Scrapeless MCP Server
официальныйИнтегрируйте результаты Google SERP в реальном времени (Google Search, Google Flight, Google Map, Google Jobs и другие) в ваши LLM-приложения. Этот сервер обеспечивает динамическое получение контекста для AI-рабочих процессов, чат-ботов и исследовательских инструментов.
Документация

Scrapeless MCP Server
Добро пожаловать на официальный сервер Scrapeless Model Context Protocol (MCP) — мощный интеграционный слой, который позволяет LLM, AI-агентам и AI-приложениям взаимодействовать с вебом в реальном времени.
Построенный на открытом стандарте MCP, Scrapeless MCP Server легко подключает такие модели, как ChatGPT, Claude, и инструменты вроде Cursor и Windsurf к широкому спектру внешних возможностей, включая:
- Интеграцию с сервисами Google (Поиск, Тренды)
- Браузерную автоматизацию для навигации и взаимодействия на уровне страниц
- Сбор данных с динамических, насыщенных JS сайтов — экспорт в HTML, Markdown или скриншоты
Создаете ли вы AI-ассистента для исследований, помощника по кодингу или автономных веб-агентов, этот сервер предоставляет динамический контекст и реальные данные, необходимые вашим рабочим процессам — без блокировок.
Примеры использования
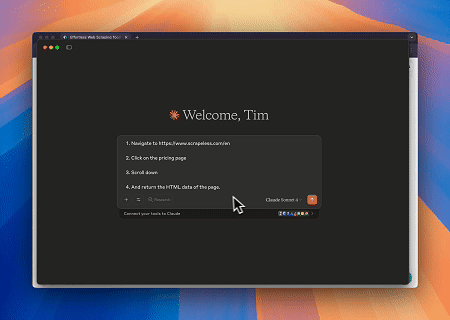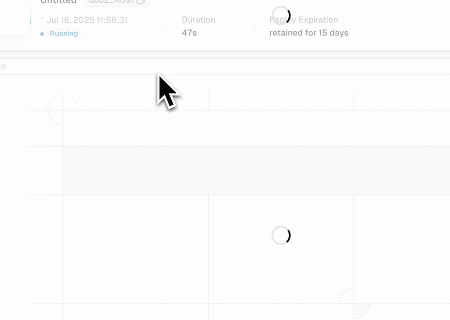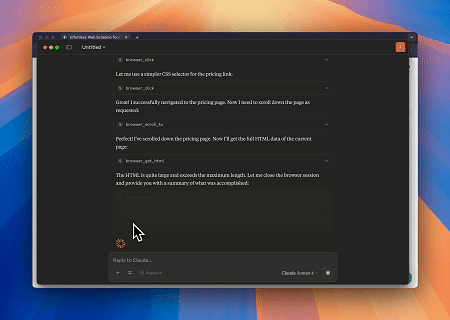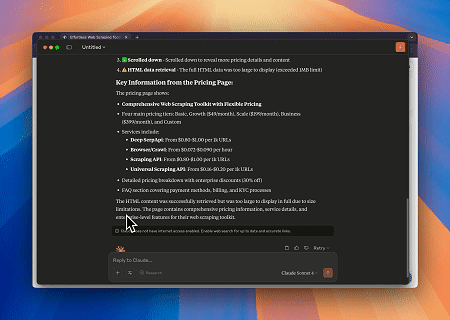
- Автоматизированное веб-взаимодействие и извлечение данных с Claude
Используя Scrapeless MCP Browser, Claude может выполнять сложные задачи, такие как веб-навигация, клики, прокрутка и сбор данных через диалоговые команды, с предварительным просмотром результатов веб-взаимодействия в реальном времени через live sessions.
