Reexpress MCP Server
officielActivez la vérification statistique de similarité, distance et magnitude pour vos workflows de recherche, logiciels et science des données.
Documentation
Serveur Reexpress Model-Context-Protocol (MCP)
Pour les LLM capables d'appeler des outils (par exemple, Claude Opus 4.7) et les clients MCP fonctionnant sur macOS (Tahoe 26 ou ultérieur sur Apple silicon) ou Linux
Aperçu vidéo1 : Ici

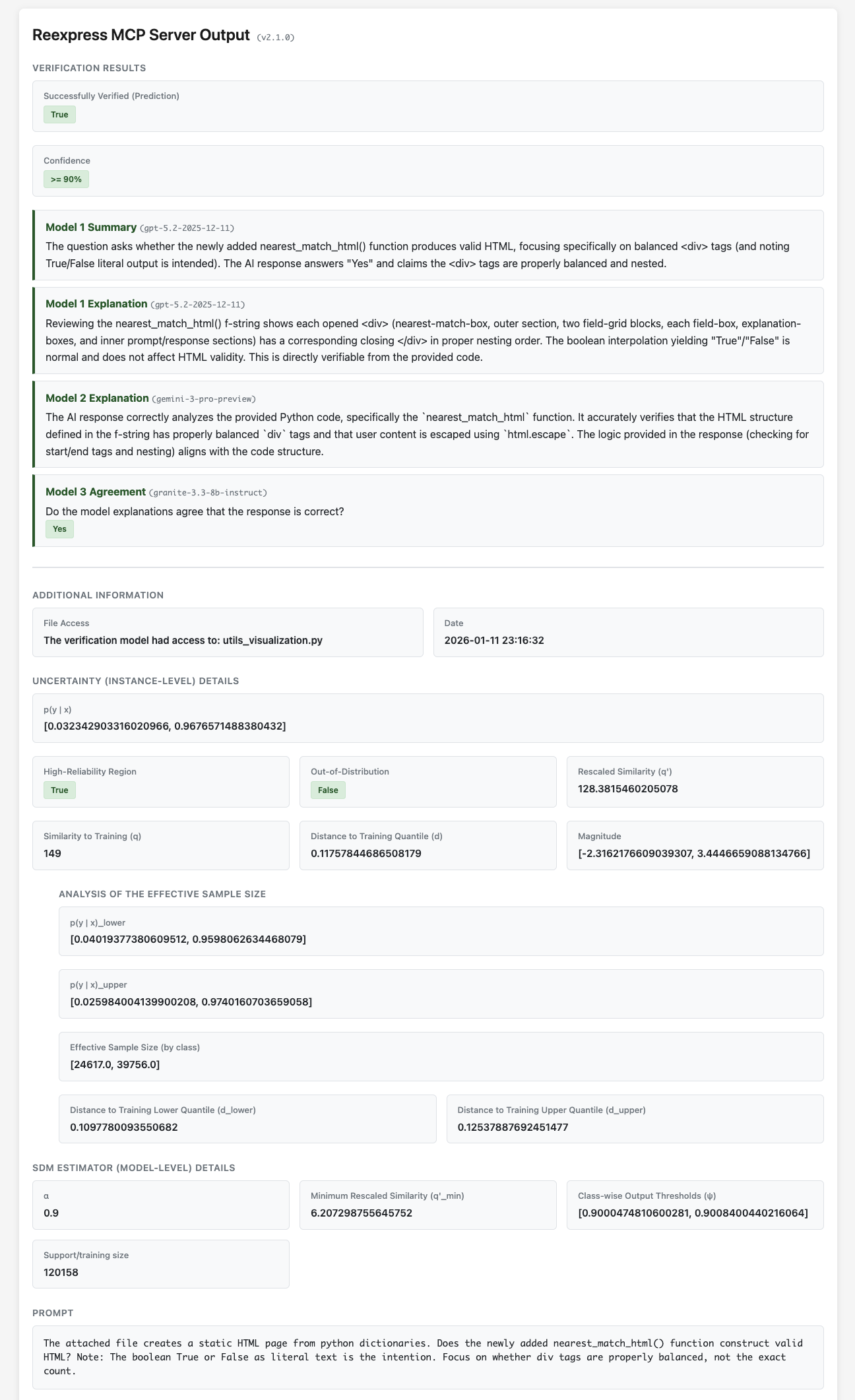

Le serveur Reexpress MCP est une solution prête à l'emploi pour ajouter une vérification statistique de pointe à vos pipelines LLM complexes, ainsi qu'à votre utilisation quotidienne des LLM pour la recherche et l'assurance qualité dans les contextes de développement logiciel et de science des données. C'est le premier second avis IA fiable et statistiquement robuste pour vos flux de travail IA.
