engram MCP Server
स्थानीय कोड-ज्ञान ग्राफ + AI कोडिंग एजेंटों के लिए द्वि-कालिक गलतियाँ मेमोरी। पढ़ने/grep पर पूरी फाइलों के बजाय एक रैंक्ड संरचनात्मक पैकेट प्रदान करता है, और आपके रिपॉजिटरी द्वारा पहले से वापस लिए गए सुधारों को सतह पर लाता है (git इतिहास से खनन)। शून्य क्लाउड, Apache-2.0।
दस्तावेज़

Engram makes your AI coding agent stop re-reading the same files — and stop repeating mistakes your repo already fixed.
One install. 8 IDEs. Your agent works from a structural map of your repo instead of re-reading whole files — so sessions run longer before the context wall — and bi-temporal mistakes are auto-captured from your git revert history, so it stops repeating fixes that already failed. Context packets run ~50–90% smaller per file (structural size, not a bill saving — run engram bench on yours). Local SQLite, zero cloud, Apache 2.0.
Try in 30 seconds (no install) ▶

Install Page · Live Demo · Scene Table · rendered with Hyperframes
Install · Quickstart · Dashboard · Benchmark · IDE Integrations · HTTP API · ECP Spec · Contributing
![]()



Try in 30 seconds (no install)

▶ Play the live recording · or get the raw cast at docs/demos/v4-skill-pack.cast (asciinema play) · or generate it yourself with v4-skill-pack-demo.sh
Or paste this into your terminal — same flow, no global install, no commitment. Creates a throwaway repo with a reverted bug, then runs engram against the public npm registry:
mkdir -p /tmp/engram-demo && cd /tmp/engram-demo && \
git init -q && git commit --allow-empty -q -m "init" && \
echo "export const buggy = () => null;" > src.ts && \
git add -A && git commit -q -m "feat: add buggy helper returning null causing form crashes" && \
git revert --no-edit HEAD > /dev/null && \
npx --yes [email protected] init . && \
npx --yes [email protected] mistakes
You should see, within 30 seconds, the bi-temporal pre-mortem engram auto-captured from your revert:
⚠️ 1 mistake(s) recorded:
⚠ Mistake #1 — 2026-05-19
┌─ then you believed: feat: add buggy helper returning null causing form crashes
├─ found false: 2026-05-19
└─ truth now: Reverted in <sha> (2026-05-19)
ref: src.ts
applies to: git revert touching src
That's the rave moment — engram remembering what your AI agent forgot, surfaced before the next edit. Multiply this across your actual repo's revert history, and it works on every Claude Code session automatically.
When you're ready: scroll to Install for the global install path.
Why this exists, May 2026
Three things broke at the same time. Cursor went usage-based and people started getting $1,400 surprise bills. Anthropic tightened Claude Code limits, then quietly tested removing it from the $20 Pro plan. Half the AI coding crowd migrated from one tool to the other, hit the new ceiling within a week, and started looking for any way to make a session last longer.
Engramx is what makes the session last longer. It indexes your codebase into a local SQLite knowledge graph once. Then it intercepts file reads at the agent boundary and replaces them with a structural summary the agent already has the working memory for. Same edit, same diff, same code shipped — fewer tokens consumed in the round trip.
On engramx's own repo the per-file structural context reduction is ~89% (89.5% in the latest bench/real-world.ts run, size-guarded so it never counts a file engram wouldn't shrink). Across eight real OSS repos it ranges roughly 50–90% — highest on large-file Python/Go codebases, lower on many-small-file projects (bench/real-world.ts reproduces it on any project you point it at). This is a structural context-packet reduction measured per file, not an agent-loop cost saving, and it varies by repo. Independent migration guides (dev.to/56kode, SpectrumAI Lab) cite engram for the strongest measured structural reduction in the category.
Works in 8 IDEs and counting — Claude Code, Cursor, Cline, Continue.dev, Aider, Windsurf, Zed, OpenAI Codex CLI. One install, one graph, every tool benefits. Apache 2.0. Local SQLite. Nothing leaves your machine.
v4.4.0 "Curve" — 2026-06-14. New:
engram measure --sessionproves the combined whole-session structural reduction by replaying your hook-log as an honest per-session break-even-P curve (Token-loop C). The recall bench now ships confidence intervals and counts import edges (it was under-measuring). Honest, repo-dependent numbers: recall@10 ≈ 43% / 17% / 25% (own repo / a mature external library / an app), with the ranker beating random ordering by +5.6pp / +4.4pp / ~0 respectively. Runengram benchon yours — and note the durable wins are the mistakes memory + capacity, not a recall number. Plus:query/genfail loudly on a bad--project, a hermetic skills test, and a front door that leads with the differentiator, not the number. Still no cost claims — a structural reduction, not a bill saving.v4.3 "Proof" shipped 2026-06-05 — engram's saving is now real and provable. Run
engram measurein your own repo to see the honest structural context-token reduction on your code — every disclosure computed live: it's a ceiling, here's the recall, here's the intercept rate, "structural tokens, not your bill." Runnpm run bench:recallfor the reproducible proof that engram surfaces the files a change actually touches (recall@10 33% on engram's own repo, decomposed honestly: candidate generation reaches 43%, the PageRank ranker adds +3.2pp over random-within-candidate; 10.4% blind chance).New this release: a never-worse gate on Grep (engram passes through whenever its packet isn't actually smaller — sized to your grep's exact
cwd/path/globscope), Bash-grep interception (the shell-only IDEs — Aider, Codex CLI, Cline — now get the call-site packet too), a sub-agent context broker (a tight ~100-token ranked slice into each spawned Claude Code sub-agent — the one regime prompt caching can't help), and a compaction ledger (a "previously read" list injected at/compactso the agent doesn't re-explore). Every number is a measured fact or a labelled bet — no cost claims; a structural context reduction, not a bill saving (engram's net over prompt caching ≈ 0). 1149 tests. See CHANGELOG.md,docs/COMPARISON.md(vs the other local code-graph tools — ranking isn't unique, the combination is), anddocs/FRONTIER.md.v4.3.1 (patch) — 2026-06-06: a two-swarm execution audit hardened the release. Fixes: the
engram costdigest no longer prints an unqualified dollar/"% saved" figure (it now carries the structural-not-a-bill-saving caveat);bench/statsstate "Nx LARGER — passes through" instead of a backwards "0.2x smaller" on tiny repos; the incremental reindex now rebuilds cross-filecallsedges (no graph drift between full re-indexes) and does so in ~1ms via an mtime-keyed refs cache instead of re-parsing every file on each edit; the MCP server reports its real version;doctorflags a disabled kill-switch;gen --task <bad>errors cleanly. No new features, no behaviour change to the honest claim.v4.3.2 (patch) — 2026-06-06: fixes a broken MCP-setup command in this README — the config block now uses
npx -y -p engramx engram-serve <path>(the previousengramx servehad no such subcommand, so MCP clients failed with "unknown command 'serve'"). Also:gen-ccsnow exports a structural fallback on fresh repos instead of an empty file; TSinterface/type/enumdeclarations are extracted as first-class graph nodes; the git co-change miner no longer emits a self-edge for distinct files sharing a basename; provider warmup probes no longer keep the process alive a few seconds after a session starts. Addsllms-install.mdfor agent-driven setup. No behaviour change to the honest claim.
