Scrapeless MCP Server
공식실시간 Scrapeless Google SERP(Google 검색, Google 항공편, Google 지도, Google 채용 등) 결과를 LLM 애플리케이션에 통합합니다. 이 서버는 AI 워크플로우, 챗봇 및 연구 도구를 위한 동적 컨텍스트 검색을 가능하게 합니다.
문서

Scrapeless MCP 서버
공식 Scrapeless 모델 컨텍스트 프로토콜(MCP) 서버에 오신 것을 환영합니다 — LLM, AI 에이전트, AI 애플리케이션이 실시간으로 웹과 상호 작용할 수 있도록 지원하는 강력한 통합 계층입니다.
개방형 MCP 표준을 기반으로 구축된 Scrapeless MCP 서버는 ChatGPT, Claude와 같은 모델과 Cursor, Windsurf 같은 도구를 다음과 같은 다양한 외부 기능에 매끄럽게 연결합니다.
- Google 서비스 통합 (검색, 트렌드)
- 페이지 수준 탐색 및 상호 작용을 위한 브라우저 자동화
- 동적이고 JS가 많은 사이트 스크래핑 — HTML, Markdown 또는 스크린샷으로 내보내기
AI 연구 도우미, 코딩 코파일럿 또는 자율 웹 에이전트를 구축하든, 이 서버는 워크플로에 필요한 동적 컨텍스트와 실제 데이터를 차단 없이 제공합니다.
사용 예시
- Claude를 사용한 자동화된 웹 상호 작용 및 데이터 추출
Scrapeless MCP 브라우저를 사용하면 Claude가 대화형 명령을 통해 웹 탐색, 클릭, 스크롤, 스크래핑과 같은 복잡한 작업을 수행할 수 있으며, live sessions을(를) 통해 웹 상호 작용 결과를 실시간으로 미리 볼 수 있습니다.
