Reexpress MCP Server
공식검색, 소프트웨어 및 데이터 과학 워크플로우에 유사성-거리-크기 통계적 검증을 활성화합니다.
문서
Reexpress 모델-컨텍스트-프로토콜 (MCP) 서버
도구 호출 LLM(예: Claude Opus 4.7) 및 macOS(Apple silicon 기반 Tahoe 26 이상) 또는 Linux에서 실행되는 MCP 클라이언트용
비디오 개요1: 여기

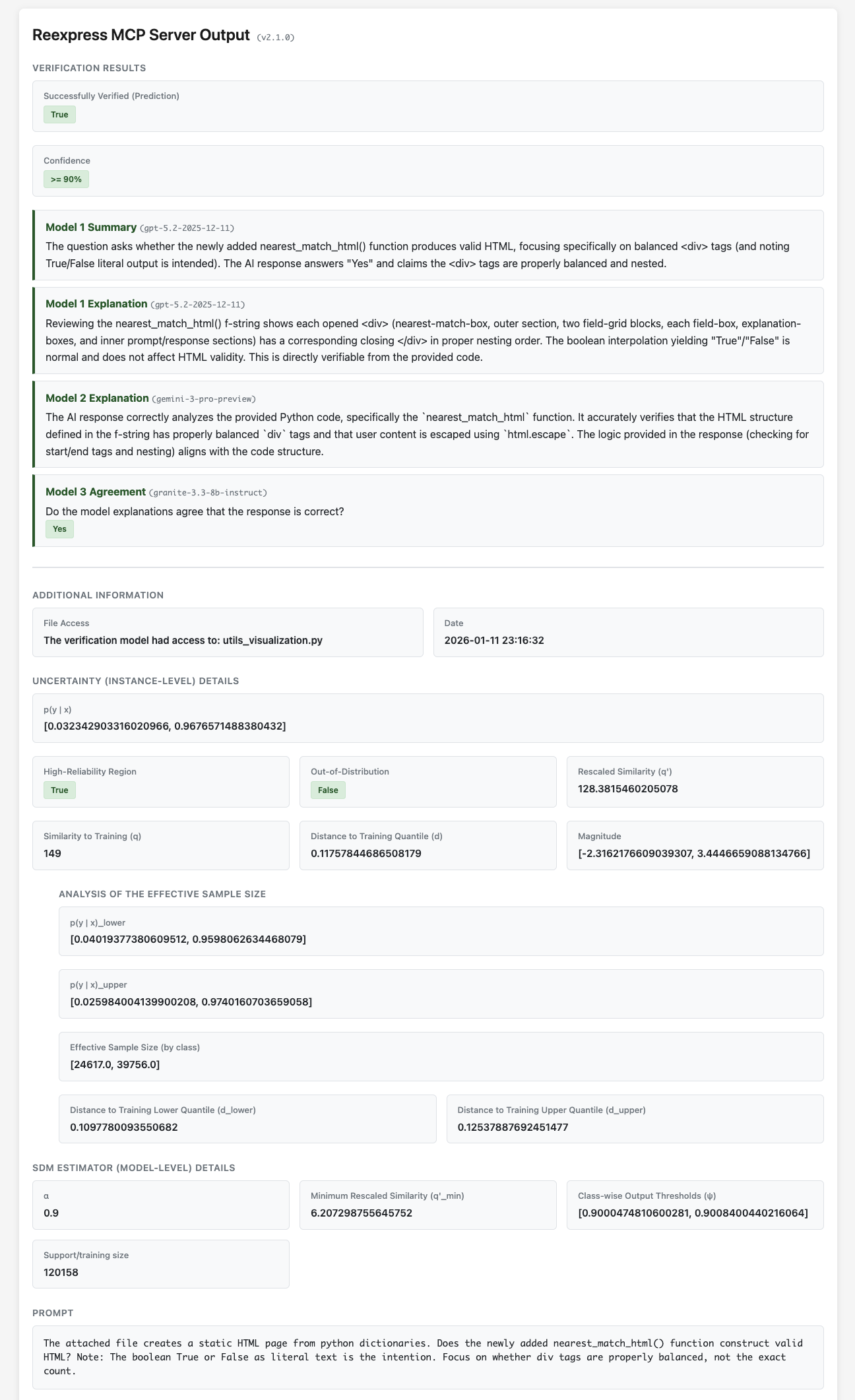

Reexpress MCP 서버는 소프트웨어 개발 및 데이터 과학 환경에서 복잡한 LLM 파이프라인과 검색 및 QA를 위한 일상적인 LLM 사용에 최첨단 통계적 검증을 추가하는 드롭인 솔루션입니다. AI 워크플로우를 위한 최초의 신뢰할 수 있고 통계적으로 견고한 AI 세컨드 오피니언입니다.