Earlier release notes (v4.2 "Loop", June 3)
v4.2 "Loop" shipped 2026-06-03 — engram closed the agent's investigation loop. The original Context Spine goal was to collapse the whole grep → read → read loop, not just the single file read. v4.2 shipped a Grep interception that answers a content-mode symbol search from the reference graph with the actual file:line: code call sites — smaller than the raw grep (init is 573 vs 9,317 tokens on engram's own repo) while showing the real usage — and same-session read dedup that returns a pointer instead of re-serving an unchanged file the agent already read. Both are recall-safe (an rg -n escalation; byte-unchanged + PreCompact/SessionStart reset guards) and gated so they only fire when they genuinely save tokens. (v4.1 "Compass" — PageRank-ranked graph + callers/callees/impact traversal.)
Earlier release notes (v3.4 "Universal Spine", May 2)
v3.4 "Universal Spine" shipped 2026-05-02 — multi-IDE detector covers 8 tools, Anthropic Claude Code plugin submitted to the official directory (in review), VS Code / Cursor extension live as nickcirv.engram-vscode on OpenVSX, engramx-continue on npm, Cline integration documented. Cost Lens telemetry from v3.3.0 feeds a weekly Markdown digest at ~/.engram/cost-report-YYYY-Www.md. 1007 tests, CI green on Ubuntu + Windows × Node 20 + 22.
Earlier release notes (v3.0 "Spine", April 24)
EngramX v3.0 "Spine" shipped 2026-04-24 — the biggest release before v3.4. The spine is extensible: any MCP server becomes an EngramX provider via a 10-line plugin file. Pre-mortem mistake-guard warns before you repeat a bug. Bi-temporal mistake memory — refactored-away mistakes stop firing. Anthropic Auto-Memory bridge reads Claude Code's own consolidated memory. SSE-streaming packets render progressively. engram gen dual-emits AGENTS.md + CLAUDE.md by default.
Install in 30 seconds
Three paths depending on where you want engram to live. All three install the same engram; you can stack them.
1. CLI (recommended starting point — works in every supported IDE)
npm install -g engramx
cd ~/your-project
engram setup
engram setup auto-detects every supported IDE on your machine (Claude Code, Cursor, Cline, Continue, Aider, Windsurf, Zed, Codex CLI) and prints the next step for each. You don't have to remember which command to run for which tool.
2. Cursor / VS Code extension (live on OpenVSX)
code --install-extension nickcirv.engram-vscode
Adds six commands to the Cursor / VS Code command palette plus a status-bar entry that opens the cost dashboard with one click. Listing on OpenVSX.
3. Continue.dev users
npm install engramx-continue
Adds engram as an @engram context provider. Package on npm · Integration docs.
The Anthropic Claude Code plugin (
/plugin install engramfrom the official directory) is pending in the official directory. When it lands, that's a fourth install path with zero CLI steps. Until then, path 1 covers Claude Code via hooks.
EngramX — the cached context spine for AI coding agents.
Your AI coding agent keeps re-reading the same files. Every Read, every Edit, every cat re-loads context that's already in your window.
EngramX is the spine. It intercepts every file read at the tool boundary, answers from a pre-assembled context packet held in three layers of cache — a knowledge graph the agent has already "paid" to build, a per-provider SQLite cache of external lookups, and an in-memory LRU of recent queries — and hands the agent a single ~500-token response instead of a raw file.
The agent gets what it needs, structured. And every plugin you add extends what engram can surface — Serena for LSP symbols, GitHub MCP for issue context, Sentry MCP for production errors, Supabase / Neon for schema. Each one closes a context gap the agent would otherwise spend turns researching. (More providers = more capability; whether they net fewer tokens on a given task depends on the task — measure it on yours.)
Per-file structural reduction on a reproducible benchmark: up to ~89% (engramx's own codebase; structural token reduction, not agent-loop cost). On the committed 87-file run, 85 of 87 real source files saw reduced per-file token cost, best case 98.4% (18,820 tokens → 306); a fresh sample of 50 files reduces ~89.5% aggregate. Your per-repo numbers vary — run it on yours.
What this number is (and isn't): ~89% is a per-file structural context reduction measured on engramx's own repo with all 9 providers active — it measures how much smaller engram's context packet is than reading the full files raw. It is not an agent-loop cost-savings figure and will differ on your codebase. Your actual dollar saving depends on your prompt-caching setup and workload — run the benchmark on your own repo (see Benchmark) to get your structural number.
One command to everything
npm install -g engramx
cd ~/my-project
engram setup
That's the install. engram setup runs engram init (builds the graph), engram install-hook (wires the Sentinel into your AI tool), detects your IDE, dual-emits AGENTS.md + CLAUDE.md, then runs engram doctor to verify everything green. Under 30 seconds on most projects. Works in Claude Code, Cursor, Codex CLI, Windsurf, GitHub Copilot Chat, JetBrains Junie, Aider, Zed, Continue — any agent that reads AGENTS.md or uses MCP.
The next session you open starts with the spine pre-loaded: project brief already in context, file reads intercepted, a live HUD showing cumulative savings, bi-temporal mistakes waiting to warn you, and any plugins you've added already answering their domains.
I'm not a developer — what does this actually do?
Short answer: your AI coding assistant stops re-loading the same information into context twice.
Long answer:
- You ask your AI assistant (Claude Code, Cursor, Codex, whatever) to help with a file.
- The assistant tries to read that file. Normally it reads the whole thing, loads every byte into context, and throws most of it away.
- EngramX catches the read, answers with a cached summary (the 50–200 lines the agent actually needs, plus context from your git history, past mistakes, library docs, and anything else useful), and lets the agent work from that.
- The agent works from a compact structural view instead of re-reading whole files. Multi-hour sessions stop hitting context limits, and the agent stops re-introducing bugs you already fixed — because EngramX remembers what broke. (Token-cost impact depends on your workload — engram-counter measures your real number.)
It runs on your laptop. It doesn't send your code anywhere. It's Apache 2.0. There's no account, no login, no cloud. You install it once and forget it's there.
Want engram to understand more? Install a plugin. Each one adds a context source — see Plugins extend what engram understands below. Drop a 10-line .mjs file in ~/.engram/plugins/ and the next session uses it.
Want out? Clean uninstall is one command:
npm uninstall -g engramx # 3.0.1+ auto-runs preuninstall hook-cleanup
If you installed 3.0.0 and ran npm uninstall before the 3.0.1 patch shipped, your Claude Code hooks may be orphaned. Run engram repair-hooks --scope user (install 3.0.1 first if needed) or see the CHANGELOG.md for the manual jq-based recovery one-liner.
Proof, not promises
Everything above is a measured per-file structural reduction on engramx's own files — not estimated, but also not an agent-loop cost figure (your per-repo numbers vary). bench/real-world.ts runs the full resolver against real files in this repo and compares the rich-packet token cost to the raw-file-read cost. Reproducible in one command on any project.
Latest run (2026-04-24, 87 source files — full report at bench/results/real-world-2026-04-24.md):
| Metric | Value |
|---|---|
| Baseline tokens (87 files read raw) | 163,122 |
| engramx tokens (rich packets) | 17,722 |
| Aggregate per-file structural reduction | 89.1% |
| Median per-file structural reduction | 84.2% |
| Files where engramx saved tokens | 85 of 87 |
Best case (src/cli.ts) | 98.4% (18,820 → 306) |
Reproduce on your own code:
cd your-project
engram init # first-time setup for this project
npx tsx /path/to/engram/bench/real-world.ts --project . --files 50
The bench writes a JSON + Markdown report per run into bench/results/. Small projects score lower; dense structural projects score higher. It's real arithmetic on your files — you can audit every number.
What engramx is not
The "engram" name is contested. To save you a search:
- Not Go-Engram (Gentleman-Programming/engram) — different project, Go binary, salience-gated chat memory. Ships under
engram(without thex). - Not DeepSeek's "Engram" paper — January 2026 academic work on conditional memory. Research artifact, not a product.