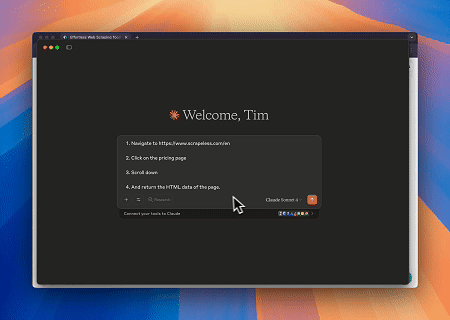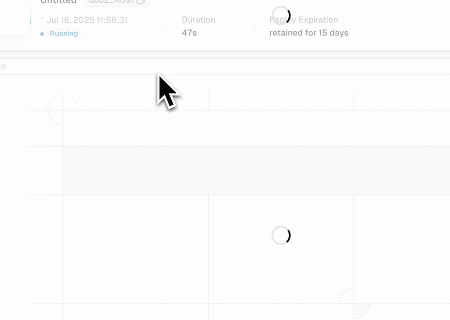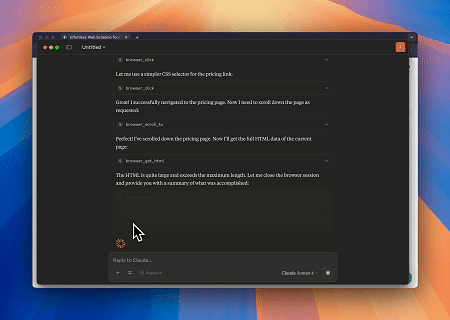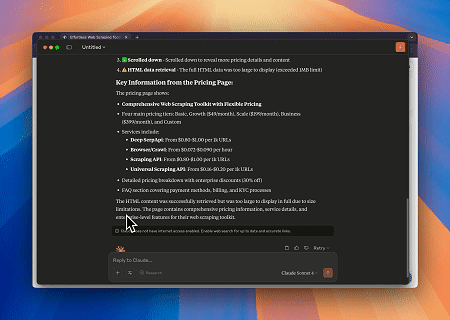
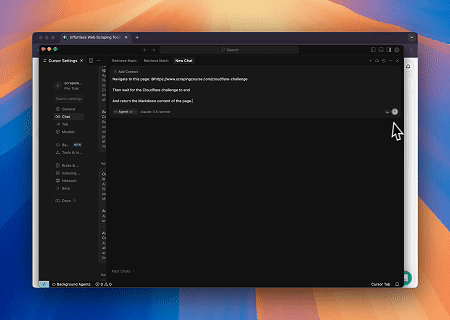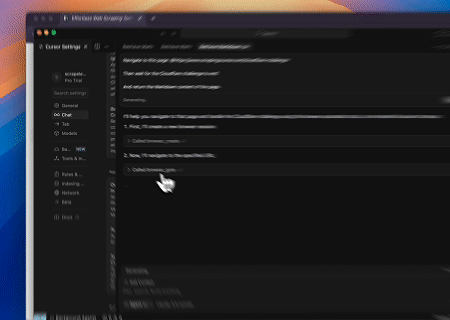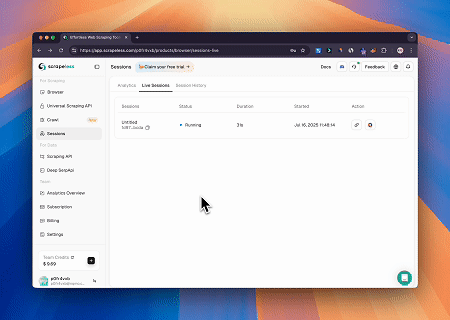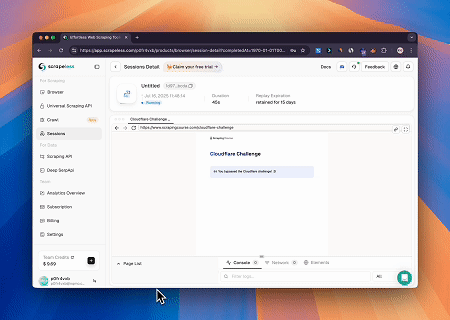
- Cloudflare 우회하여 대상 페이지 콘텐츠 가져오기
Scrapeless MCP 브라우저 서비스를 사용하면 Cloudflare 페이지에 자동으로 접근하고, 프로세스가 완료된 후 페이지 콘텐츠를 추출하여 Markdown 형식으로 반환합니다.
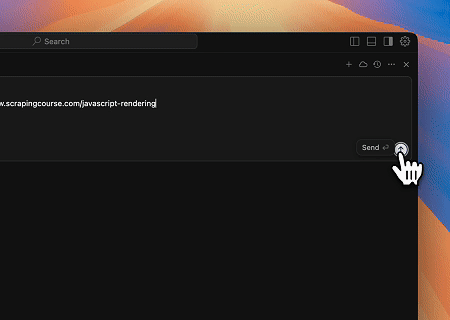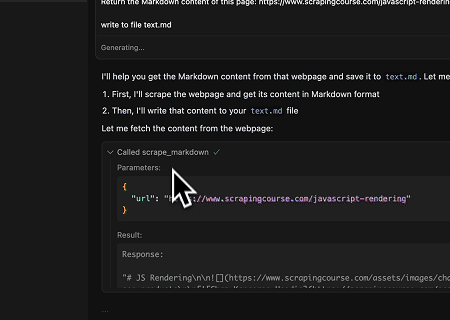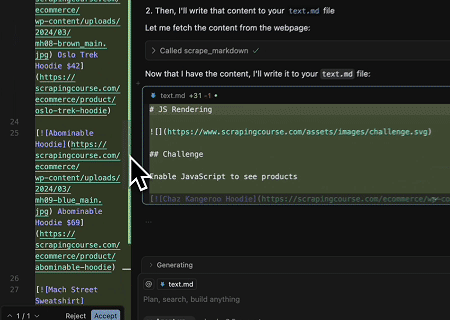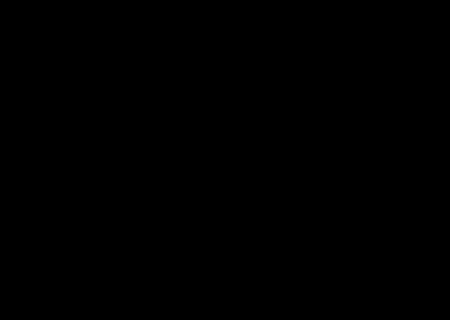
- 동적으로 렌더링된 페이지 콘텐츠 추출 및 파일로 쓰기
Scrapeless MCP Universal API를 사용하여 위 대상 페이지의 JavaScript로 렌더링된 콘텐츠를 스크래핑하고, Markdown 형식으로 내보낸 후, 마지막으로 **text.md**이라는 로컬 파일에 씁니다.
