Reexpress MCP Server
公式Enable Similarity-Distance-Magnitude statistical verification for your search, software, and data science workflows
ドキュメント
Reexpress Model-Context-Protocol (MCP) サーバー
ツール呼び出し型LLM(例:Claude Opus 4.7)およびmacOS(Tahoe 26以降、Appleシリコン搭載)またはLinux上で動作するMCPクライアント向け
動画概要1: こちら

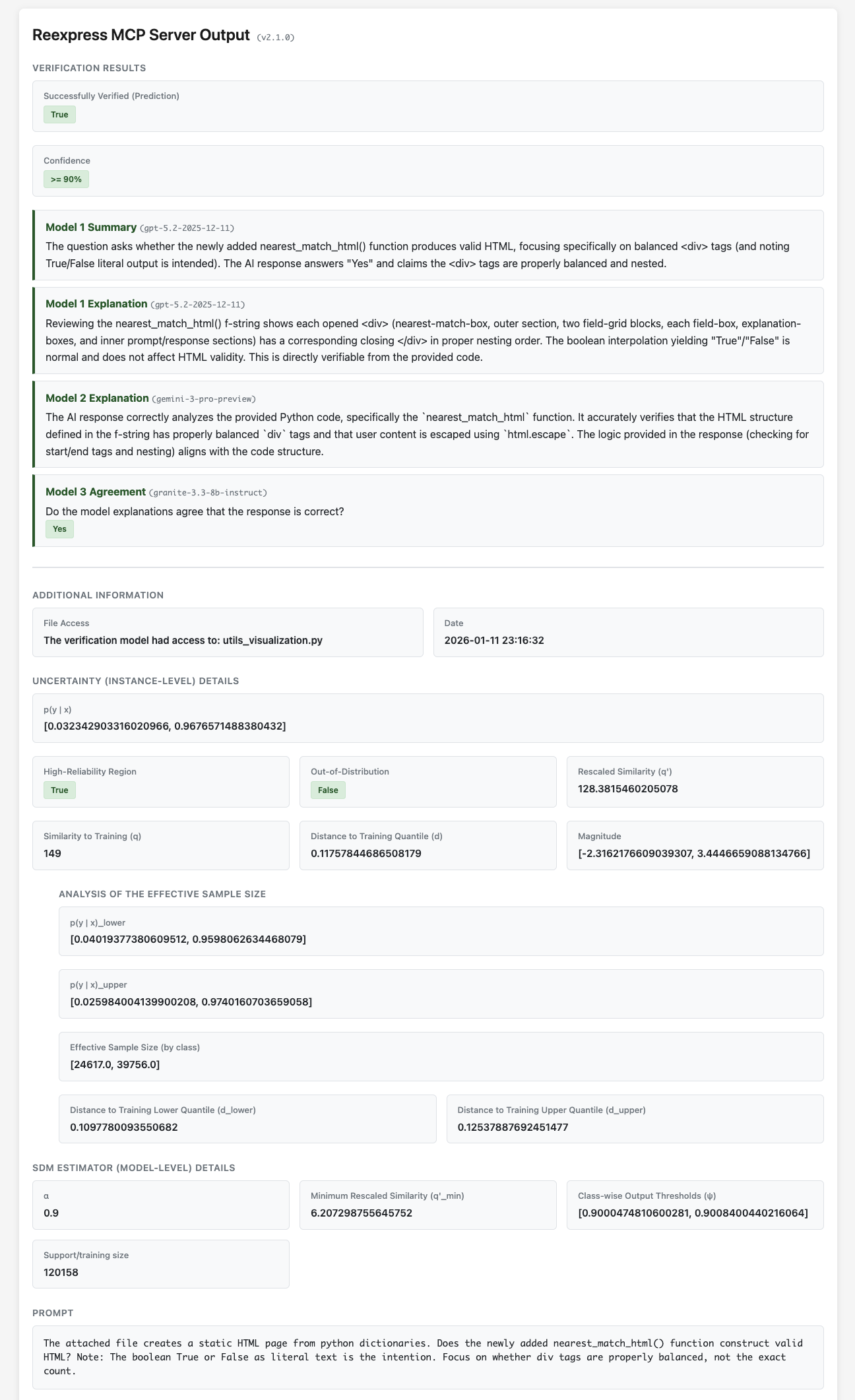

Reexpress MCPサーバーは、複雑なLLMパイプラインや、ソフトウェア開発およびデータサイエンスの現場におけるLLMを用いた検索やQAといった日常的な利用に、最先端の統計的検証を追加するためのドロップインソリューションです。これは、AIワークフローに対する、信頼性が高く統計的に堅牢な初のAIセカンドオピニオンです。
MCPサーバーをインストールし、チャットテキストの末尾にReexpressプロンプトを追加するだけです。すると、ツール呼び出し型LLM(例:AnthropicのLLMモデルClaude Opus 4.7)は、提供された事前学習済みのReexpress Similarity-Distance-Magnitude (SDM) 推定量を用いて自身の応答をチェックします。この推定量は、gpt-5.5-2026-04-23、gemini-3.1-pro-preview、gemini-embedding-2、およびツール呼び出し型LLMからの出力をアンサンブルし、OpenVerification1データセットの学習例とキャリブレーション例のデータベースに対して予測の不確実性のロバストな推定値を計算します。Reexpressメソッドの独自の点として、モデルをタスクに容易に適応させることができます。検証が完了した後にReexpressAddTrueまたはReexpressAddFalseツールを呼び出すだけで、その後のReexpressツールの呼び出しでは、検証確率の計算時に更新内容が動的に考慮されます。また、モデルのトレーニングスクリプトも含まれているため、より大幅な変更が必要な場合や、基盤となるLLMを別のものに変更したい場合には、完全な再トレーニングを実行できます。
[!NOTE] このサーバーは、あなた(ユーザー)に対して、指示に対する出力の信頼度を原理に基づいて推定するだけでなく、ツール呼び出し型LLM自体が検証出力を用いて回答を段階的に洗練させたり、追加の外部リソースやツールが必要かどうかを判断したり、行き詰まりに達してさらなる明確化や情報を求める必要があるかどうかを判断したりすることができます。これを我々はSDM検証による推論と呼んでいます。これはAIツールキットにおける全く新しい機能であり、個人と企業の両方にとって、LLMおよびLLMエージェントのユースケースをはるかに広げるものと考えています。
