keystone rules, op-dispatched: set | delete. Trust ≥ 1 for self-authored scope=agent; ≥ 2 otherwise. |
Skill sharing uses the generic
memclaw_docsurface — write/read/query/search/delete oncollection="skills". The server validates the slug and embedsdata["summary"]for semantic discovery (with a back-compat fallback todata["description"]for skills).
REST endpoints
All paths are prefixed with /api/v1 unless noted. Request and response shapes documented in the OpenAPI schema at /openapi.json are part of the contract.
| Area | Endpoints |
|---|---|
| Memory | GET/POST /memories, PATCH /memories/{id}, DELETE /memories/{id}, PATCH /memories/{id}/status, POST /memories/bulk, POST /memories/bulk-delete, GET /memories/stats, GET /memories/{id}, GET /memories/{id}/contradictions, POST /search, POST /recall, POST /ingest/preview, POST /ingest/commit |
| Knowledge graph | GET /entities, GET /entities/{id}, POST /entities/upsert, GET /graph, POST /relations/upsert |
| Documents | POST /documents, GET /documents, GET /documents/{id}, POST /documents/query, DELETE /documents/{id} |
| Keystones | GET /memclaw/keystones, POST /memclaw/keystones, DELETE /memclaw/keystones/{doc_id} |
| Fleet | POST /fleet/heartbeat, GET /fleet/nodes, POST /fleet/commands, GET /fleet/commands |
| Agents | GET /agents, GET /agents/{id}, PATCH /agents/{id}/trust, POST /admin/agent-keys/provision (atomic key + row + trust + fleet), GET /whoami (identity probe) |
| Insights | POST /insights/generate |
| Evolve | POST /evolve/report |
| Crystallizer | POST /crystallize, POST /crystallize/all, GET /crystallize/reports, GET /crystallize/latest |
| Settings | GET/PUT /settings |
| System | GET /health, GET /version, GET /tool-descriptions, GET /audit-log |
| MCP | POST /mcp (Streamable HTTP transport, mounted at app root) |
| Bootstrap (plugin) | GET /plugin-source, GET /plugin-source-hash, GET/POST /install-plugin, GET /install-skill, GET /skill/memclaw. Aliased under /api (no /v1) for one-line installers. |
Plugin environment variables
Read by the OpenClaw plugin. The plugin's published name (memclaw) and these variables are the public contract; the plugin's TypeScript module structure is internal.
| Var | Purpose |
|---|---|
MEMCLAW_API_URL | Base URL of the core-api server. |
MEMCLAW_API_KEY | Tenant or admin API key sent in X-API-Key. |
MEMCLAW_TENANT_ID | Optional pre-resolved tenant id; bypasses lookup. |
MEMCLAW_FLEET_ID | Default fleet id for writes/heartbeat. |
MEMCLAW_NODE_NAME | Fleet node identifier reported on heartbeat. |
MEMCLAW_AUTO_WRITE_TURNS | Auto-write turn summaries (default true). |
Server environment variables
These mirror the Configuration table above. See it for defaults.
| Group | Vars |
|---|---|
| Database | POSTGRES_HOST, POSTGRES_PORT, POSTGRES_USER, POSTGRES_PASSWORD, POSTGRES_DB, POSTGRES_USE_IAM_AUTH, POSTGRES_REQUIRE_SSL |
| Auth | ADMIN_API_KEY, MEMCLAW_API_KEY, IS_STANDALONE |
| Providers | EMBEDDING_PROVIDER, ENTITY_EXTRACTION_PROVIDER, OPENAI_API_KEY, ANTHROPIC_API_KEY, OPENROUTER_API_KEY, GEMINI_API_KEY, USE_LLM_FOR_MEMORY_CREATION |
| Runtime | CORS_ORIGINS, ENVIRONMENT, SETTINGS_ENCRYPTION_KEY, REDIS_URL |
Auth modes
| Mode | Activated by | Use case |
|---|---|---|
| Standalone | IS_STANDALONE=true | Single-tenant self-host; auth bypassed. |
| Multi-tenant admin | ADMIN_API_KEY=… | Operator key for multi-tenant deployments. |
| Shared gate | MEMCLAW_API_KEY=… | Optional shared secret required on every non-admin request. |
See AGENT-INSTALL.md for installation flows that exercise each mode.