- 자동화된 SERP 스크래핑
Scrapeless MCP 서버를 사용하여 Google 검색에서 "web scraping" 키워드를 조회하고, 처음 10개의 검색 결과(제목, 링크, 요약 포함)를 가져와 serp.text 파일에 콘텐츠를 씁니다.
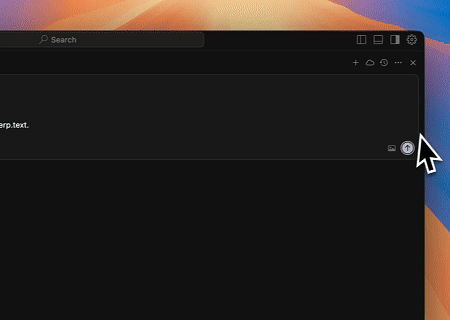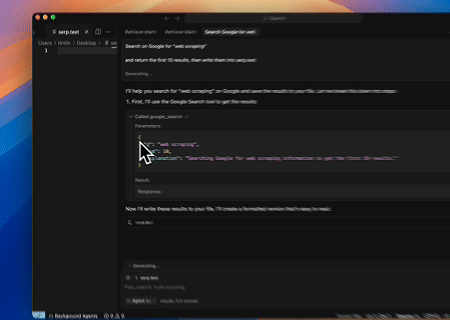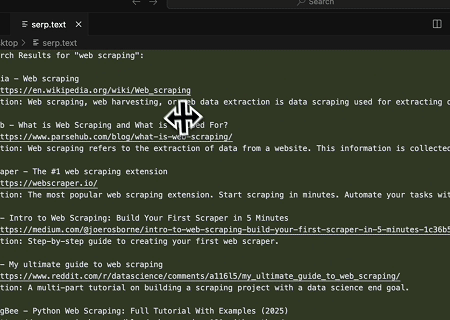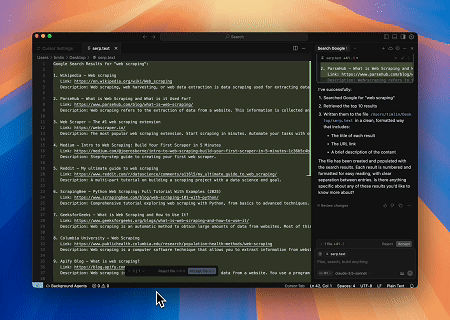
다음은 이러한 서버를 사용하는 방법에 대한 몇 가지 추가 예시입니다.