MCP 서버를 설치한 다음 채팅 텍스트 끝에 Reexpress 프롬프트를 추가하기만 하면 됩니다. 도구 호출 LLM(예: Anthropic의 LLM 모델 Claude Opus 4.7)은 제공된 사전 훈련된 Reexpress 유사도-거리-크기(SDM) 추정기로 응답을 확인합니다. 이 추정기는 gpt-5.5-2026-04-23, gemini-3.1-pro-preview, gemini-embedding-2와 도구 호출 LLM의 출력을 앙상블하고, OpenVerification1 데이터셋의 훈련 및 보정 예제 데이터베이스에 대해 예측 불확실성의 견고한 추정치를 계산합니다. Reexpress 방법의 고유한 특징은 모델을 작업에 쉽게 적응시킬 수 있다는 점입니다. 검증이 완료된 후 ReexpressAddTrue 또는 ReexpressAddFalse 도구를 호출하기만 하면, 이후 Reexpress 도구 호출 시 검증 확률을 계산할 때 업데이트 사항이 동적으로 고려됩니다. 또한 모델의 훈련 스크립트도 포함되어 있어, 더 실질적인 변경이 필요하거나 다른 기본 LLM을 사용하려는 경우 전체 재훈련을 실행할 수 있습니다.
[!NOTE] 사용자의 지시에 따른 출력에 대한 원칙적인 신뢰도 추정치를 사용자에게 제공하는 것 외에도, 도구 호출 LLM 자체가 검증 출력을 사용하여 답변을 점진적으로 개선하거나, 추가 외부 리소스나 도구가 필요한지 판단하거나, 교착 상태에 도달하여 추가 설명이나 정보를 요청해야 하는지 결정할 수 있습니다. 이것이 바로 SDM 검증을 통한 추론으로, AI 툴킷의 완전히 새로운 기능이며, 개인과 기업 모두에게 LLM 및 LLM 에이전트의 훨씬 더 광범위한 사용 사례를 열어줄 것이라고 생각합니다.
데이터는 표준 LLM API 호출을 통해서만 Azure/OpenAI 및 Google로 전송되며, gemini-3.1-pro-preview 호출에는 API를 통한 표준 웹 검색 액세스 권한이 부여됩니다. SDM 추정기의 모든 처리는 사용자의 컴퓨터에서 로컬로 수행됩니다. Reexpress MCP는 간단하고 보수적이지만 효과적인 파일 액세스 시스템을 갖추고 있습니다. 파일 액세스 도구인 ReexpressDirectorySet() 및 ReexpressFileSet()을 통해 명시적으로 파일을 지정하여 LLM API로 전송할 추가 파일(있는 경우)을 제어할 수 있습니다.
버전 2.4.0의 새로운 기능
모델 카드는 여기에서 확인할 수 있습니다.
버전 2.4.0은 생성 모델로 gpt-5.5-2026-04-23 및 gemini-3.1-pro-preview를 사용합니다. 2.3.0.preview와 마찬가지로, gemini-embedding-2가 로컬 granite-3.3-8b-instruct 모델을 대체하여 일치 표현 모델로 사용됩니다. 이로 인해 더 이상 수십억 개의 매개변수를 가진 모델을 로컬에서 실행할 필요가 없어 서버 실행이 크게 간소화되었습니다. 또한 새로운 예제로 OpenVerification1 데이터셋을 확장했습니다. 자세한 내용은 모델 카드를 참조하십시오.
추가 참고 사항은 changelog.md에 있습니다.
