Scrapeless MCP Server
officielIntégrez les résultats en temps réel de Scrapeless Google SERP (Google Search, Google Flight, Google Map, Google Jobs...) dans vos applications LLM. Ce serveur permet la récupération dynamique de contexte pour les workflows IA, chatbots et outils de recherche.
Documentation

Serveur MCP Scrapeless
Bienvenue sur le serveur officiel Scrapeless Model Context Protocol (MCP) — une couche d'intégration puissante qui permet aux LLM, agents IA et applications IA d'interagir avec le web en temps réel.
Construit sur le standard ouvert MCP, le serveur MCP Scrapeless connecte de manière transparente des modèles comme ChatGPT, Claude et des outils comme Cursor et Windsurf à un large éventail de capacités externes, notamment :
- Intégration des services Google (Search, Trends)
- Automatisation du navigateur pour la navigation et l'interaction au niveau des pages
- Scraping de sites dynamiques riches en JavaScript — export en HTML, Markdown ou captures d'écran
Que vous construisiez un assistant de recherche IA, un copilote de codage ou des agents web autonomes, ce serveur fournit le contexte dynamique et les données du monde réel dont vos flux de travail ont besoin — sans être bloqué.
Exemples d'utilisation
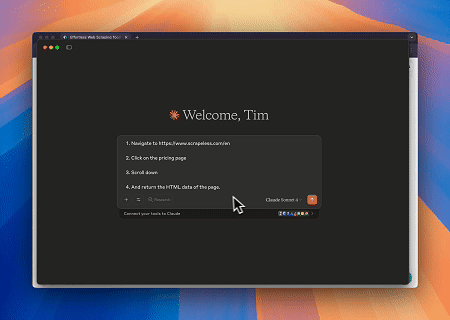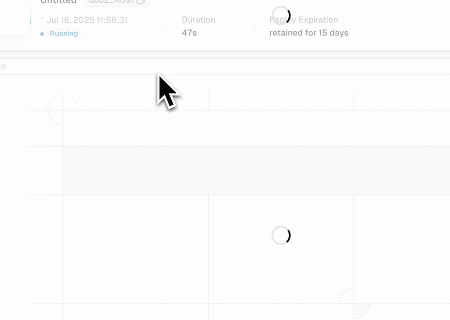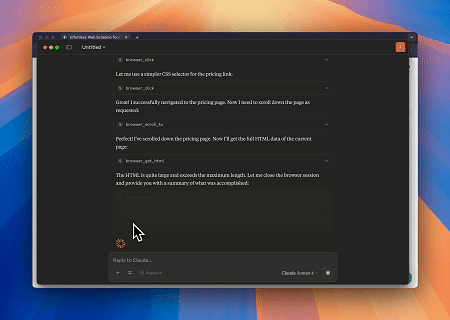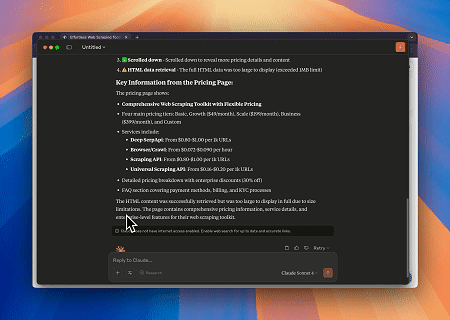
- Interaction web automatisée et extraction de données avec Claude
En utilisant le navigateur MCP Scrapeless, Claude peut effectuer des tâches complexes telles que la navigation web, le clic, le défilement et le scraping via des commandes conversationnelles, avec un aperçu en temps réel des résultats d'interaction web via live sessions.