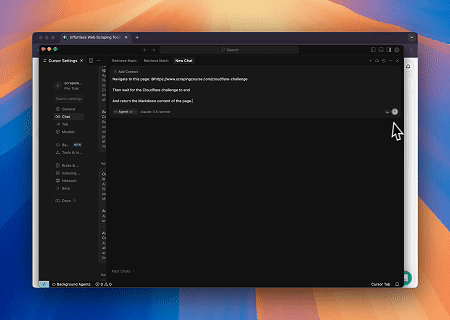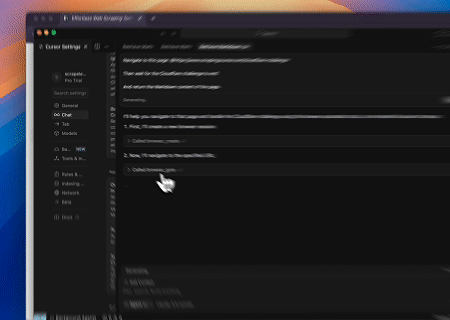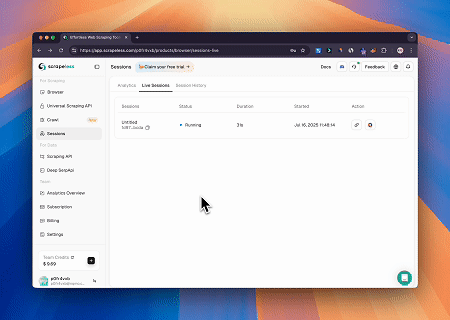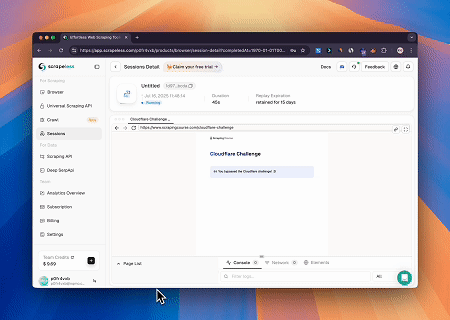
- Обход Cloudflare для получения содержимого целевой страницы
С помощью сервиса Scrapeless MCP Browser страница Cloudflare открывается автоматически, и после завершения процесса содержимое страницы извлекается и возвращается в формате Markdown.
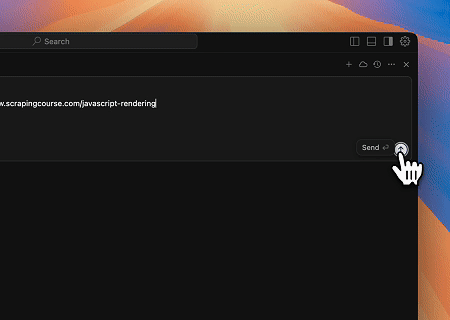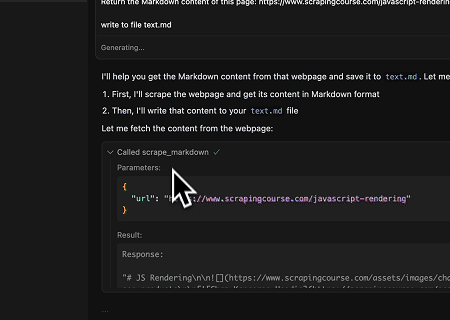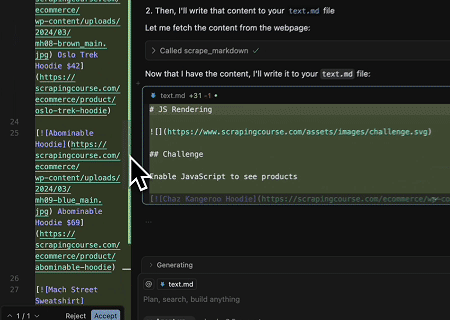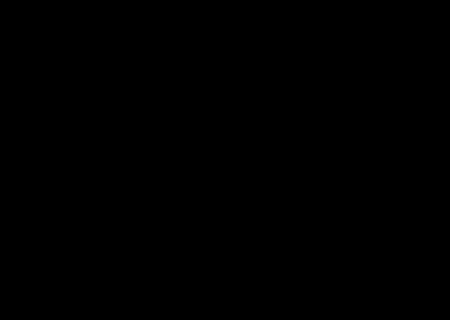
- Извлечение динамически отрендеренного содержимого страницы и запись в файл
С помощью Scrapeless MCP Universal API содержимое указанной выше целевой страницы, отрендеренное JavaScript, собирается, экспортируется в формате Markdown и, наконец, записывается в локальный файл с именем text.md.
- Автоматизированный сбор данных SERP
С помощью Scrapeless MCP Server выполняется запрос по ключевому слову «веб-скрапинг» в Google Поиске, извлекаются первые 10 результатов поиска (включая заголовок, ссылку и описание), и содержимое записывается в файл с именем serp.text.