- Not MemPalace — adjacent positioning ("knowledge-graph memory," "method-of-loci"), but conversational memory, not code-structural.
engramx is specifically: a local-first context spine for AI coding agents that hooks into your IDE's tool boundary, indexes your code via tree-sitter + LSP, remembers past mistakes, and assembles ~500-token context packets in place of raw file reads. Open source, Apache 2.0, single npm install.
Dashboard
A zero-dependency web dashboard ships built-in. One command, opens in your browser:
engram ui
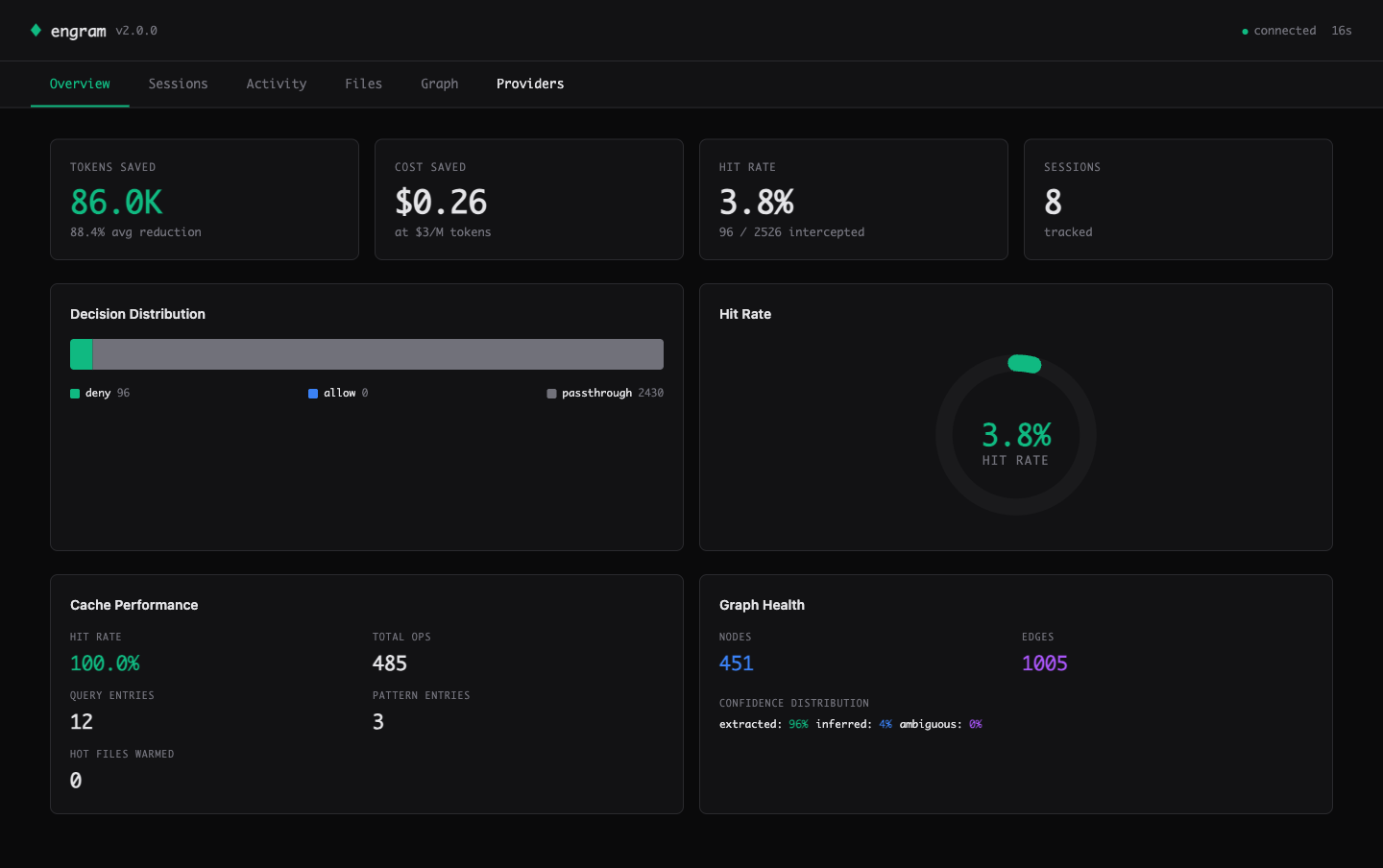
The Overview tab: real metrics from your sessions — context tokens kept out of context (structural), session-level hit rate, cache performance, graph health.
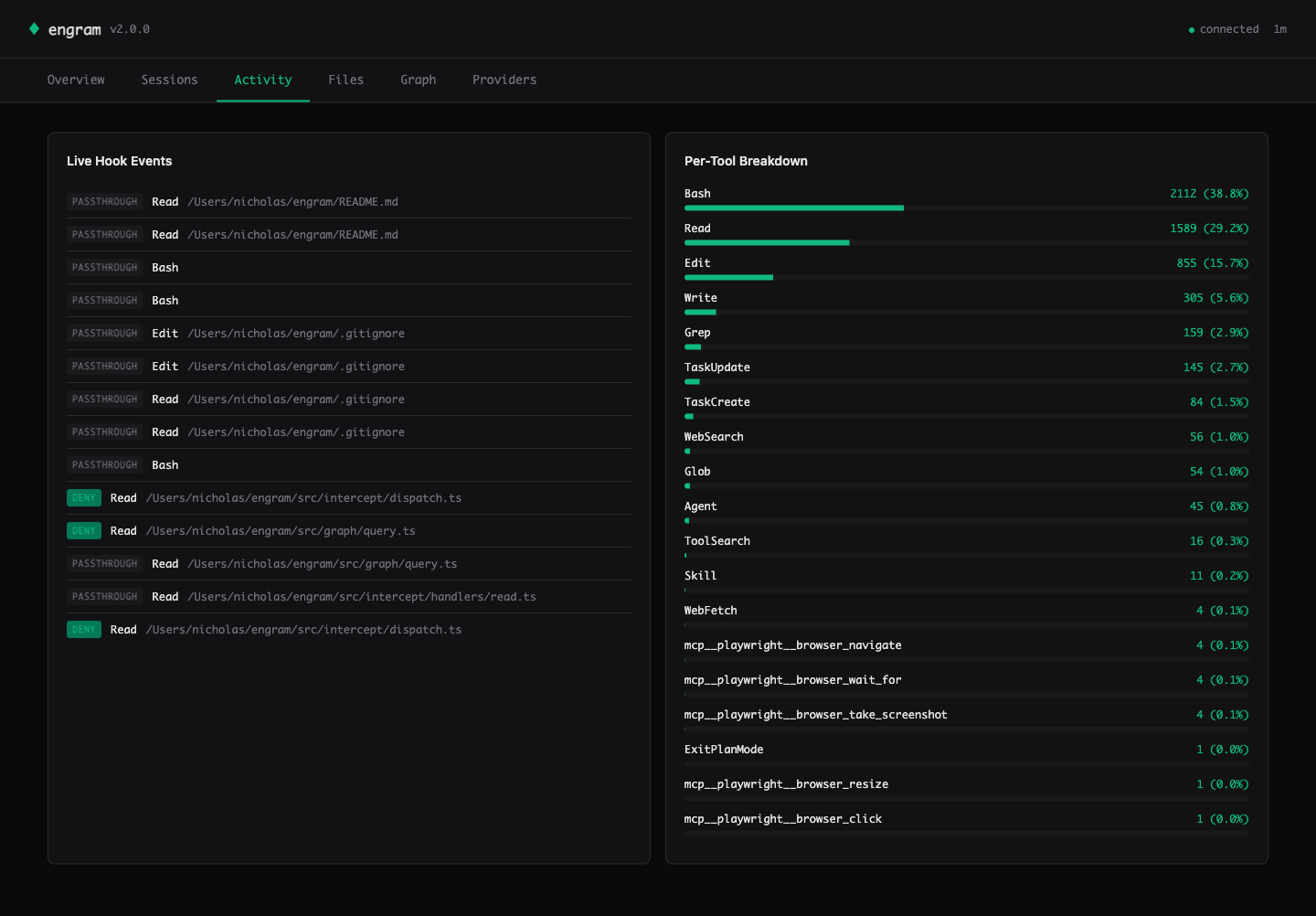
Activity — live hook events streamed via Server-Sent Events. See every Read / Edit / Write decision (deny = intercepted, passthrough = engram couldn't help). Per-tool breakdown on the right shows where the savings come from.