Internal (not covered by SemVer)
Anything not listed above is internal and may change in any release without a major version bump:
- Python module layout (
core_api.middleware.*,core_api.providers.*,core_api.pipeline.*,core_api.services.*,common/*) - Database schema, table names, migration paths
- Gateway-injected HTTP headers (
X-Memclaw-Gateway,X-Tenant-ID,X-Agent-ID,X-Org-Read-Only) - Most
/api/v1/admin/*and all/api/v1/testing/*routes (the documented exception isPOST /admin/agent-keys/provision, which is part of the stable identity-bootstrap surface — see the Agents row above) - The
core-storage-apimicroservice (internal, not user-facing) - The plugin's TypeScript module structure
- API-key prefix formats — currently unified on
mc_…(with legacymca_…/mci_…aliases still accepted via back-compat); formats may continue to evolve
Reporting breaking changes
Contributors who introduce a breaking change to a stable surface must:
- Add a
BREAKING CHANGE:trailer to the commit message describing the impact and any migration steps. - Apply the
kind/breakinglabel to the pull request.
Reviewers will block merges to dev that touch a stable surface without these markers. If you are unsure whether a change is breaking, open the PR with the label and let review decide — better to over-label than ship a silent break.
Telemetry and error tracking
MemClaw supports optional Sentry integration for error tracking and performance monitoring:
- Opt-in only — set the
SENTRY_DSNenvironment variable to enable. No errors are reported unless you explicitly configure a DSN. - No usage analytics — MemClaw does not collect usage statistics, feature flags, or behavioral data.
- No phone-home — the application makes zero outbound calls unless you configure a Sentry DSN or an LLM/embedding provider.
OpenClaw Plugin
See static/docs/integration-guide.md for full plugin setup, agent system prompts, and usage examples.
Rate limiting
Rate limiting in the OSS edition is a no-op — all rate-limit decorators are identity
functions that accept every request without throttling. For production deployments exposed to
the internet, add rate limiting at your reverse proxy (nginx, Caddy, Cloudflare) or implement
application-level limiting in core-api/src/core_api/middleware/rate_limit.py.
Telemetry
MemClaw does not phone home by default. No usage data, analytics, or tracking of any kind.
If you set the SENTRY_DSN environment variable, Sentry error tracking
is enabled — crash reports and performance traces are sent to your configured Sentry project.
When SENTRY_DSN is empty (the default), Sentry is not initialized and no data leaves the
server.
Contributing
We welcome contributions! See CONTRIBUTING.md for guidelines, development setup, and how to submit PRs.
FAQ
What is MemClaw? MemClaw is open-source governed shared memory for AI agent fleets: cross-agent, cross-fleet recall with visibility scopes, trust tiers, keystone policies, audit trails, and tenant isolation enforced on every operation — plus self-improving retrieval through outcome-based learning.
How is MemClaw different from a vector database? MemClaw uses pgvector under the hood but is not a vector DB wrapper. On top of hybrid search it adds fleet orchestration, per-agent retrieval tuning, contradiction detection, an 8-status lifecycle, an auto-extracted knowledge graph, LLM enrichment on every write, row-level tenant isolation, and audit trails on every operation.
How is MemClaw different from Mem0 or Zep? Mem0 and Zep focus on memory for individual agents; accuracy benchmarks cluster all three tools in a narrow band. MemClaw is built for fleets: multiple agents across teams and vendors sharing one governed memory plane, with trust tiers, keystone policies, and cross-fleet permissions those tools don't address. See How MemClaw compares.
Does MemClaw work with Claude Desktop, Claude Code, Cursor, or Windsurf? Yes — MemClaw is MCP-native. Paste a JSON config with a URL and API key into any MCP client and 12 tools appear immediately.
Can agents from different vendors share memory? Yes — that's the point. An Anthropic agent recalls what an OpenAI agent wrote, under the same governance rules — with trust tiers and visibility scopes deciding what crosses fleet boundaries.
Is MemClaw really free? The full engine — storage, 12 MCP tools, plugin, audit trail — is Apache 2.0. Run it yourself forever. The managed platform at memclaw.net adds hosting, scaling, and enterprise governance for teams that don't want to operate infrastructure.
Who runs MemClaw in production? eToro (NASDAQ: ETOR) runs 300+ agents on MemClaw — 26,500+ memories, 1,372 shared skills, 23 ms p50 search. Case study →
License
MemClaw is licensed under the Apache License, Version 2.0.
See NOTICE for copyright and third-party attributions.
Trademarks
"MemClaw" and "Caura" are trademarks of Caura. The Apache License 2.0 grants permission to use the source code but does not grant permission to use these names, logos, or branding in a way that suggests endorsement of, or affiliation with, any derivative work. See Apache License 2.0 §6 for the full legal terms.