Installez simplement le serveur MCP, puis ajoutez l'invite Reexpress à la fin de votre texte de discussion. Le LLM capable d'appeler des outils (par exemple, le modèle LLM d'Anthropic Claude Opus 4.7) vérifiera alors sa réponse avec l'estimateur pré-entraîné Reexpress Similarity-Distance-Magnitude (SDM), qui assemble gpt-5.5-2026-04-23, gemini-3.1-pro-preview et gemini-embedding-2, ainsi que la sortie du LLM appelant l'outil, et calcule une estimation robuste de l'incertitude prédictive par rapport à une base de données d'exemples d'entraînement et de calibration provenant du jeu de données OpenVerification1. Unique à la méthode Reexpress, vous pouvez facilement adapter le modèle à vos tâches : appelez simplement les outils ReexpressAddTrue ou ReexpressAddFalse après qu'une vérification a été effectuée, et les appels futurs à l'outil Reexpress prendront dynamiquement en compte vos mises à jour lors du calcul de la probabilité de vérification. Nous incluons également les scripts d'entraînement du modèle, afin que vous puissiez effectuer un réentraînement complet lorsque des changements plus substantiels sont nécessaires, ou si vous souhaitez utiliser d'autres LLM sous-jacents.
[!NOTE] En plus de vous fournir (l'utilisateur) une estimation fondée de la confiance dans la sortie compte tenu de vos instructions, le LLM appelant l'outil peut lui-même utiliser la sortie de vérification pour affiner progressivement sa réponse, déterminer s'il a besoin de ressources ou d'outils externes supplémentaires, ou s'il est dans une impasse et doit vous demander des clarifications ou des informations supplémentaires. C'est ce que nous appelons le raisonnement avec vérification SDM --- une capacité entièrement nouvelle dans la boîte à outils IA qui, selon nous, ouvrira un éventail beaucoup plus large de cas d'utilisation pour les LLM et les agents LLM, tant pour les particuliers que pour les entreprises.
Les données ne sont envoyées que via des appels API LLM standard vers Azure/OpenAI et Google, les appels gemini-3.1-pro-preview bénéficiant d'un accès standard à la recherche Web via l'API ; tout le traitement de l'estimateur SDM est effectué localement sur votre ordinateur. Reexpress MCP dispose d'un système d'accès aux fichiers simple, conservateur mais efficace : vous contrôlez quels fichiers supplémentaires (le cas échéant) sont envoyés aux API LLM en spécifiant explicitement les fichiers via les outils d'accès aux fichiers ReexpressDirectorySet() et ReexpressFileSet().
Nouveautés de la version 2.4.0
La fiche modèle est disponible ici.
La version 2.4.0 utilise gpt-5.5-2026-04-23 et gemini-3.1-pro-preview comme modèles génératifs. Comme pour la version 2.3.0.preview, gemini-embedding-2 remplace le modèle local granite-3.3-8b-instruct en tant que modèle de représentation d'accord. Cela simplifie grandement l'exécution du serveur, car vous n'avez plus besoin d'exécuter localement un modèle de plusieurs milliards de paramètres. De plus, nous avons également élargi le jeu de données OpenVerification1 avec de nouveaux exemples. Consultez la fiche modèle pour plus de détails.
Notes supplémentaires dans changelog.md.