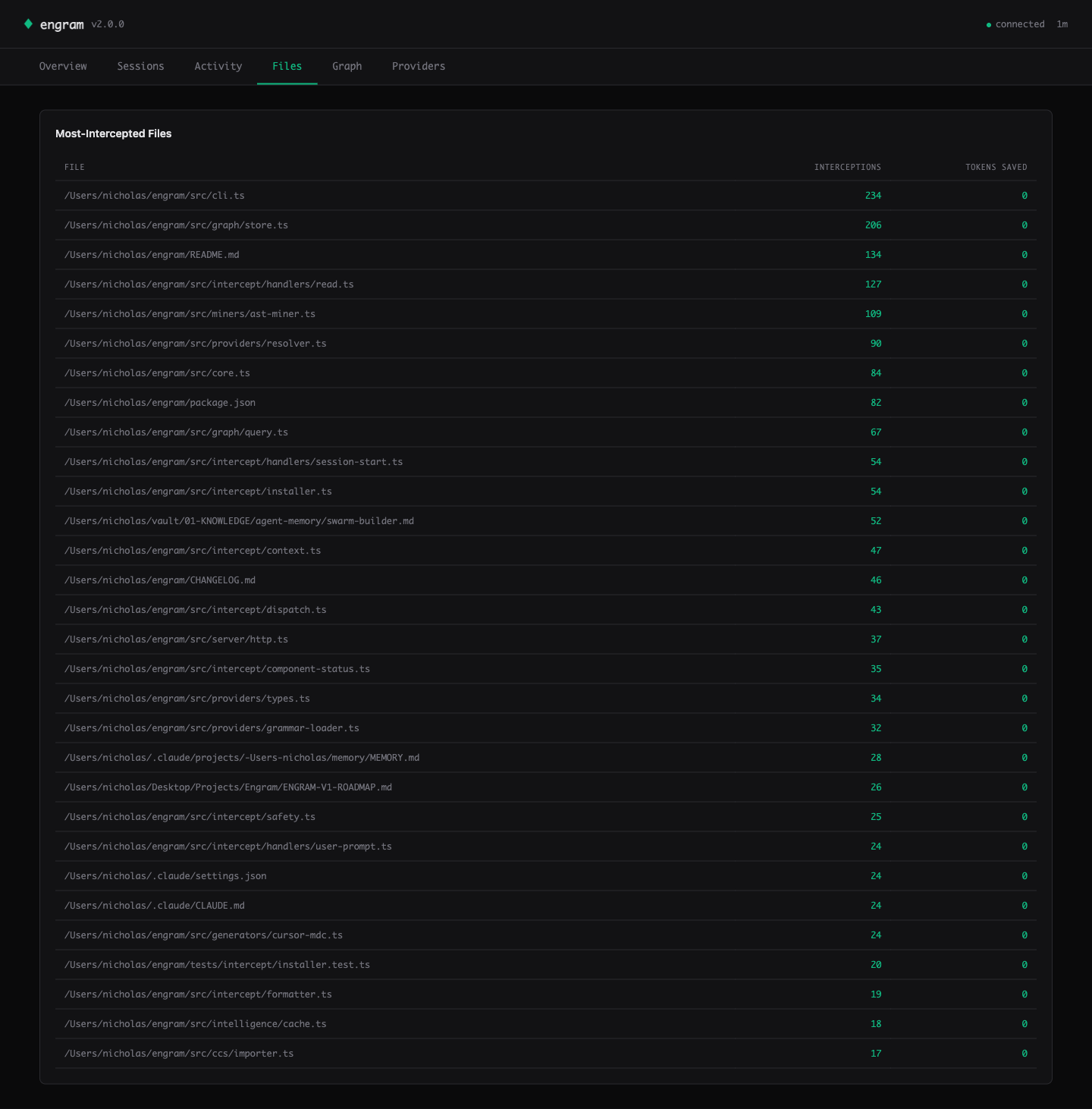
Files — the heatmap ranks your hot files by interception count. Cursor knows this view.
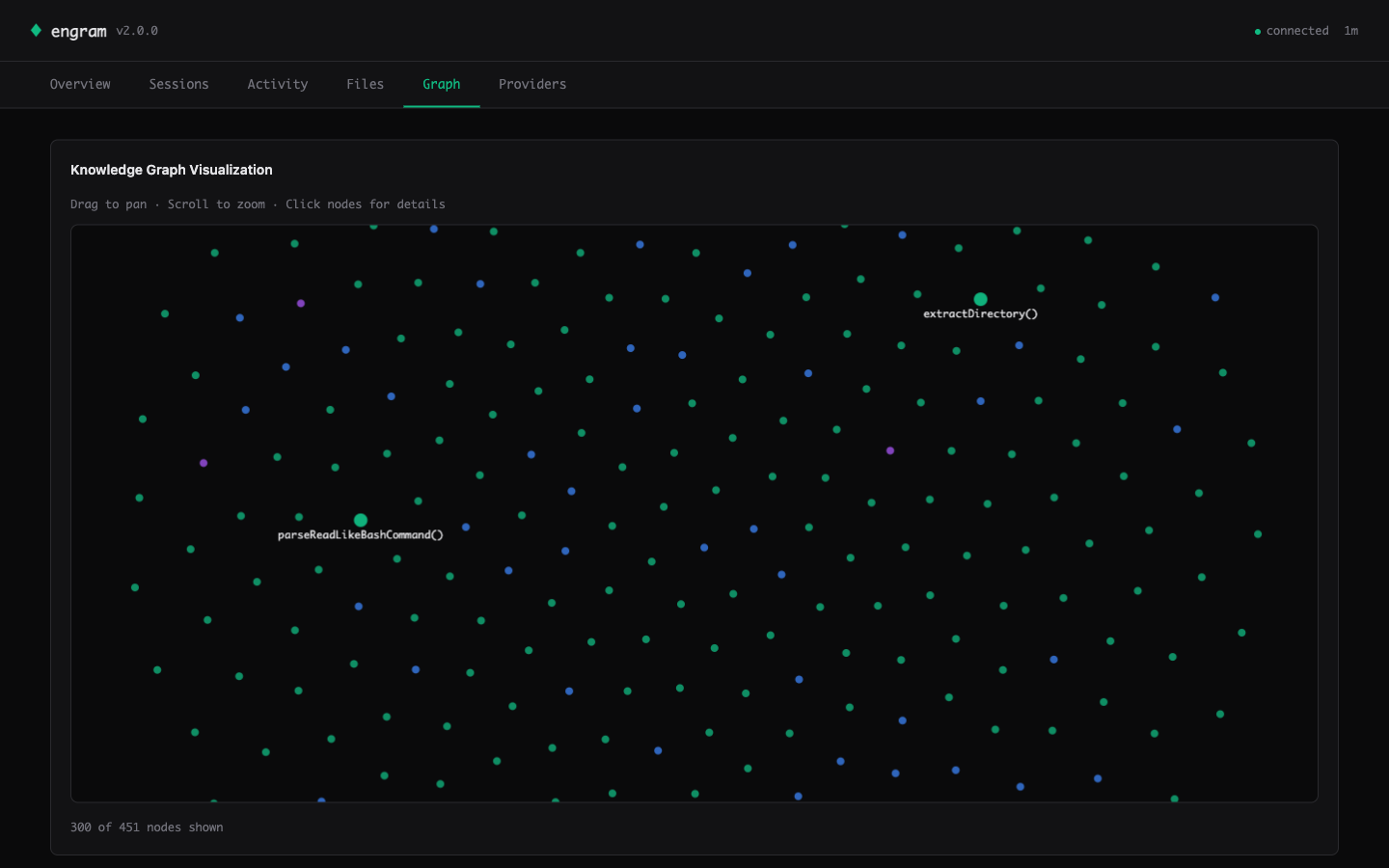
Graph — Canvas 2D force-directed visualization of the knowledge graph. God nodes are larger and labeled. Drag to pan, scroll to zoom, click for details. 300+ nodes at 60fps.
