Scrapeless MCP Server
आधिकारिकअपने LLM अनुप्रयोगों में रीयल-टाइम Scrapeless Google SERP (Google Search, Google Flight, Google Map, Google Jobs....) परिणामों को एकीकृत करें। यह सर्वर AI वर्कफ़्लो, चैटबॉट और अनुसंधान उपकरणों के लिए गतिशील संदर्भ पुनर्प्राप्ति सक्षम करता है।
दस्तावेज़

Scrapeless MCP सर्वर
आधिकारिक Scrapeless मॉडल संदर्भ प्रोटोकॉल (MCP) सर्वर में आपका स्वागत है — एक शक्तिशाली एकीकरण परत जो LLM, AI एजेंट और AI अनुप्रयोगों को वास्तविक समय में वेब के साथ इंटरैक्ट करने की शक्ति देती है।
खुले MCP मानक पर निर्मित, Scrapeless MCP सर्वर ChatGPT, Claude जैसे मॉडलों और Cursor तथा Windsurf जैसे उपकरणों को व्यापक बाहरी क्षमताओं से सहजता से जोड़ता है, जिनमें शामिल हैं:
- Google सेवाएं एकीकरण (खोज, रुझान)
- पृष्ठ-स्तरीय नेविगेशन और इंटरैक्शन के लिए ब्राउज़र स्वचालन
- गतिशील, JS-भारी साइटों को स्क्रैप करें—HTML, Markdown या स्क्रीनशॉट के रूप में निर्यात करें
चाहे आप एक AI अनुसंधान सहायक, एक कोडिंग सह-पायलट, या स्वायत्त वेब एजेंट बना रहे हों, यह सर्वर आपके वर्कफ़्लो के लिए आवश्यक गतिशील संदर्भ और वास्तविक दुनिया का डेटा प्रदान करता है—बिना ब्लॉक हुए।
उपयोग के उदाहरण
- Claude के साथ स्वचालित वेब इंटरैक्शन और डेटा निष्कर्षण
Scrapeless MCP ब्राउज़र का उपयोग करके, Claude वार्तालाप आदेशों के माध्यम से वेब नेविगेशन, क्लिक करना, स्क्रॉल करना और स्क्रैपिंग जैसे जटिल कार्य कर सकता है, जिसमें live sessions के माध्यम से वेब इंटरैक्शन परिणामों का वास्तविक समय पूर्वावलोकन होता है।