Configuration requise
Le serveur MCP fonctionne sur Linux et macOS. La principale exigence est que la machine exécutant le serveur MCP soit capable d'exécuter localement un petit modèle PyTorch de 3 millions de paramètres, de sorte que les besoins en calcul sont minimes. (C'est bien écrit : seulement 3 millions de paramètres ; pas 3 milliards de paramètres. Le modèle consiste en une activation SDM sur gemini-embedding-2 et la sortie de classification des deux modèles de langage API.)
Installation
Voir INSTALL.md.
[!TIP] Le serveur Reexpress MCP est simple à configurer par rapport à d'autres serveurs MCP, mais nous supposons une certaine familiarité avec les LLM, MCP et les outils en ligne de commande. Notre public cible est constitué de développeurs et de data scientists. N'ajoutez d'autres serveurs MCP qu'à partir de sources de confiance et gardez à l'esprit que d'autres outils MCP pourraient modifier le comportement de notre serveur MCP de manière inattendue.
Options de configuration
Voir CONFIG.md.
Comment utiliser
Voir documentation/HOW_TO_USE.md.
Génération de HTML statique avec la sortie de l'appel d'outil
Voir documentation/OUTPUT_HTML.md.
Directives
Voir documentation/GUIDELINES.md.
FAQ
Voir documentation/FAQ.md.
Données d'entraînement et de calibration
Voir documentation/DATA.md.
Évaluation sur OpenVerification1
Voir documentation/EVAL.md.
Article de démonstration du système
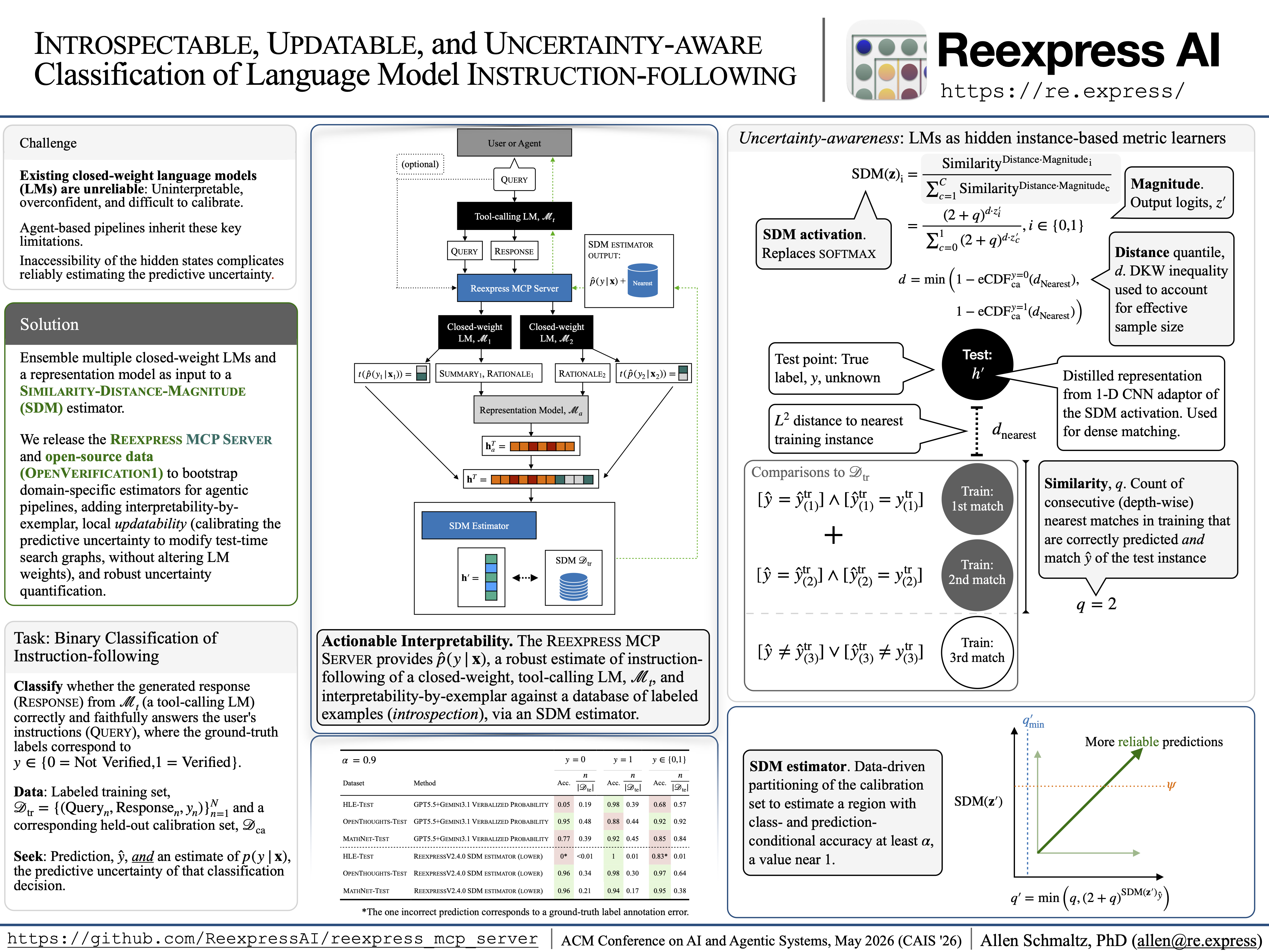
Une copie de notre article de démonstration du système "Introspectable, Updatable, and Uncertainty-aware Classification of Language Model Instruction-following", qui se concentre en particulier sur la version 2.1.0 du serveur Reexpress MCP, est incluse ici. Les scripts de support pour reproduire l'analyse sont inclus ici.
La fiche modèle de la version 2.4.0, qui met en évidence les changements depuis l'article de démonstration du système, est disponible ici.
Citation
Si vous trouvez ce logiciel utile, envisagez de citer les articles évalués par des pairs suivants :
@misc{Schmaltz-2025-SimilarityDistanceMagnitudeActivations,
title={Similarity-Distance-Magnitude Activations},
author={Allen Schmaltz},
year={2025},
eprint={2509.12760},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2509.12760},