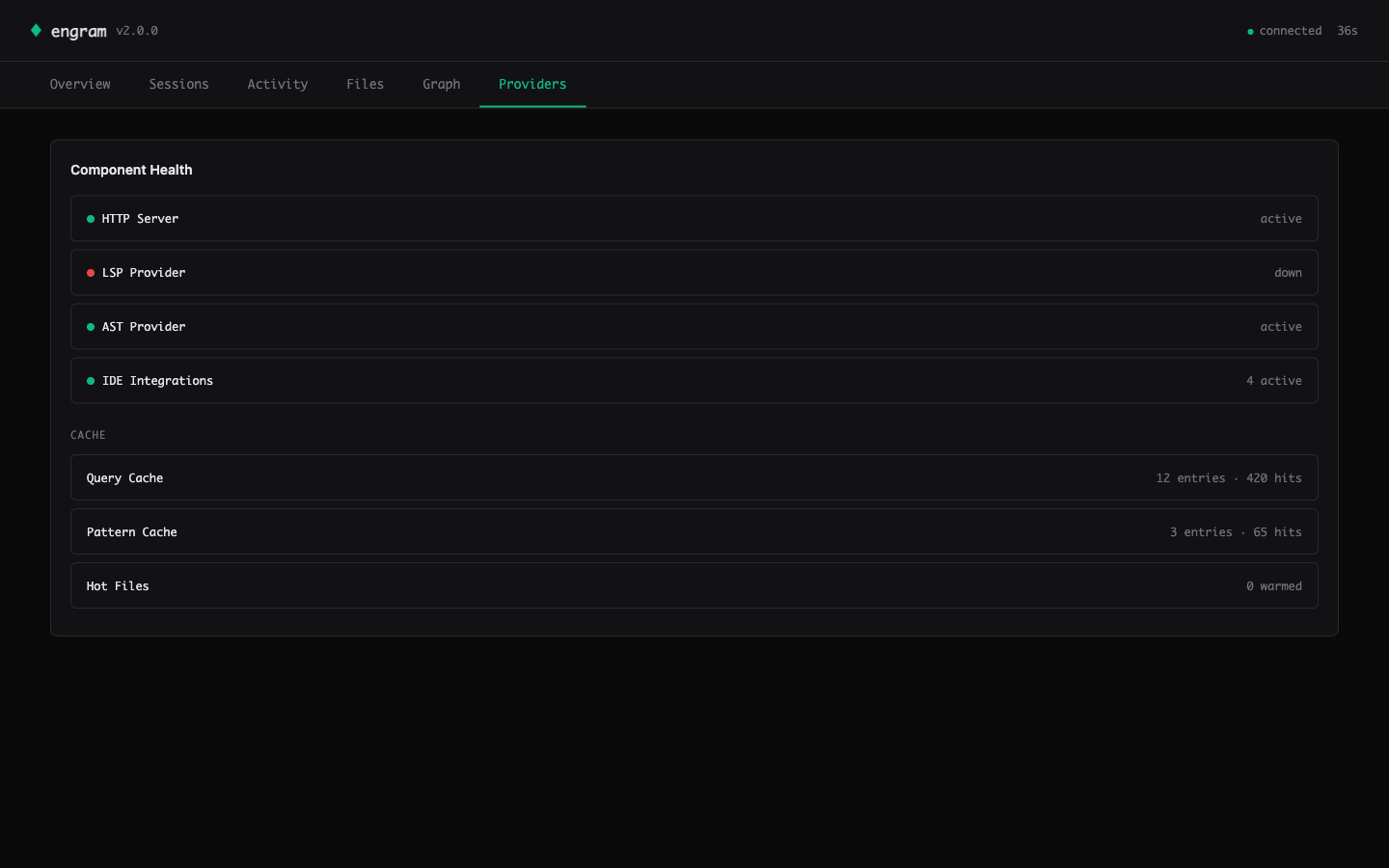
Providers — component health (HTTP / LSP / AST / IDE count) and per-layer cache stats (entries + cross-session hit counts).
Design
- 35KB total — one HTTP response, zero external CDN calls, works offline and on air-gapped machines.
- Zero runtime dependencies — all CSS and JS inlined as TypeScript template literals; SVG charts and Canvas 2D graph hand-rolled (~400 LOC total).
- CSP-hardened —
default-src 'self'; connect-src 'self'meta tag plusesc()at every data-to-HTML boundary. Defends against attacker-controlled file paths and labels mined from untrusted repos. - Live-updating — SSE stream pushes new hook events to the Activity tab within 1 second.