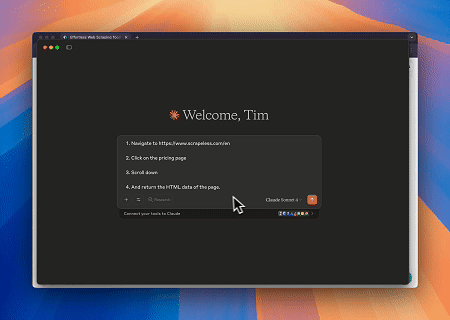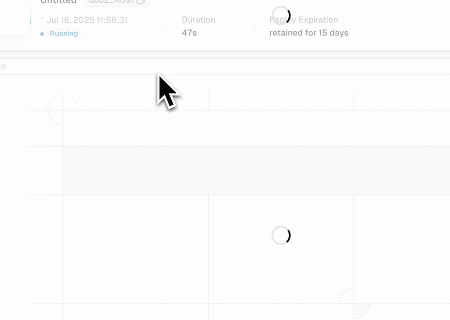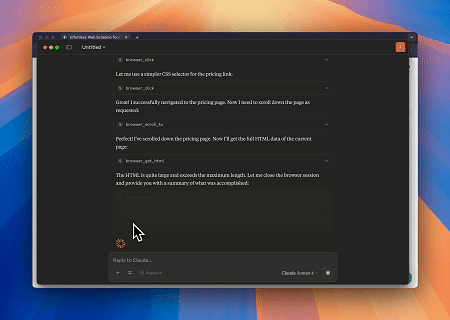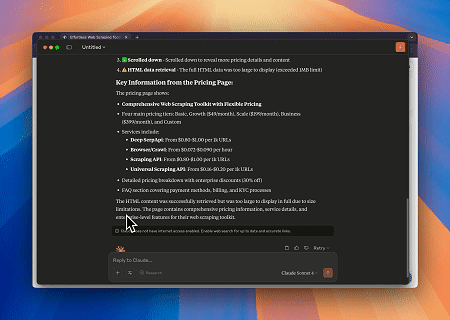
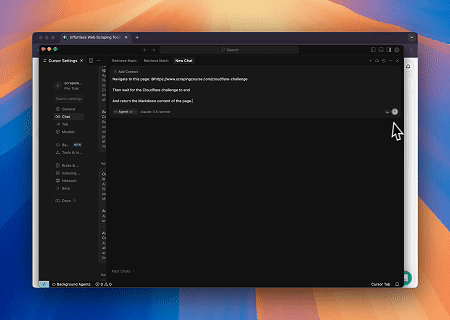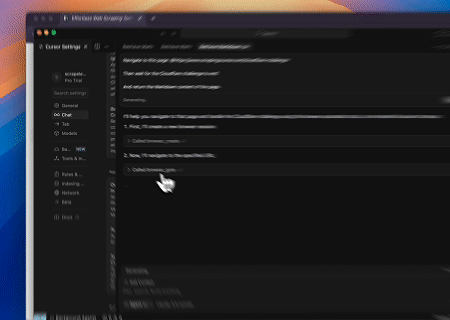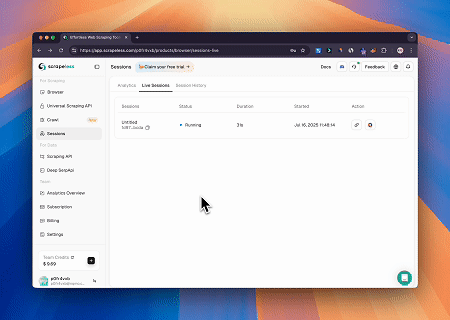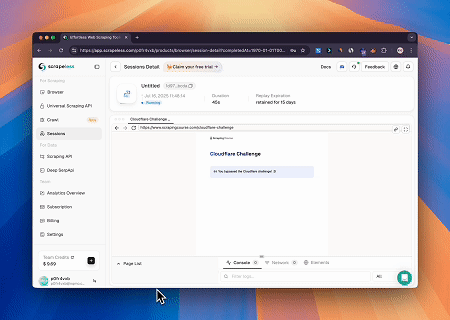
- लक्ष्य पृष्ठ सामग्री प्राप्त करने के लिए Cloudflare को बायपास करना
Scrapeless MCP ब्राउज़र सेवा का उपयोग करके, Cloudflare पृष्ठ स्वचालित रूप से एक्सेस किया जाता है, और प्रक्रिया पूरी होने के बाद, पृष्ठ सामग्री निकाली जाती है और Markdown प्रारूप में लौटाई जाती है।
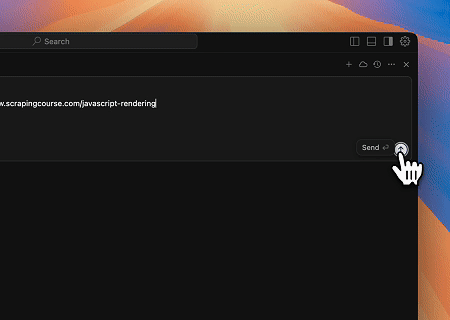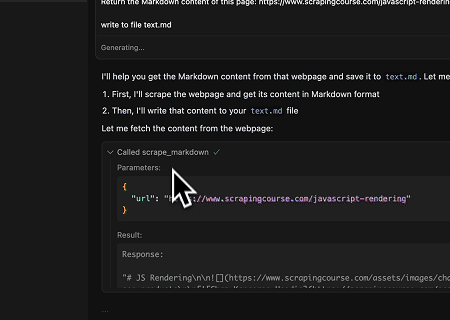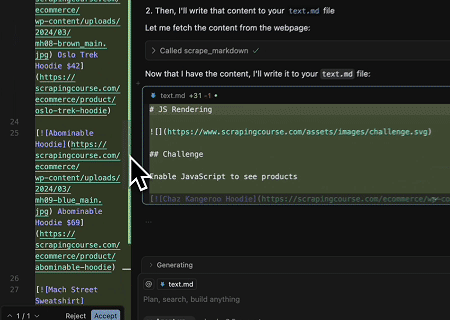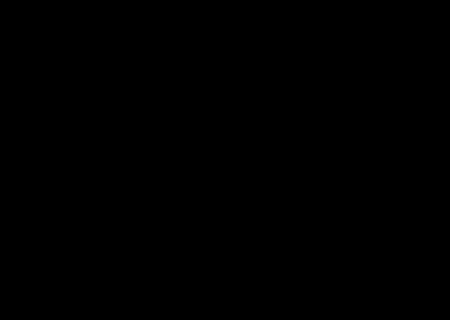
- गतिशील रूप से रेंडर की गई पृष्ठ सामग्री निकालना और फ़ाइल में लिखना
Scrapeless MCP यूनिवर्सल API का उपयोग करके, उपरोक्त लक्ष्य पृष्ठ की JavaScript-रेंडर की गई सामग्री को स्क्रैप किया जाता है, Markdown प्रारूप में निर्यात किया जाता है, और अंत में text.md नामक स्थानीय फ़ाइल में लिखा जाता है।
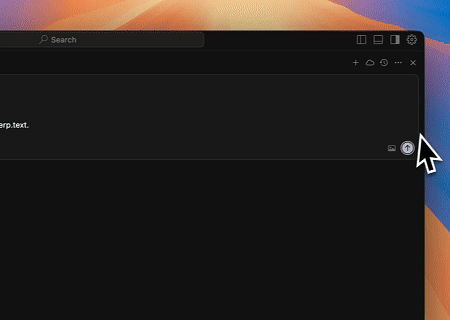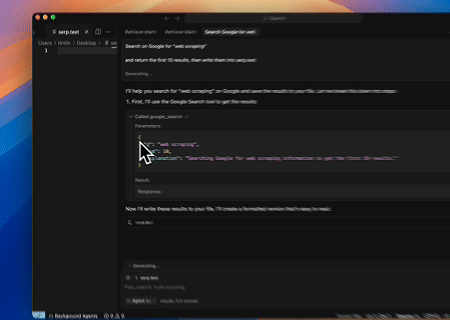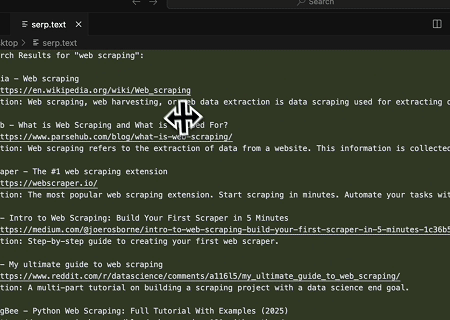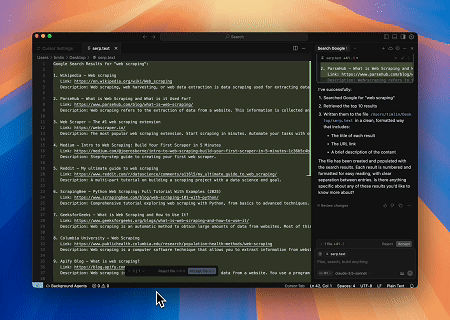
- स्वचालित SERP स्क्रैपिंग
Scrapeless MCP सर्वर का उपयोग करके, Google खोज पर "वेब स्क्रैपिंग" कीवर्ड क्वेरी करें, पहले 10 खोज परिणाम (शीर्षक, लिंक और सारांश सहित) प्राप्त करें, और सामग्री को serp.text नामक फ़ाइल में लिखें।