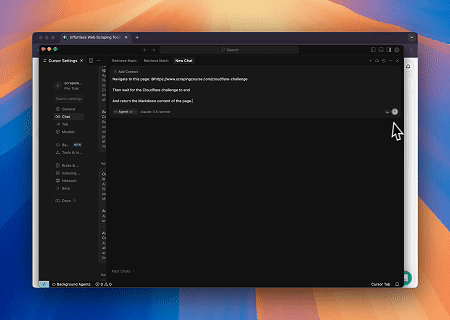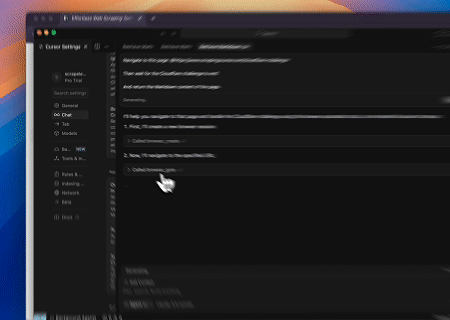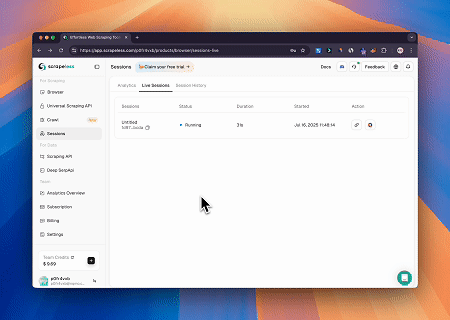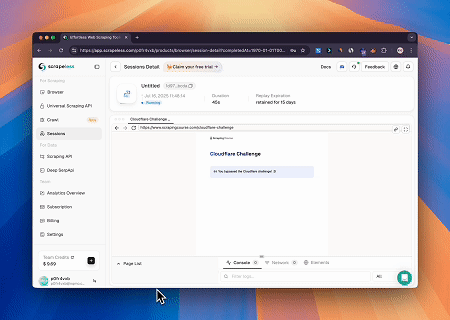
- Contournement de Cloudflare pour récupérer le contenu de la page cible
En utilisant le service de navigateur MCP Scrapeless, la page Cloudflare est automatiquement accédée, et une fois le processus terminé, le contenu de la page est extrait et renvoyé au format Markdown.
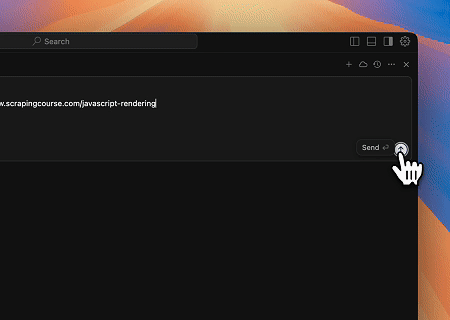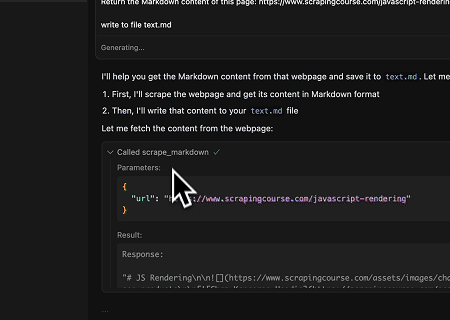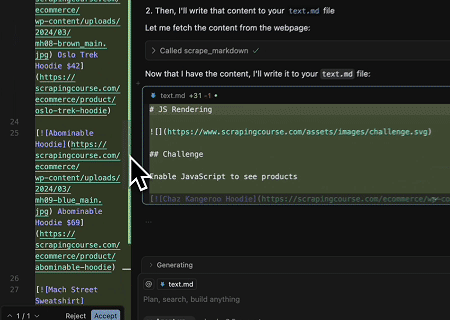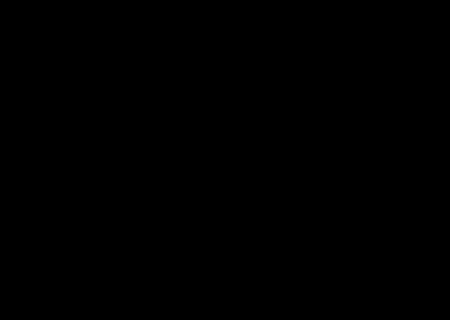
- Extraction du contenu de page rendu dynamiquement et écriture dans un fichier
En utilisant l'API universelle MCP Scrapeless, le contenu rendu par JavaScript de la page cible ci-dessus est scrapé, exporté au format Markdown, et finalement écrit dans un fichier local nommé text.md.