| 예시 |
|---|
| Google 검색으로 scrapeless 검색하기. |
| 지난 1년간 "AI"에 대한 검색 관심도 찾기. |
| 브라우저를 사용하여 chatgpt.com을 방문하고 "오늘 날씨 어때?"를 검색한 후 결과를 요약합니다. |
| scrapeless.com 페이지의 HTML 콘텐츠 스크래핑하기. |
| scrapeless.com 페이지의 Markdown 콘텐츠 스크래핑하기. |
| scrapeless.com의 스크린샷 가져오기. |
설정 가이드
- Scrapeless 키 받기
- Scrapeless 대시보드에 로그인하세요 (무료 체험 가능)
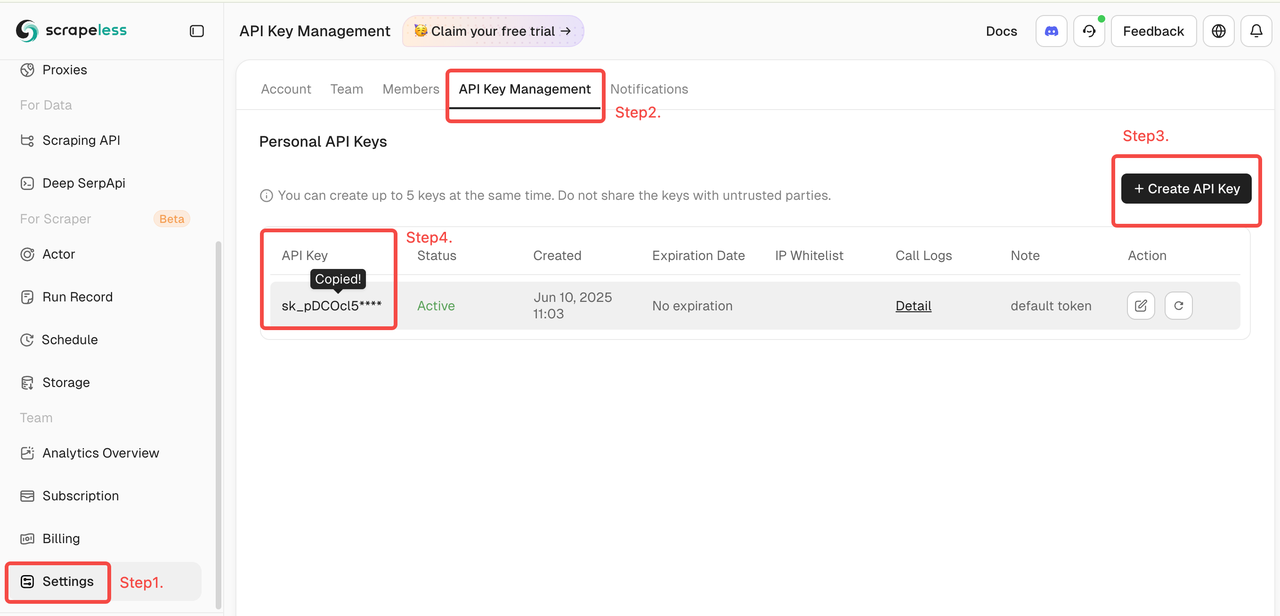
- 그런 다음 왼쪽의 "설정"을 클릭 → "API 키 관리" 선택 → "API 키 생성" 클릭. 마지막으로 생성한 API 키를 클릭하여 복사하세요.
- MCP 클라이언트 구성하기
Scrapeless MCP 서버는 Stdio 및 Streamable HTTP 전송 모드를 모두 지원합니다.
🖥️ Stdio (로컬 실행)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 Streamable HTTP (호스팅 API 모드)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
고급 옵션
선택적 매개변수로 브라우저 세션 동작을 사용자 정의하세요. 이는 환경 변수(Stdio의 경우) 또는 HTTP 헤더(Streamable HTTP의 경우)를 통해 설정할 수 있습니다.
| Stdio (환경 변수) | Streamable HTTP (HTTP 헤더) | 설명 |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | 세션 연속성을 위해 재사용 가능한 브라우저 프로필 ID를 지정합니다. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | 쿠키, 로컬 스토리지 등에 대한 영구 저장소를 활성화합니다. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | 최대 세션 타임아웃을 초 단위로 정의합니다. 이 비활성 시간이 지나면 세션이 자동으로 만료됩니다. |
Claude Desktop과의 통합
- Claude Desktop 열기
- 다음으로 이동:
Settings→Tools→MCP Servers - "MCP 서버 추가" 클릭
- 위의
Stdio또는Streamable HTTP구성 중 하나를 붙여넣기 - 저장하고 서버 활성화
- 이제 Claude가 Scrapeless를 사용하여 웹 쿼리를 실행하고, 콘텐츠를 추출하고, 페이지와 상호 작용할 수 있습니다.
Cursor IDE와의 통합
- Cursor 열기
Cmd + Shift + P을 누르고Configure MCP Servers검색- 위의 형식을 사용하여 Scrapeless MCP 구성 추가
- 파일을 저장하고 Cursor를 다시 시작하세요 (필요한 경우)
- 이제 Cursor에게 다음과 같이 요청할 수 있습니다:
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- 그러면 백그라운드에서 Scrapeless가 사용됩니다.