データは、標準的なLLM API呼び出しを通じてAzure/OpenAIおよびGoogleに送信されるのみであり、gemini-3.1-pro-previewの呼び出しにはAPI経由で標準的なウェブ検索アクセスが与えられます。SDM推定量の処理はすべて、お使いのコンピューター上でローカルに実行されます。Reexpress MCPは、シンプルで保守的でありながら効果的なファイルアクセスシステムを備えています。ファイルアクセスツールReexpressDirectorySet()およびReexpressFileSet()を使用してファイルを明示的に指定することで、どの追加ファイルをLLM APIに送信するか(あるいは送信しないか)を制御できます。
バージョン2.4.0の新機能
モデルカードはこちらから入手できます。
バージョン2.4.0では、生成モデルとしてgpt-5.5-2026-04-23とgemini-3.1-pro-previewを使用しています。2.3.0.previewと同様に、合意表現モデルとして、ローカルのgranite-3.3-8b-instructモデルがgemini-embedding-2に置き換えられました。これにより、数十億パラメータのモデルをローカルで実行する必要がなくなり、サーバーの実行が大幅に簡素化されます。さらに、OpenVerification1データセットに新しい例を追加して拡張しました。詳細についてはモデルカードを参照してください。
その他の注意事項はchangelog.mdに記載されています。
システム要件
MCPサーバーはLinuxおよびmacOS上で動作します。主な要件は、MCPサーバーを実行するマシンが、300万パラメータの小さなPyTorchモデルをローカルで実行できることです。そのため、計算要件は最小限です。(これは記載の通り、30億パラメータではなく、わずか300万パラメータです。このモデルは、gemini-embedding-2と2つのAPI言語モデルの分類出力に対するSDM活性化で構成されています。)
インストール
INSTALL.mdを参照してください。
[!TIP] Reexpress MCPサーバーは、他のMCPサーバーと比較してセットアップが簡単ですが、LLM、MCP、およびコマンドラインツールにある程度精通していることを前提としています。対象読者は開発者とデータサイエンティストです。信頼できるソースからのみ他のMCPサーバーを追加し、他のMCPツールが予期しない方法で当社のMCPサーバーの動作を変更する可能性があることに留意してください。
設定オプション
CONFIG.mdを参照してください。
使用方法
documentation/HOW_TO_USE.mdを参照してください。
ツール呼び出しの出力から静的HTMLを生成する
documentation/OUTPUT_HTML.mdを参照してください。
ガイドライン
documentation/GUIDELINES.mdを参照してください。
FAQ
documentation/FAQ.mdを参照してください。
トレーニングデータとキャリブレーションデータ
documentation/DATA.mdを参照してください。
OpenVerification1による評価