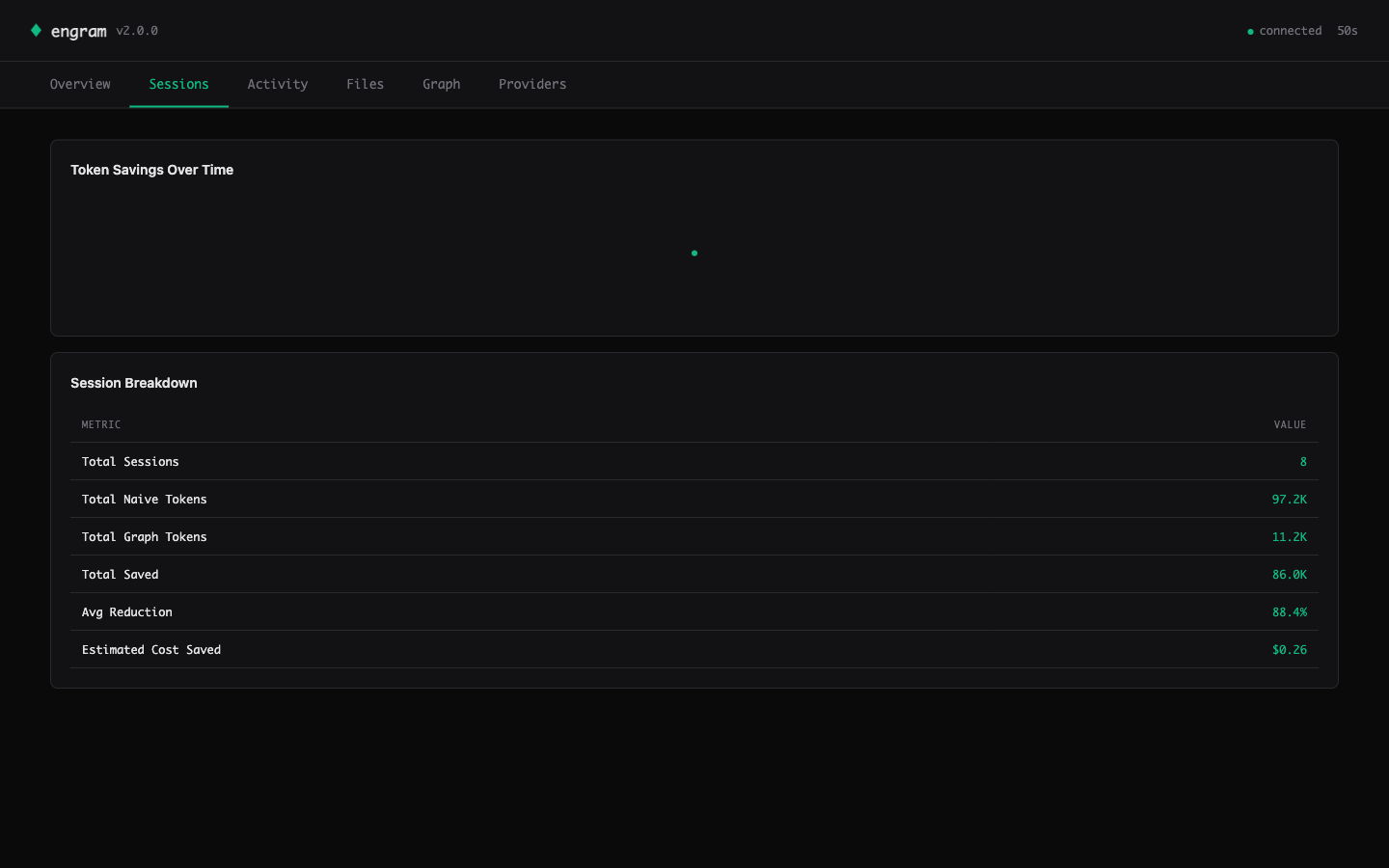
See also the Sessions tab (cumulative breakdown + sparkline) in assets/screenshots/02-sessions.png.
{kind=link}
Benchmark
engramx ships with two benchmarks — use whichever fits your workflow.
Real-world bench (new in v3.0, preferred)
npx tsx bench/real-world.ts --project . --files 50 runs the full resolver against real files in any project and outputs exact token numbers. Don't trust our number — run it on your code and get your structural reduction. The output states its own baseline (full files, read raw and uncached) so the number can't be quoted misleadingly: it's a structural context-packet reduction, not a bill saving — your real cost depends on your prompt-caching setup. See the Proof section above for the reproducible 89.1% per-file structural result on engramx's own repo.
Structured task bench (CI regression)
Measured across 10 structured coding tasks against a baseline of reading the relevant files directly. No synthetic data. No cherry-picked queries.
Per-task structural token reduction (engramx's own repo; not agent-loop cost):
| Task | Baseline (tokens) | engram (tokens) | Structural reduction |
|---|---|---|---|
| task-01-find-caller | 4,500 | 650 | 85.6% |
| task-02-parent-class | 2,800 | 400 | 85.7% |
| task-03-file-for-class | 3,200 | 300 | 90.6% |
| task-04-import-graph | 6,800 | 900 | 86.8% |
| task-05-exported-api | 5,500 | 700 | 87.3% |
| task-06-landmine-check | 8,200 | 850 | 89.6% |
| task-07-architecture-sketch | 14,500 | 1,600 | 89.0% |
| task-08-refactor-scope | 9,200 | 1,100 | 88.0% |
| task-09-hot-files | 3,800 | 550 | 85.5% |
| task-10-cross-file-flow | 12,800 | 1,400 | 89.1% |
| Aggregate | 7,130 | 845 | 88.1% |
Run it yourself: npx tsx bench/runner.ts (structured fixtures) or npx tsx bench/real-world.ts (live resolver on real files).
Plugins extend what engram understands
The 89.1% per-file structural number is engramx with all 9 built-in providers on its own codebase. Every MCP server you plug in closes another context gap the agent would otherwise burn tokens researching. And because every provider is budget-capped and the resolver is budget-weighted + mistakes-boost reranked, more plugins = more relevant context without packet bloat.
| Plugin | Closes this gap | Install |
|---|---|---|
| Serena (LSP symbols, 20+ languages) | Cross-file references engramx's AST can't resolve precisely — kills the grep-then-read loop | cp docs/plugins/examples/serena-plugin.mjs ~/.engram/plugins/ |
| GitHub MCP (issues, PRs, commits) | Recent PR discussion & issue history for the file being edited | engram plugin install github |
| Sentry MCP (production errors) | "What broke in prod for this file" — cuts the open-dashboard → paste-trace loop | engram plugin install sentry |
| Supabase / Neon (schema, RLS) | Database schema context when editing queries / migrations / ORM models | engram plugin install supabase |
| Context7 (library docs) | Always-current API surface for your actual imports | shipped as a built-in |
| Anthropic Auto-Memory | Claude Code's own consolidated project memory | shipped — auto-detected when ~/.claude/projects/…/memory/MEMORY.md exists |
Writing a plugin is ~10 lines — see docs/plugins/README.md for the full spec + examples.
What It Does
engram sits between your AI agent and the filesystem. When the agent reads a file, engram checks its knowledge graph. If the file is covered with sufficient confidence, it blocks the read and injects a compact context packet instead. The packet is assembled from up to 9 built-in providers plus any plugins you've added, all pre-cached at session start.
The 9 built-in providers (v3.0):
| Provider | Source | Confidence | Latency |
|---|---|---|---|
engram:ast | Tree-sitter parse (10 languages) | 1.0 | <50ms |
engram:structure | Regex heuristics (fallback) | 0.85 | <50ms |
engram:mistakes | Past failure nodes (bi-temporal — stale mistakes filtered out) | — | <10ms |
anthropic:memory | Claude Code's auto-managed MEMORY.md index (v3.0) | 0.85 | <10ms |
engram:git | Co-change patterns, churn, authorship | — | <100ms |
mempalace | Decisions, learnings, project context | — | <5ms cached |
context7 | Library API docs for detected imports | — | <5ms cached |
obsidian | Project notes, architecture docs | — | <5ms cached |
engram:lsp | Live diagnostics captured as mistake nodes | — | on-event |
External providers cache into SQLite at SessionStart. Per-read resolution is a cache lookup, not a live call. If a provider is unavailable it is skipped silently — you always get at least the structural summary. Plus: any MCP server becomes a provider via a 10-line plugin file — see Plugins extend what engram understands above.