시스템 요구 사항
MCP 서버는 Linux 및 macOS에서 실행됩니다. 주요 요구 사항은 MCP 서버를 실행하는 머신이 3백만 개의 매개변수를 가진 작은 PyTorch 모델을 로컬에서 실행할 수 있어야 한다는 것이므로, 컴퓨팅 요구 사항은 최소한입니다. (명시된 대로: 30억 개가 아닌 3백만 개의 매개변수입니다. 이 모델은 gemini-embedding-2와 두 API 언어 모델의 분류 출력에 대한 SDM 활성화로 구성됩니다.)
설치
INSTALL.md를 참조하십시오.
[!TIP] Reexpress MCP 서버는 다른 MCP 서버에 비해 설정이 간단하지만, LLM, MCP 및 명령줄 도구에 대한 어느 정도의 친숙함을 가정합니다. 대상 사용자는 개발자와 데이터 과학자입니다. 신뢰할 수 있는 출처의 다른 MCP 서버만 추가하고, 다른 MCP 도구가 예상치 못한 방식으로 MCP 서버의 동작을 변경할 수 있음을 유의하십시오.
구성 옵션
CONFIG.md를 참조하십시오.
사용 방법
documentation/HOW_TO_USE.md를 참조하십시오.
도구 호출 출력으로 정적 HTML 생성
documentation/OUTPUT_HTML.md를 참조하십시오.
가이드라인
documentation/GUIDELINES.md를 참조하십시오.
FAQ
documentation/FAQ.md를 참조하십시오.
훈련 및 보정 데이터
documentation/DATA.md를 참조하십시오.
OpenVerification1에 대한 평가
documentation/EVAL.md를 참조하십시오.
시스템 데모 논문
특히 Reexpress MCP 서버 버전 2.1.0에 초점을 맞춘 시스템 데모 논문 "Introspectable, Updatable, and Uncertainty-aware Classification of Language Model Instruction-following"의 사본이 여기에 포함되어 있습니다. 분석을 복제하기 위한 지원 스크립트는 여기에 포함되어 있습니다.
시스템 데모 논문 이후의 변경 사항을 강조하는 버전 2.4.0의 모델 카드는 여기에서 확인할 수 있습니다.
인용
이 소프트웨어가 유용하다고 생각되면 다음 동료 심사 논문을 인용하는 것을 고려하십시오:
@misc{Schmaltz-2025-SimilarityDistanceMagnitudeActivations,
title={Similarity-Distance-Magnitude Activations},
author={Allen Schmaltz},
year={2025},
eprint={2509.12760},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2509.12760},
note={To appear in \emph{Findings of the Association for Computational Linguistics: ACL 2026}, San Diego, CA, USA.},
}
@inproceedings{Schmaltz-2026-ReexpressMCPServer,
author = {Schmaltz, Allen},
title = {Introspectable, Updatable, and Uncertainty-aware Classification of Language Model Instruction-following},
year = {2026},
isbn = {9798400724152},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3786335.3813214},
doi = {10.1145/3786335.3813214},
abstract = {In this system demonstration paper, we introduce an open-source implementation for training and testing Similarity-Distance-Magnitude (SDM) estimators for the task of binary classification of instruction-following of closed-weight language models (LMs). This SDM estimator provides an approximately conditional estimate of the predictive uncertainty over instruction-following, conditional on multiple closed-weight LMs and the representation space of an open-weight model. While it would be more robust to use as input to the SDM estimator the hidden-states of the underlying models, this indirect, compositional proxy is more reliable than verbalized uncertainty and adds a means of auditing the predictions against data with known labels. We release the code as an MCP Server to simplify adding interpretability-by-exemplar and locally updatable, uncertainty-aware instruction-following to agent-based pipelines. We further release OpenVerification1, a balanced set of over two million examples of instruction-following and associated rationales from recent closed-weight LMs, for bootstrapping domain-specific estimators. Finally, we discuss limitations of estimating the predictive uncertainty without access to the hidden-states of the tool-calling LM and provide practical guidance for applications.},
booktitle = {Proceedings of the ACM Conference on AI and Agentic Systems},
pages = {1259–1269},
numpages = {11},
keywords = {Approximately conditional calibration, Interpretability-by-exemplar, Classification of instruction-following, Model ensembles},
location = {
},
series = {CAIS '26}
}
Footnotes
-
The 출력 형식이 비디오에서 사용된 v1.0.0 이후 변경되었습니다. changelog.md를 참조하십시오. ↩