documentation/EVAL.mdを参照してください。
システムデモンストレーション論文
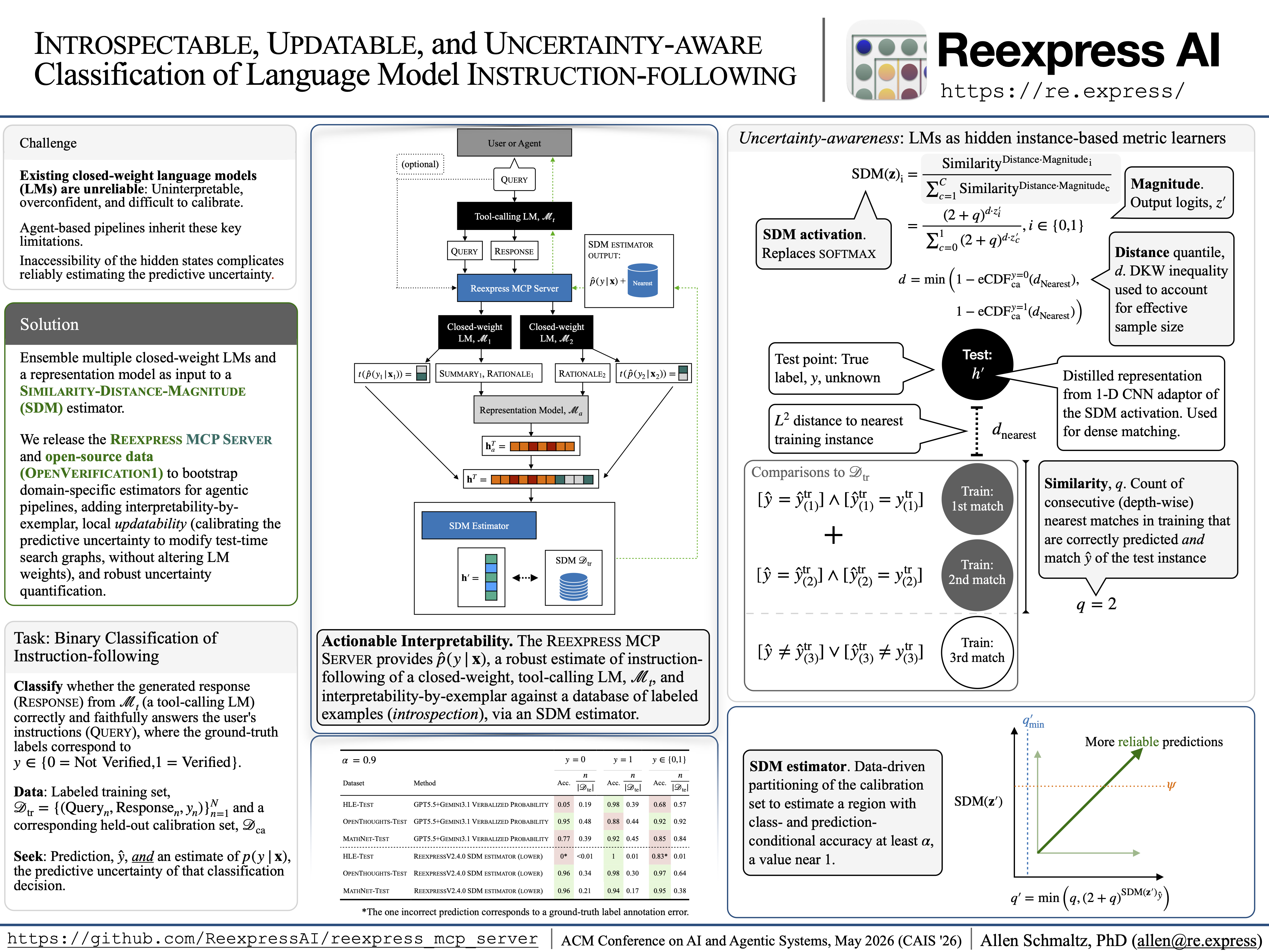
システムデモンストレーション論文「Introspectable, Updatable, and Uncertainty-aware Classification of Language Model Instruction-following」(特にReexpress MCPサーバーのバージョン2.1.0に焦点を当てています)のコピーはこちらに含まれています。分析を再現するためのサポートスクリプトはこちらに含まれています。
システムデモンストレーション論文以降の変更点を強調したバージョン2.4.0のモデルカードはこちらから入手できます。
引用
このソフトウェアが有用であると感じられた場合は、以下の査読付き論文の引用をご検討ください。
@misc{Schmaltz-2025-SimilarityDistanceMagnitudeActivations,
title={Similarity-Distance-Magnitude Activations},
author={Allen Schmaltz},
year={2025},
eprint={2509.12760},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2509.12760},
note={To appear in \emph{Findings of the Association for Computational Linguistics: ACL 2026}, San Diego, CA, USA.},
}
@inproceedings{Schmaltz-2026-ReexpressMCPServer,
author = {Schmaltz, Allen},
title = {Introspectable, Updatable, and Uncertainty-aware Classification of Language Model Instruction-following},
year = {2026},
isbn = {9798400724152},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3786335.3813214},
doi = {10.1145/3786335.3813214},
abstract = {In this system demonstration paper, we introduce an open-source implementation for training and testing Similarity-Distance-Magnitude (SDM) estimators for the task of binary classification of instruction-following of closed-weight language models (LMs). This SDM estimator provides an approximately conditional estimate of the predictive uncertainty over instruction-following, conditional on multiple closed-weight LMs and the representation space of an open-weight model. While it would be more robust to use as input to the SDM estimator the hidden-states of the underlying models, this indirect, compositional proxy is more reliable than verbalized uncertainty and adds a means of auditing the predictions against data with known labels. We release the code as an MCP Server to simplify adding interpretability-by-exemplar and locally updatable, uncertainty-aware instruction-following to agent-based pipelines. We further release OpenVerification1, a balanced set of over two million examples of instruction-following and associated rationales from recent closed-weight LMs, for bootstrapping domain-specific estimators. Finally, we discuss limitations of estimating the predictive uncertainty without access to the hidden-states of the tool-calling LM and provide practical guidance for applications.},
booktitle = {Proceedings of the ACM Conference on AI and Agentic Systems},
pages = {1259–1269},
numpages = {11},
keywords = {Approximately conditional calibration, Interpretability-by-exemplar, Classification of instruction-following, Model ensembles},
location = {
},
series = {CAIS '26}
}
Footnotes
-
The 出力形式は、動画で使用されているv1.0.0から変更されています。changelog.mdを参照してください。 ↩