note={To appear in \emph{Findings of the Association for Computational Linguistics: ACL 2026}, San Diego, CA, USA.},
}
@inproceedings{Schmaltz-2026-ReexpressMCPServer,
author = {Schmaltz, Allen},
title = {Introspectable, Updatable, and Uncertainty-aware Classification of Language Model Instruction-following},
year = {2026},
isbn = {9798400724152},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3786335.3813214},
doi = {10.1145/3786335.3813214},
abstract = {In this system demonstration paper, we introduce an open-source implementation for training and testing Similarity-Distance-Magnitude (SDM) estimators for the task of binary classification of instruction-following of closed-weight language models (LMs). This SDM estimator provides an approximately conditional estimate of the predictive uncertainty over instruction-following, conditional on multiple closed-weight LMs and the representation space of an open-weight model. While it would be more robust to use as input to the SDM estimator the hidden-states of the underlying models, this indirect, compositional proxy is more reliable than verbalized uncertainty and adds a means of auditing the predictions against data with known labels. We release the code as an MCP Server to simplify adding interpretability-by-exemplar and locally updatable, uncertainty-aware instruction-following to agent-based pipelines. We further release OpenVerification1, a balanced set of over two million examples of instruction-following and associated rationales from recent closed-weight LMs, for bootstrapping domain-specific estimators. Finally, we discuss limitations of estimating the predictive uncertainty without access to the hidden-states of the tool-calling LM and provide practical guidance for applications.},
booktitle = {Proceedings of the ACM Conference on AI and Agentic Systems},
pages = {1259–1269},
numpages = {11},
keywords = {Approximately conditional calibration, Interpretability-by-exemplar, Classification of instruction-following, Model ensembles},
location = {
},
series = {CAIS '26}
}
Footnotes
-
The le format de sortie a changé depuis la v1.0.0 utilisée dans la vidéo. Voir changelog.md. ↩