इन सर्वरों का उपयोग करने के कुछ अतिरिक्त उदाहरण यहां दिए गए हैं:
| उदाहरण |
|---|
| Google खोज द्वारा scrapeless खोजें। |
| पिछले वर्ष में "AI" के लिए खोज रुचि का पता लगाएं। |
| chatgpt.com पर जाने के लिए ब्राउज़र का उपयोग करें, "आज मौसम कैसा है?" खोजें, और परिणामों को सारांशित करें। |
| scrapeless.com पृष्ठ की HTML सामग्री स्क्रैप करें। |
| scrapeless.com पृष्ठ की Markdown सामग्री स्क्रैप करें। |
| scrapeless.com के स्क्रीनशॉट प्राप्त करें। |
सेटअप गाइड
- Scrapeless कुंजी प्राप्त करें
- Scrapeless डैशबोर्ड में लॉग इन करें (निःशुल्क परीक्षण उपलब्ध)
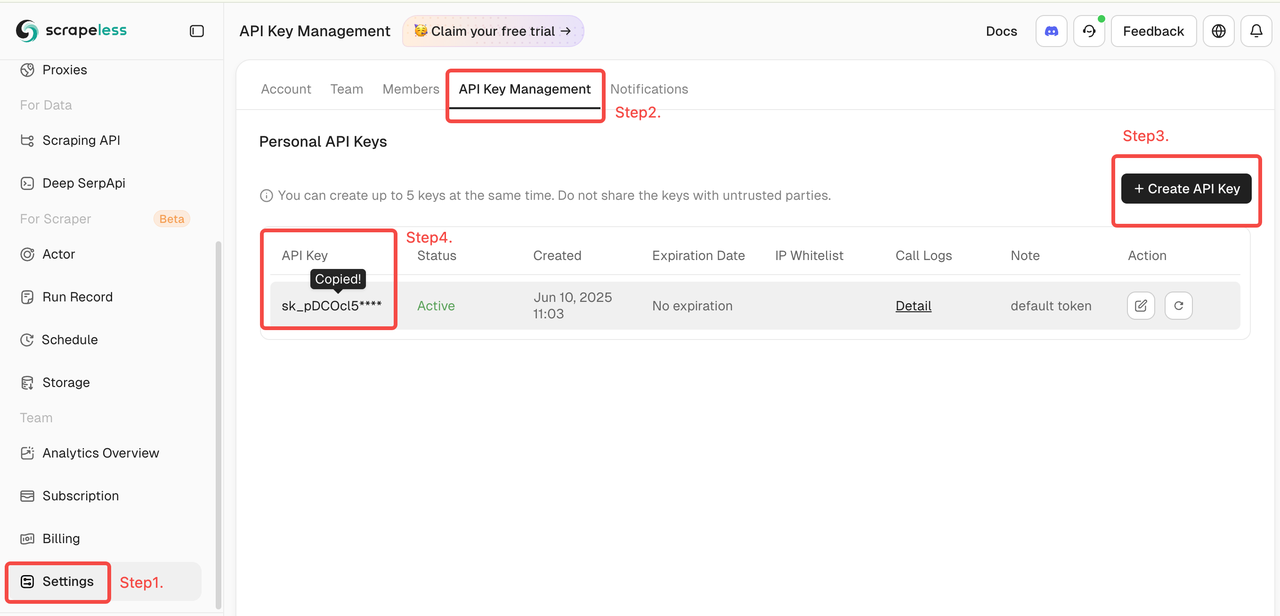
- फिर बाईं ओर "सेटिंग" पर क्लिक करें -> "API कुंजी प्रबंधन" चुनें -> "API कुंजी बनाएं" पर क्लिक करें। अंत में, इसे कॉपी करने के लिए आपके द्वारा बनाई गई API कुंजी पर क्लिक करें।
- अपना MCP क्लाइंट कॉन्फ़िगर करें
Scrapeless MCP सर्वर Stdio और स्ट्रीमेबल HTTP दोनों परिवहन मोड का समर्थन करता है।
🖥️ Stdio (स्थानीय निष्पादन)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 स्ट्रीमेबल HTTP (होस्टेड API मोड)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
उन्नत विकल्प
वैकल्पिक पैरामीटर के साथ ब्राउज़र सत्र व्यवहार को अनुकूलित करें। इन्हें पर्यावरण चर (Stdio के लिए) या HTTP हेडर (स्ट्रीमेबल HTTP के लिए) के माध्यम से सेट किया जा सकता है:
| Stdio (Env Var) | स्ट्रीमेबल HTTP (HTTP हेडर) | विवरण |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | सत्र निरंतरता के लिए एक पुन: प्रयोज्य ब्राउज़र प्रोफ़ाइल ID निर्दिष्ट करता है। |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | कुकीज़, स्थानीय भंडारण आदि के लिए स्थायी भंडारण सक्षम करता है। |
| BROWSER_SESSION_TTL | x-browser-session-ttl | सेकंड में अधिकतम सत्र समयबाह्य को परिभाषित करता है। निष्क्रियता की इस अवधि के बाद सत्र स्वचालित रूप से समाप्त हो जाएगा। |
Claude डेस्कटॉप के साथ एकीकरण
- Claude डेस्कटॉप खोलें
- यहां नेविगेट करें:
Settings→Tools→MCP Servers - "MCP सर्वर जोड़ें" पर क्लिक करें
- उपरोक्त
StdioयाStreamable HTTPकॉन्फ़िगरेशन में से कोई एक पेस्ट करें - सहेजें और सर्वर सक्षम करें
- Claude अब Scrapeless का उपयोग करके वेब क्वेरी जारी करने, सामग्री निकालने और पृष्ठों के साथ इंटरैक्ट करने में सक्षम होगा
Cursor IDE के साथ एकीकरण
- Cursor खोलें
Cmd + Shift + Pदबाएं और खोजें:Configure MCP Servers- उपरोक्त प्रारूप का उपयोग करके Scrapeless MCP कॉन्फ़िगरेशन जोड़ें
- फ़ाइल सहेजें और Cursor को पुनरारंभ करें (यदि आवश्यक हो)
- अब आप Cursor से ऐसी चीज़ें पूछ सकते हैं:
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- और यह पृष्ठभूमि में Scrapeless का उपयोग करेगा।
समर्थित MCP उपकरण
| नाम | विवरण |
|---|---|
| google_search | सार्वभौमिक सूचना खोज इंजन। |
| google_trends | Google रुझान से ट्रेंडिंग खोज डेटा प्राप्त करें। |
| browser_create | Scrapeless का उपयोग करके क्लाउड ब्राउज़र सत्र बनाएं या पुन: उपयोग करें। |
| browser_close | क्लाउड ब्राउज़र को डिस्कनेक्ट करके वर्तमान सत्र बंद करता है। |