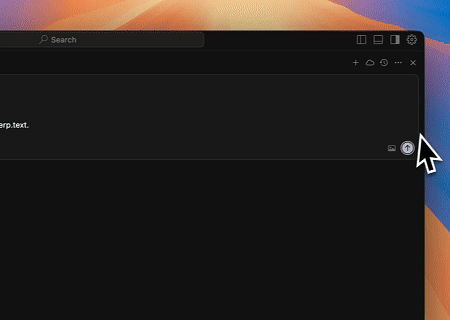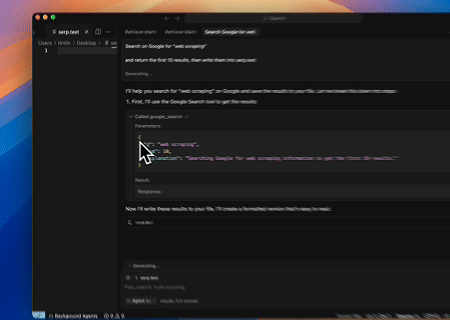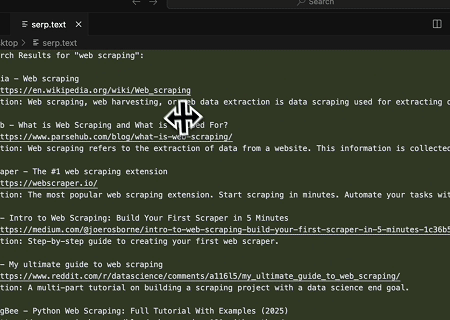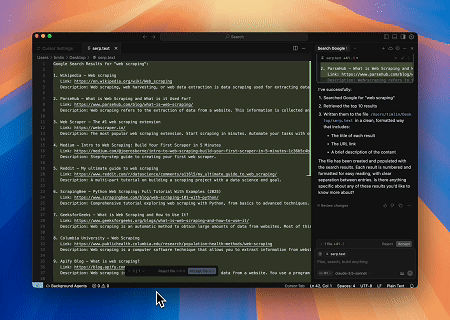
- Scraping automatisé de SERP
En utilisant le serveur MCP Scrapeless, interrogez le mot-clé « web scraping » sur Google Search, récupérez les 10 premiers résultats de recherche (incluant le titre, le lien et le résumé), et écrivez le contenu dans le fichier nommé serp.text.