The 9 hook handlers:
| Hook | What it does |
|---|---|
PreToolUse:Read | Blocks the read if file is covered. Delivers structural summary as the block reason. |
PreToolUse:Edit | Passes through. Injects known mistakes as landmine warnings alongside the edit. |
PreToolUse:Write | Same as Edit — advisory injection only, never blocks writes. |
PreToolUse:Bash | Catches cat | head | tail | less | more <single-file> and delegates to the Read handler. |
SessionStart | Injects a compact project brief (god nodes, graph stats, top landmines, git branch). Bundles MemPalace context in parallel. |
UserPromptSubmit | Extracts keywords from the prompt, runs a budget-capped pre-query, injects results before the agent responds. |
PostToolUse | Observer only. Writes to .engram/hook-log.jsonl for hook-stats. |
PreCompact | Re-injects god nodes and active landmines right before Claude compresses the conversation. Survives compaction. |
CwdChanged | Auto-switches project context when you navigate to a different repo mid-session. |
Ten safety invariants enforced at runtime:
- Any handler error → passthrough (Claude Code is never blocked)
- 2-second per-handler timeout
- Kill switch (
.engram/hook-disabled) respected by every handler - Atomic settings.json writes with timestamped backups
- Never intercept outside the project root
- Never intercept binary files or secrets (
.env,.pem,.key,id_rsa, etc.) - Never log user prompt content (privacy invariant, asserted in tests)
- Never inject more than 8,000 chars per hook response
- Stale graph detection — file mtime newer than graph mtime → passthrough
- Partial-read bypass — explicit
offsetorlimiton Read → passthrough
Install
npm install -g engramx
Requires Node.js 20+. Zero native dependencies. No build tools. Local SQLite via sql.js WASM — no Rust, no Python, no system libs.
Prefer a designed walkthrough? Open docs/install.html — three-step install, benefits matrix, IDE coverage, FAQ. Local file, opens in any browser. Brand-matched terminal-mono aesthetic.
Quickstart
One command, zero friction:
cd ~/my-project
engram setup # init + install-hook + adapter detect + doctor
engram setup runs the whole first-run flow interactively (or pass -y for defaults, --dry-run to preview). It is idempotent — safe to re-run, and skips any step already done.
Prefer the individual commands?
cd ~/my-project
engram init # scan codebase → .engram/graph.db (~40ms, 0 tokens)
engram install-hook # wire the Sentinel into Claude Code
engram ui # open the web dashboard in your browser
Diagnostics + self-update:
engram doctor # component health + remediation hints (0=ok, 1=warn, 2=fail)
engram update # check + upgrade via detected pkg manager (no telemetry)
engram update --check # check only, dry-probe the registry
Set ENGRAM_NO_UPDATE_CHECK=1 to disable the passive "newer version available" hint on every CLI invocation. $CI does the same automatically.
Open a Claude Code session. When the agent reads a well-covered file you will see a system-reminder with the structural summary instead of file contents. After the session:
engram hook-stats # what was intercepted, tokens saved (CLI)
engram ui # same data, richer view, real-time updates
engram hook-preview src/auth.ts # dry-run: see what the hook would inject for one file
Full recommended setup (one-time per project):
npm install -g engramx
cd ~/my-project
engram init --with-skills # also index ~/.claude/skills/ into the graph
engram install-hook # wire Sentinel into Claude Code
engram hooks install # auto-rebuild graph on every git commit
Experience tiers — each works standalone:
| Tier | What you run | What you get |
|---|---|---|
| Graph only | engram init | CLI queries, MCP server, engram gen for CLAUDE.md |
| + Sentinel | engram install-hook | Automatic Read interception, Edit warnings, session briefs, HUD |
| + Context Spine | Configure providers.json | Rich packets from 9 built-ins + any MCP plugin per read |
| + Skills index | engram init --with-skills | Graph includes your ~/.claude/skills/ |
| + Git hooks | engram hooks install | Graph rebuilds on every commit, stays current |
| + HTTP server | engram server --http | REST API on port 7337 for external tooling |
IDE Integrations
engram setup auto-detects every supported IDE on your machine and prints the right next-step for each. You don't have to remember which command to run — the detector knows.
| IDE | Integration | Setup |
|---|---|---|
| Claude Code | Hook-based interception (native, automatic) — plus /plugin install engram for slash-commands | engram install-hook · docs/integrations/claude-code.md |
| Cursor | MDC snapshot + native MCP + VS Code extension on OpenVSX | engram gen-mdc · docs/integrations/cursor-mcp.md |
| Cline | MCP server (5M+ VS Code installs, no native answer to token burn) | docs/integrations/cline.md |
| Continue.dev | @engram context provider via engramx-continue | docs/integrations/continue.md |
| Aider | Context file generation | engram gen-aider · docs/integrations/aider.md |
| Windsurf (Codeium) | .windsurfrules snapshot + MCP | engram gen-windsurfrules |
| Zed | Context server (/engram) | engram context-server · docs/integrations/zed.md |
| OpenAI Codex CLI | AGENTS.md auto-emit (universal Linux Foundation standard) | engram gen (default emits both AGENTS.md + CLAUDE.md) |
| VS Code (any agent) | Status-bar entry + 6 commands wrapping the CLI | code --install-extension nickcirv.engram-vscode (OpenVSX listing) |
| Neovim | MCP via codecompanion / avante | docs/integrations/neovim.md |
| Emacs | MCP via gptel-mcp | docs/integrations/emacs.md |
Per-IDE setup guides are in docs/integrations/.
How It Compares
The "context spine" slot — local-first, code-aware, works in any MCP runtime, with a reproducible benchmark — is currently unowned. Here's the field as of May 2026:
| engramx | Cursor index | Aider repo map | Cline | Continue.dev | Mem0 | claude-mem | CartoGopher | |
|---|---|---|---|---|---|---|---|---|
| Works in any MCP runtime | ✅ | IDE-locked | Aider only | VS Code only | VS Code only | ✅ | Claude Code only | ✅ |
| Local-first (nothing leaves machine) | ✅ | cloud-synced | ✅ | ✅ | ✅ | optional | ✅ | ✅ |
| Code-aware AST graph | ✅ | proprietary | ✅ | — | — | — | — | ✅ |
| Reproducible structural benchmark | ✅ 89.1% (per-file, own repo) | — | — | — | — | — | — | claims 88% |
| Bi-temporal mistake memory | ✅ | — | — | — | — | — | partial | — |
AGENTS.md + CLAUDE.md dual-emit | ✅ | — | — | — | — | — | — | — |
| Single npm install | ✅ | full IDE | pip | VS Code ext | VS Code ext | pip / npm | claude plugin | Go binary |
| License | Apache 2.0 | proprietary | Apache 2.0 | Apache 2.0 | Apache 2.0 | Apache 2.0 | MIT | unknown |
| GitHub stars (May 2026) | 108 | proprietary | 39K | 61.2K | 32.4K | 47.8K | new | unknown |
The matrix isn't a slight at any of them — most do something engram doesn't. Cursor's index is great inside Cursor. Aider's repo map is great in Aider. Cline's full-file rewrite model is honest about what it is. The point is that nobody else covers all eight rows. Engram is the only tool that does.
For the legacy comparison vs Continue @RepoMap / Cursor .cursorrules / @199-bio/engram (small repo-map approaches), see the matrix below.