| browser_goto | ब्राउज़र को निर्दिष्ट URL पर नेविगेट करें। |
| browser_go_back | ब्राउज़र इतिहास में एक कदम पीछे जाएं। |
| browser_go_forward | ब्राउज़र इतिहास में एक कदम आगे बढ़ें। |
| browser_click | पृष्ठ पर किसी विशिष्ट तत्व पर क्लिक करें। |
| browser_type | निर्दिष्ट इनपुट फ़ील्ड में टेक्स्ट टाइप करें। |
| browser_press_key | एक कुंजी दबाने का अनुकरण करें। |
| browser_wait_for | किसी विशिष्ट पृष्ठ तत्व के प्रकट होने की प्रतीक्षा करें। |
| browser_wait | एक निश्चित अवधि के लिए निष्पादन रोकें। |
| browser_screenshot | वर्तमान पृष्ठ का स्क्रीनशॉट कैप्चर करें। |
| browser_get_html | वर्तमान पृष्ठ का पूर्ण HTML प्राप्त करें। |
| browser_get_text | वर्तमान पृष्ठ से सभी दृश्यमान टेक्स्ट प्राप्त करें। |
| browser_scroll | पृष्ठ के निचले भाग तक स्क्रॉल करें। |
| browser_scroll_to | किसी विशिष्ट तत्व को दृश्य में स्क्रॉल करें। |
| scrape_html | एक URL स्क्रैप करें और उसकी पूर्ण HTML सामग्री लौटाएं। |
| scrape_markdown | एक URL स्क्रैप करें और उसकी सामग्री Markdown के रूप में लौटाएं। |
| scrape_screenshot | किसी भी वेबपेज का उच्च-गुणवत्ता वाला स्क्रीनशॉट कैप्चर करें। |
सुरक्षा सर्वोत्तम अभ्यास
LLM (जैसे ChatGPT, Claude, या Cursor) के साथ Scrapeless MCP सर्वर का उपयोग करते समय, सभी स्क्रैप या निकाली गई वेब सामग्री को सावधानी से संभालना महत्वपूर्ण है। वेब डेटा डिफ़ॉल्ट रूप से अविश्वसनीय है, और अनुचित हैंडलिंग आपके एप्लिकेशन को प्रॉम्प्ट इंजेक्शन या अन्य सुरक्षा कमजोरियों के प्रति उजागर कर सकती है।