지원되는 MCP 도구
| 이름 | 설명 |
|---|---|
| google_search | 범용 정보 검색 엔진. |
| google_trends | Google 트렌드에서 인기 검색 데이터 가져오기. |
| browser_create | Scrapeless를 사용하여 클라우드 브라우저 세션 생성 또는 재사용. |
| browser_close | 클라우드 브라우저 연결을 해제하여 현재 세션 닫기. |
| browser_goto | 지정된 URL로 브라우저 이동. |
| browser_go_back | 브라우저 기록에서 한 단계 뒤로 가기. |
| browser_go_forward | 브라우저 기록에서 한 단계 앞으로 가기. |
| browser_click | 페이지의 특정 요소 클릭. |
| browser_type | 지정된 입력 필드에 텍스트 입력. |
| browser_press_key | 키 누르기 시뮬레이션. |
| browser_wait_for | 특정 페이지 요소가 나타날 때까지 대기. |
| browser_wait | 고정된 시간 동안 실행 일시 중지. |
| browser_screenshot | 현재 페이지의 스크린샷 캡처. |
| browser_get_html | 현재 페이지의 전체 HTML 가져오기. |
| browser_get_text | 현재 페이지에서 보이는 모든 텍스트 가져오기. |
| browser_scroll | 페이지 하단으로 스크롤. |
| browser_scroll_to | 특정 요소가 보이도록 스크롤. |
| scrape_html | URL을 스크래핑하여 전체 HTML 콘텐츠 반환. |
| scrape_markdown | URL을 스크래핑하여 콘텐츠를 Markdown으로 반환. |
| scrape_screenshot | 모든 웹페이지의 고품질 스크린샷 캡처. |
보안 모범 사례
Scrapeless MCP 서버를 LLM(ChatGPT, Claude, Cursor 등)과 함께 사용할 때는 스크래핑되거나 추출된 모든 웹 콘텐츠를 주의해서 처리하는 것이 중요합니다. 웹 데이터는 기본적으로 신뢰할 수 없으며, 부적절하게 처리하면 애플리케이션이 프롬프트 인젝션이나 기타 보안 취약점에 노출될 수 있습니다.
✅ 권장 사례
- 원시 스크래핑 콘텐츠를 LLM 프롬프트에 직접 전달하지 마세요. 원시 HTML, JavaScript 또는 사용자 생성 텍스트에는 숨겨진 인젝션 페이로드가 포함될 수 있습니다.
- 추출된 모든 콘텐츠를 살균하고 검증하세요. 다운스트림 로직이나 AI 모델에서 콘텐츠를 사용하기 전에 잠재적으로 유해한 태그와 스크립트를 제거하거나 이스케이프 처리하세요.
- 자유 형식 텍스트보다 구조화된 추출을 선호하세요.
scrape_html,scrape_markdown또는 신뢰할 수 있는 선택기가 있는 대상browser_get_text과 같은 도구를 사용하여 신뢰하는 콘텐츠만 추출하세요. - 동적으로 생성된 페이지를 스크래핑할 때 도메인 또는 선택기 화이트리스트를 적용하여 데이터 흐름을 알려지고 신뢰할 수 있는 소스로 제한하세요.
- 특히 민감한 데이터, 토큰 또는 내부 네트워크 액세스를 처리하는 경우 브라우저 또는 스크래핑 도구를 통해 이루어진 모든 아웃바운드 요청을 기록하고 모니터링하세요.
🚫 피해야 할 사항
- 스크래핑된 HTML을 프롬프트에 직접 주입하기
- 사용자가 검증 없이 임의의 URL이나 CSS 선택기를 지정하도록 허용하기
- 향후 프롬프트 사용을 위해 필터링되지 않은 스크래핑 콘텐츠 저장하기
커뮤니티
문의하기
질문, 제안 또는 협업 문의가 있으시면 다음을 통해 언제든지 연락해 주세요.
- 이메일: [email protected]
- 공식 웹사이트: https://www.scrapeless.com
- 커뮤니티 포럼: https://discord.gg/Np4CAHxB9a