Legacy detailed comparison
| engram | Continue @RepoMap | Cursor .cursorrules | Aider repo-map | @199-bio/engram | |
|---|---|---|---|---|---|
| Interception model | Hook-based, automatic on every Read | Fetched at @-mention time | Static file, manual | Per-session map | MCP server, called explicitly |
| Cache strategy | SQLite at SessionStart, <5ms per read | No cache — live fetch | No cache | Per-session only | No cache |
| Persistent memory | Decisions, mistakes, patterns across sessions | No | Manual text file | No | No |
| Multiple providers | 9 (AST, git, mistakes, MemPalace, Context7, Obsidian, LSP, Anthropic Memory, MCP plugins) | Repo structure only | No | Repo structure only | Graph query only |
| Mistake tracking | LSP diagnostics → mistake nodes, ⚠️ on Edit | No | No | No | No |
| Survives compaction | Yes (PreCompact hook) | No | Yes (static file) | No | No |
| LLM cost | $0 | $0 | $0 | $0 | $0 |
| Native deps | Zero | No | No | No | No |
Install + Configuration
npm install -g engramx
providers.json (optional — auto-detection works for most setups):
{
"providers": {
"mempalace": { "enabled": true },
"context7": { "enabled": true },
"obsidian": { "enabled": true, "vault": "~/vault" },
"lsp": { "enabled": true }
}
}
Hook scope options:
engram install-hook # default: .claude/settings.local.json (gitignored)
engram install-hook --scope project # .claude/settings.json (committed)
engram install-hook --scope user # ~/.claude/settings.json (global)
engram install-hook --dry-run # preview changes without writing
engram install-hook --auto-reindex # also keep the graph fresh after every Edit/Write/MultiEdit (#8)
Kill switch (if anything goes wrong):
engram hook-disable # touches .engram/hook-disabled — all handlers pass through
engram hook-enable # removes the kill switch
engram uninstall-hook # surgical removal, preserves other hooks in settings.json
Per-feature opt-outs (env vars — disable one behaviour without the kill switch):
ENGRAM_GREP_INTERCEPT=0 # don't answer symbol greps from the reference graph
ENGRAM_READ_DEDUP=0 # don't dedup same-session re-reads of unchanged files
ENGRAM_MISTAKE_GUARD=0 # don't warn before an edit that repeats a past mistake
ENGRAM_NO_UPDATE_CHECK=1 # silence the passive "newer version available" hint
All interception is on by default and recall-safe; these let you turn off a single behaviour (e.g. in a hook config or shell profile) while keeping the rest.
CLI Reference
Core:
engram init [path] # scan codebase, build knowledge graph
engram init --with-skills # also index ~/.claude/skills/
engram query "how does auth" # query the graph (BFS, token-budgeted)
engram query "auth" --dfs # DFS traversal
engram gods # most connected entities
engram stats # node/edge counts, confidence breakdown
engram bench # token reduction benchmark (10 tasks)
engram stress-test # full stress test suite
engram path "auth" "database" # shortest path between concepts
engram learn "chose JWT..." # add a decision or pattern to the graph
engram mistakes # list known landmines
Code generation:
engram gen # auto-detect target (CLAUDE.md / .cursorrules / AGENTS.md)
engram gen --target claude # write to CLAUDE.md
engram gen --target cursor # write to .cursorrules
engram gen --target agents # write to AGENTS.md
engram gen --task bug-fix # task-aware view (general | bug-fix | feature | refactor)
engram gen --memory-md # write structural facts to Claude's native MEMORY.md
engram gen-mdc # generate Cursor MDC rules
engram gen-aider # generate Aider context file
engram gen-ccs # generate CCS-compatible output
Sentinel:
engram intercept # hook entry point (called by Claude Code, reads stdin)
engram install-hook # install hooks into Claude Code settings
engram uninstall-hook # remove engram entries
engram hook-stats # summarize .engram/hook-log.jsonl
engram hook-stats --json # machine-readable output
engram hook-preview <file> # dry-run Read handler for a specific file
engram hook-disable # kill switch
engram hook-enable # remove kill switch
Infrastructure:
engram watch [path] # live file watcher — incremental re-index on save
engram reindex <file> # re-index one file (editor/hook/CI primitive, issue #8)
engram reindex-hook # PostToolUse hook entry point (reads JSON from stdin, always exits 0)
engram dashboard [path] # live terminal dashboard
engram hud-label [path] # JSON label for Claude HUD --extra-cmd integration
engram hooks install # install post-commit + post-checkout git hooks
engram hooks status # check git hook installation
engram hooks uninstall # remove git hooks
engram server --http # start HTTP REST server on port 7337
engram context-server # start Zed context server
engram tune --dry-run # auto-tune provider weights (preview mode)
engram db status # schema version, migration state
engram init --from-ccs # import from CCS-format context file
Claude HUD integration:
Add --extra-cmd="engram hud-label" to your statusLine command to see live savings:
engram 48.5K saved 75%
HTTP API
Start the server with engram server --http (default port 7337).
| Method | Endpoint | Description |
|---|---|---|
GET | /health | Server health + graph stats |
POST | /query | Query the knowledge graph |
GET | /gods | Most connected entities |
GET | /stats | Node/edge counts, confidence breakdown |
POST | /path | Shortest path between two concepts |
GET | /mistakes | Known failure nodes |
POST | /learn | Add a decision or pattern |
POST | /init | Trigger a graph rebuild |
GET | /hook-stats | Hook interception log summary |
All responses are JSON. The server is local-only by default — bind address is 127.0.0.1.
MCP Server
{
"mcpServers": {
"engram": {
"command": "npx",
"args": ["-y", "-p", "engramx", "engram-serve", "/path/to/your/project"]
}
}
}
MCP Tools (6):
query_graph— search the knowledge graph with natural languagegod_nodes— core abstractions (most connected entities)graph_stats— node/edge counts, confidence breakdownshortest_path— trace connections between two conceptsbenchmark— token reduction measurementlist_mistakes— known failure modes from past sessions
Shell wrapper (for Bash-based agents):
cp scripts/mcp-engram ~/bin/mcp-engram && chmod +x ~/bin/mcp-engram
mcp-engram query "how does auth work" -p ~/myrepo
ECP Spec
engram v1.0 ships the first draft of the Engram Context Protocol (ECP v0.1) — an open specification for how AI coding tools should package and exchange structured context packets.
The spec defines the wire format, provider negotiation, budget constraints, and confidence scoring used by engram internally. Any tool can implement the spec to produce or consume engram-compatible context packets.
License: CC-BY 4.0
Spec: docs/specs/ecp-v0.1.md
Programmatic API
import { init, query, godNodes, stats } from "engramx";
const result = await init("./my-project");
console.log(`${result.nodes} nodes, ${result.edges} edges`);
const answer = await query("./my-project", "how does auth work");
console.log(answer.text);
const gods = await godNodes("./my-project");
for (const g of gods) {
console.log(`${g.label} — ${g.degree} connections`);
}
Architecture
src/
├── cli.ts CLI entry point
├── core.ts API surface (init, query, stats, learn)
├── serve.ts MCP server (6 tools, JSON-RPC stdio)
├── server.ts HTTP REST server (port 7337)
├── hooks.ts Git hook install/uninstall
├── autogen.ts CLAUDE.md / .cursorrules / MDC generation
├── graph/
│ ├── schema.ts Types: nodes, edges, confidence, schema versioning
│ ├── store.ts SQLite persistence (sql.js WASM, zero native deps)
│ └── query.ts BFS/DFS traversal, shortest path
├── miners/
│ ├── ast-miner.ts Tree-sitter AST extraction (10 languages, confidence 1.0)
│ ├── git-miner.ts Change patterns from git history
│ ├── session-miner.ts Decisions/patterns from AI session docs
│ └── skills-miner.ts ~/.claude/skills/ indexer (opt-in)
├── providers/
│ ├── context-spine.ts Provider assembly + budget management
│ ├── mempalace.ts MemPalace integration
│ ├── context7.ts Context7 library docs
│ ├── obsidian.ts Obsidian vault
│ └── lsp.ts LSP diagnostic capture
└── intelligence/
└── token-tracker.ts Cumulative context-token reduction measurement
Supported languages (AST): TypeScript, JavaScript, Python, Go, Rust, Java, C, C++, Ruby, PHP.
Privacy
Everything runs locally. No data leaves your machine. No telemetry. No cloud dependency. The only network call is npm install. Prompt content is never logged (asserted in the test suite).
Contributing
Issues and PRs welcome at github.com/NickCirv/engram.
Run engram init on a real codebase and share what it got right and wrong. The benchmark suite (engram bench) is the fastest way to see the difference on your own code.
License