✅ अनुशंसित अभ्यास
- कच्ची स्क्रैप की गई सामग्री को सीधे LLM प्रॉम्प्ट में कभी न डालें। कच्चे HTML, JavaScript, या उपयोगकर्ता-जनित टेक्स्ट में छिपे हुए इंजेक्शन पेलोड हो सकते हैं।
- सभी निकाली गई सामग्री को सैनिटाइज़ और मान्य करें। डाउनस्ट्रीम लॉजिक या AI मॉडल में सामग्री का उपयोग करने से पहले संभावित हानिकारक टैग और स्क्रिप्ट को हटा दें या एस्केप करें।
- मुक्त-रूप टेक्स्ट पर संरचित निष्कर्षण को प्राथमिकता दें। केवल उस सामग्री को निकालने के लिए जिस पर आप भरोसा करते हैं, ज्ञात-सुरक्षित चयनकर्ताओं के साथ
scrape_html,scrape_markdown, या लक्षितbrowser_get_textजैसे उपकरणों का उपयोग करें। - गतिशील रूप से उत्पन्न पृष्ठों को स्क्रैप करते समय डोमेन या चयनकर्ता श्वेतसूचीकरण लागू करें, ताकि डेटा प्रवाह को ज्ञात और विश्वसनीय स्रोतों तक सीमित किया जा सके।
- ब्राउज़र या स्क्रैपिंग उपकरणों के माध्यम से किए गए सभी आउटबाउंड अनुरोधों को लॉग और मॉनिटर करें, खासकर यदि आप संवेदनशील डेटा, टोकन, या आंतरिक नेटवर्क एक्सेस को संभाल रहे हैं।
🚫 बचें
- स्क्रैप किए गए HTML को सीधे प्रॉम्प्ट में इंजेक्ट करना
- उपयोगकर्ताओं को सत्यापन के बिना मनमाने URL या CSS चयनकर्ता निर्दिष्ट करने देना
- भविष्य के प्रॉम्प्ट उपयोग के लिए अनफ़िल्टर्ड स्क्रैप की गई सामग्री संग्रहीत करना
समुदाय
हमसे संपर्क करें
प्रश्नों, सुझावों या सहयोग पूछताछ के लिए, बेझिझक हमसे संपर्क करें:
- ईमेल: [email protected]
- आधिकारिक वेबसाइट: https://www.scrapeless.com
- सामुदायिक मंच: https://discord.gg/Np4CAHxB9a