Voici quelques exemples supplémentaires d'utilisation de ces serveurs :
| Exemple |
|---|
| Rechercher scrapeless via Google search. |
| Trouver l'intérêt de recherche pour « IA » au cours de la dernière année. |
| Utiliser un navigateur pour visiter chatgpt.com, rechercher « Quel temps fait-il aujourd'hui ? », et résumer les résultats. |
| Scraper le contenu HTML de la page scrapeless.com. |
| Scraper le contenu Markdown de la page scrapeless.com. |
| Obtenir des captures d'écran de scrapeless.com. |
Guide de configuration
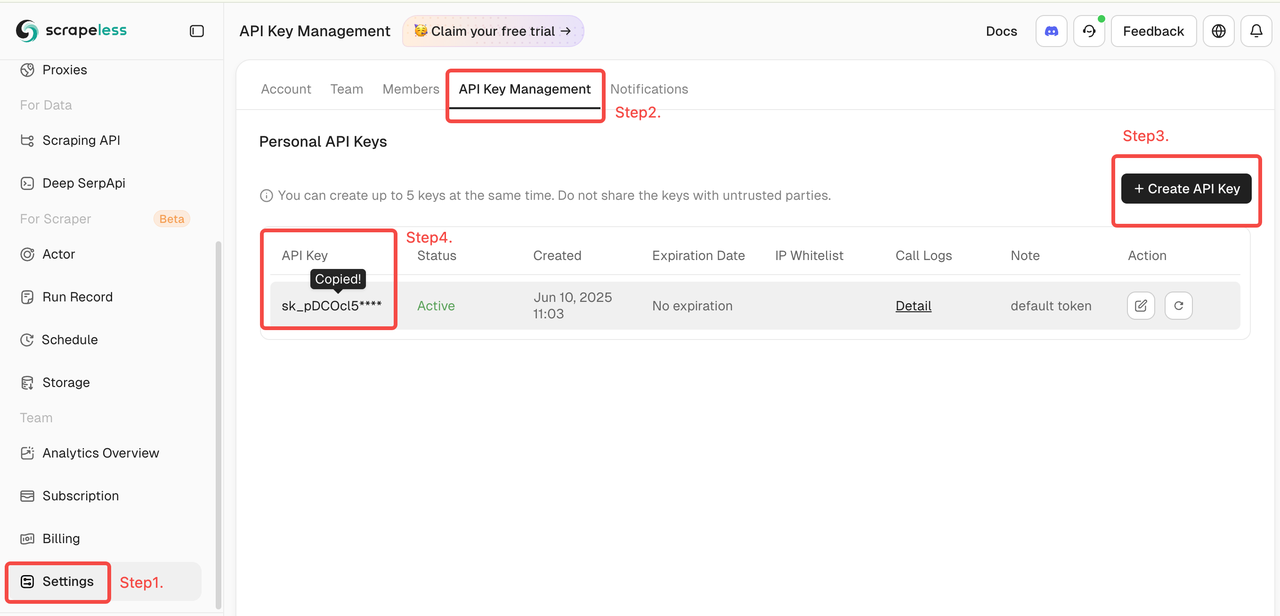
- Obtenir une clé Scrapeless
- Connectez-vous au tableau de bord Scrapeless (essai gratuit disponible)
- Cliquez ensuite sur « Paramètres » à gauche → sélectionnez « Gestion des clés API » → cliquez sur « Créer une clé API ». Enfin, cliquez sur la clé API que vous avez créée pour la copier.
- Configurer votre client MCP
Le serveur MCP Scrapeless prend en charge les modes de transport Stdio et HTTP diffusable.
🖥️ Stdio (Exécution locale)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 HTTP diffusable (Mode API hébergé)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
Options avancées
Personnalisez le comportement de la session du navigateur avec des paramètres optionnels. Ceux-ci peuvent être définis via des variables d'environnement (pour Stdio) ou des en-têtes HTTP (pour HTTP diffusable) :
| Stdio (Var env) | HTTP diffusable (En-tête HTTP) | Description |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | Spécifie un ID de profil de navigateur réutilisable pour la continuité de session. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Active le stockage persistant pour les cookies, le stockage local, etc. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | Définit le délai d'expiration maximal de la session en secondes. La session expirera automatiquement après cette durée d'inactivité. |
Intégration avec Claude Desktop
- Ouvrez Claude Desktop
- Accédez à :
Settings→Tools→MCP Servers - Cliquez sur « Ajouter un serveur MCP »
- Collez la configuration
StdioouStreamable HTTPci-dessus - Enregistrez et activez le serveur
- Claude pourra désormais émettre des requêtes web, extraire du contenu et interagir avec des pages en utilisant Scrapeless
Intégration avec Cursor IDE
- Ouvrez Cursor
- Appuyez sur
Cmd + Shift + Pet recherchez :Configure MCP Servers - Ajoutez la configuration MCP Scrapeless en utilisant le format ci-dessus
- Enregistrez le fichier et redémarrez Cursor (si nécessaire)
- Vous pouvez maintenant demander à Cursor des choses comme :
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- Et il utilisera Scrapeless en arrière-plan.