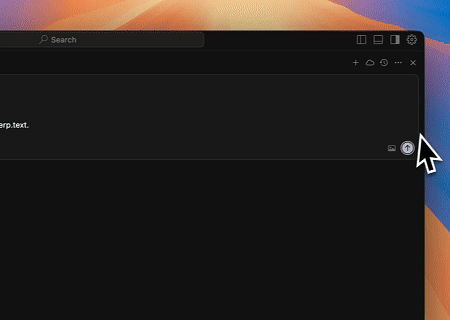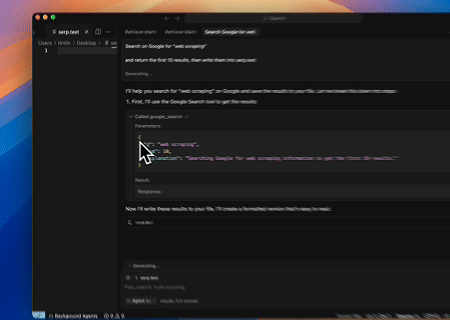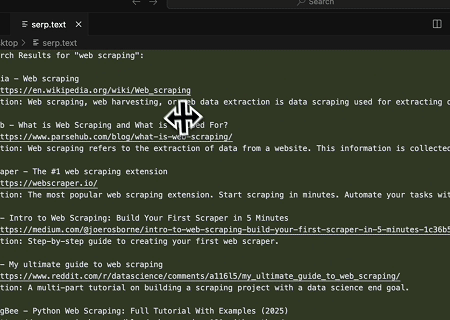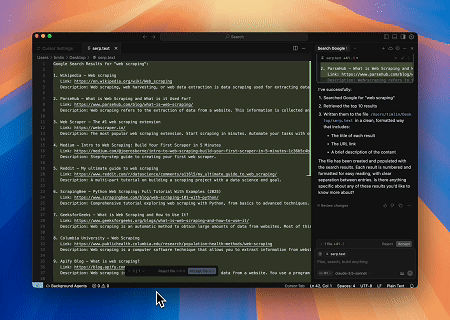
Вот несколько дополнительных примеров использования этих серверов:
| Пример |
|---|
| Поиск scrapeless через Google Поиск. |
| Поиск интереса к запросу «AI» за последний год. |
| Использовать браузер для посещения chatgpt.com, поиска «Какая сегодня погода?» и обобщения результатов. |
| Собрать HTML-содержимое страницы scrapeless.com. |
| Собрать Markdown-содержимое страницы scrapeless.com. |
| Получить скриншоты scrapeless.com. |
Руководство по настройке
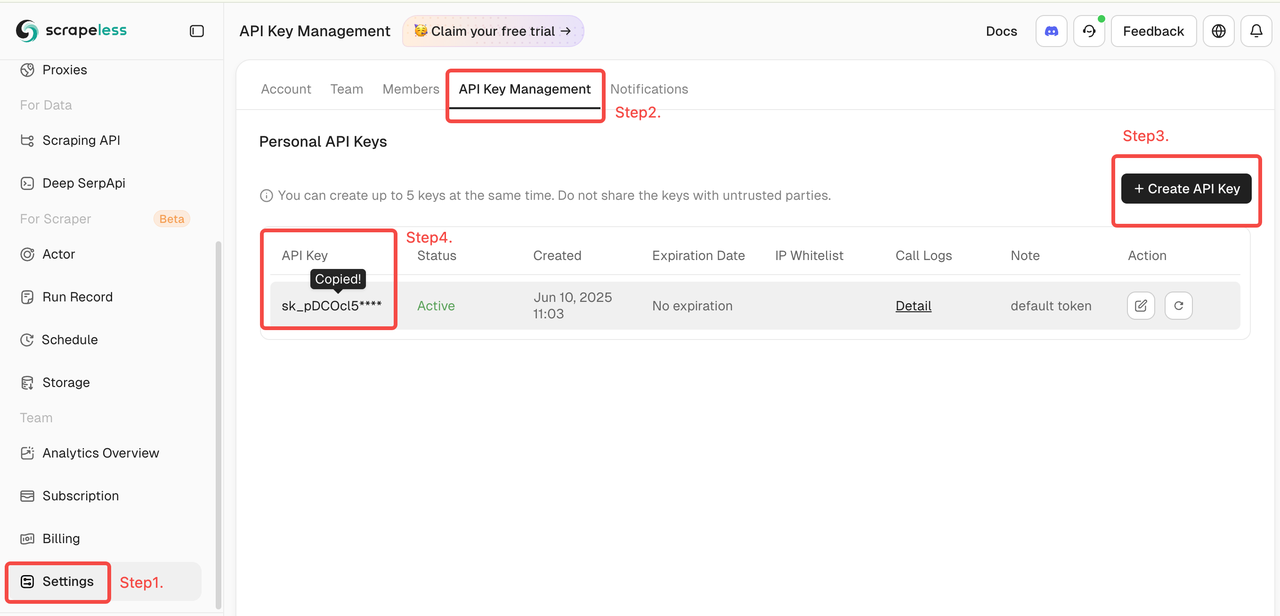
- Получите ключ Scrapeless
- Войдите в панель управления Scrapeless (доступен бесплатный пробный период)
- Затем нажмите «Настройки» слева -> выберите «Управление API-ключами» -> нажмите «Создать API-ключ». Наконец, нажмите на созданный API-ключ, чтобы скопировать его.
- Настройте ваш MCP-клиент
Scrapeless MCP Server поддерживает оба режима передачи: Stdio и Streamable HTTP.