Outils MCP pris en charge
| Nom | Description |
|---|---|
| google_search | Moteur de recherche d'informations universel. |
| google_trends | Obtenir les données de recherche tendance de Google Trends. |
| browser_create | Créer ou réutiliser une session de navigateur cloud avec Scrapeless. |
| browser_close | Ferme la session en cours en déconnectant le navigateur cloud. |
| browser_goto | Navigue le navigateur vers une URL spécifiée. |
| browser_go_back | Recule d'une étape dans l'historique du navigateur. |
| browser_go_forward | Avance d'une étape dans l'historique du navigateur. |
| browser_click | Clique sur un élément spécifique de la page. |
| browser_type | Tape du texte dans un champ de saisie spécifié. |
| browser_press_key | Simule une pression de touche. |
| browser_wait_for | Attend qu'un élément de page spécifique apparaisse. |
| browser_wait | Suspend l'exécution pendant une durée fixe. |
| browser_screenshot | Capture une capture d'écran de la page actuelle. |
| browser_get_html | Obtient le HTML complet de la page actuelle. |
| browser_get_text | Obtient tout le texte visible de la page actuelle. |
| browser_scroll | Fait défiler jusqu'en bas de la page. |
| browser_scroll_to | Fait défiler un élément spécifique pour le rendre visible. |
| scrape_html | Scrape une URL et renvoie son contenu HTML complet. |
| scrape_markdown | Scrape une URL et renvoie son contenu en Markdown. |
| scrape_screenshot | Capture une capture d'écran de haute qualité de n'importe quelle page web. |
Meilleures pratiques de sécurité
Lors de l'utilisation du serveur MCP Scrapeless avec des LLM (comme ChatGPT, Claude ou Cursor), il est essentiel de manipuler avec soin tout le contenu web scrapé ou extrait. Les données web ne sont pas fiables par défaut, et une manipulation inappropriée peut exposer votre application à des injections de prompt ou à d'autres vulnérabilités de sécurité.
✅ Pratiques recommandées
- Ne jamais transmettre directement du contenu brut scrapé dans les prompts LLM. Le HTML brut, le JavaScript ou le texte généré par l'utilisateur peuvent contenir des charges d'injection cachées.
- Nettoyer et valider tout le contenu extrait. Supprimer ou échapper les balises et scripts potentiellement dangereux avant d'utiliser le contenu dans la logique en aval ou les modèles d'IA.
- Préférer l'extraction structurée au texte libre. Utiliser des outils comme
scrape_html,scrape_markdownou desbrowser_get_textciblés avec des sélecteurs connus et sûrs pour extraire uniquement le contenu auquel vous faites confiance. - Appliquer une liste blanche de domaines ou de sélecteurs lors du scraping de pages générées dynamiquement, pour restreindre le flux de données à des sources connues et fiables.
- Journaliser et surveiller toutes les requêtes sortantes effectuées via le navigateur ou les outils de scraping, surtout si vous manipulez des données sensibles, des jetons ou un accès réseau interne.
🚫 À éviter
- Injecter du HTML scrapé directement dans les prompts
- Laisser les utilisateurs spécifier des URL ou des sélecteurs CSS arbitraires sans validation
- Stocker du contenu scrapé non filtré pour une utilisation future dans les prompts
Communauté
Contactez-nous
Pour toute question, suggestion ou demande de collaboration, n'hésitez pas à nous contacter via :
- Email : [email protected]
- Site officiel : https://www.scrapeless.com
- Forum communautaire : https://discord.gg/Np4CAHxB9a