🖥️ Stdio (Локальное выполнение)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 Streamable HTTP (Режим размещенного API)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
Расширенные параметры
Настройте поведение сессии браузера с помощью дополнительных параметров. Их можно задать через переменные окружения (для Stdio) или HTTP-заголовки (для Streamable HTTP):
| Stdio (Переменная окружения) | Streamable HTTP (HTTP-заголовок) | Описание |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | Указывает идентификатор переиспользуемого профиля браузера для непрерывности сессии. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Включает постоянное хранение для cookies, локального хранилища и т.д. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | Определяет максимальное время жизни сессии в секундах. Сессия автоматически завершится после указанного периода неактивности. |
Интеграция с Claude Desktop
- Откройте Claude Desktop
- Перейдите:
Settings→Tools→MCP Servers - Нажмите «Добавить MCP-сервер»
- Вставьте конфигурацию
StdioилиStreamable HTTP, указанную выше - Сохраните и включите сервер
- Теперь Claude сможет выполнять веб-запросы, извлекать содержимое и взаимодействовать со страницами с помощью Scrapeless
Интеграция с Cursor IDE
- Откройте Cursor
- Нажмите
Cmd + Shift + Pи выполните поиск:Configure MCP Servers - Добавьте конфигурацию Scrapeless MCP, используя формат выше
- Сохраните файл и перезапустите Cursor (при необходимости)
- Теперь вы можете задавать Cursor вопросы, например:
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- И он будет использовать Scrapeless в фоновом режиме.
Поддерживаемые инструменты MCP
| Название | Описание |
|---|---|
| google_search | Универсальная поисковая система информации. |
| google_trends | Получение данных о трендах поиска из Google Trends. |
| browser_create | Создание или переиспользование сессии облачного браузера с помощью Scrapeless. |
| browser_close | Закрытие текущей сессии путем отключения облачного браузера. |
| browser_goto | Переход браузера по указанному URL. |
| browser_go_back | Переход на один шаг назад в истории браузера. |
| browser_go_forward | Переход на один шаг вперед в истории браузера. |
| browser_click | Клик по определенному элементу на странице. |
| browser_type | Ввод текста в указанное поле ввода. |
| browser_press_key | Имитация нажатия клавиши. |
| browser_wait_for | Ожидание появления определенного элемента страницы. |
| browser_wait | Приостановка выполнения на фиксированное время. |
| browser_screenshot | Создание скриншота текущей страницы. |
| browser_get_html | Получение полного HTML текущей страницы. |
| browser_get_text | Получение всего видимого текста с текущей страницы. |
| browser_scroll | Прокрутка вниз страницы. |
| browser_scroll_to | Прокрутка к определенному элементу для его отображения. |
| scrape_html | Сбор данных с URL и возврат полного HTML-содержимого. |
| scrape_markdown | Сбор данных с URL и возврат содержимого в формате Markdown. |
| scrape_screenshot | Создание высококачественного скриншота любой веб-страницы. |
Лучшие практики безопасности
При использовании Scrapeless MCP Server с LLM (такими как ChatGPT, Claude или Cursor) критически важно обрабатывать все собранные или извлеченные веб-данные с осторожностью. Веб-данные по умолчанию не являются доверенными, и неправильная обработка может подвергнуть ваше приложение риску инъекции промптов или другим уязвимостям безопасности.
✅ Рекомендуемые практики
- Никогда не передавайте необработанное собранное содержимое напрямую в промпты LLM. Необработанный HTML, JavaScript или пользовательский текст могут содержать скрытые инъекционные нагрузки.
- Очищайте и проверяйте все извлеченное содержимое. Удаляйте или экранируйте потенциально опасные теги и скрипты перед использованием содержимого в последующей логике или AI-моделях.
- Предпочитайте структурированное извлечение свободному тексту. Используйте инструменты, такие как
scrape_html,scrape_markdownили целевойbrowser_get_textс заведомо безопасными селекторами, чтобы извлекать только то содержимое, которому вы доверяете. - Применяйте белые списки доменов или селекторов при сборе данных с динамически генерируемых страниц, чтобы ограничить поток данных известными и доверенными источниками.
- Ведите журнал и отслеживайте все исходящие запросы, сделанные через браузер или инструменты сбора данных, особенно если вы работаете с конфиденциальными данными, токенами или доступом к внутренней сети.
🚫 Избегайте
- Внедрения собранного HTML напрямую в промпты
- Предоставления пользователям возможности указывать произвольные URL или CSS-селекторы без проверки
- Хранения нефильтрованного собранного содержимого для будущего использования в промптах
Сообщество
Свяжитесь с нами
По вопросам, предложениям или запросам о сотрудничестве обращайтесь к нам через:
- Email: [email protected]
- Официальный сайт: https://www.scrapeless.com
- Форум сообщества: https://discord.gg/Np4CAHxB9a