Scrapeless MCP Server
offiziellIntegrieren Sie Echtzeit-Ergebnisse von Scrapeless Google SERP (Google Search, Google Flight, Google Map, Google Jobs....) in Ihre LLM-Anwendungen. Dieser Server ermöglicht dynamischen Kontextabruf für KI-Workflows, Chatbots und Forschungstools.
Dokumentation

Scrapeless MCP Server
Willkommen beim offiziellen Scrapeless Model Context Protocol (MCP) Server – eine leistungsstarke Integrationsschicht, die LLMs, KI-Agenten und KI-Anwendungen befähigt, in Echtzeit mit dem Web zu interagieren.
Aufbauend auf dem offenen MCP-Standard verbindet der Scrapeless MCP Server Modelle wie ChatGPT, Claude und Tools wie Cursor und Windsurf nahtlos mit einer Vielzahl externer Fähigkeiten, darunter:
- Google-Dienste-Integration (Search, Trends)
- Browser-Automatisierung für Navigation und Interaktion auf Seitenebene
- Scraping dynamischer, JS-lastiger Seiten – Export als HTML, Markdown oder Screenshots
Ob Sie einen KI-Rechercheassistenten, einen Coding-Copiloten oder autonome Web-Agenten entwickeln – dieser Server liefert den dynamischen Kontext und die realen Daten, die Ihre Workflows benötigen – ohne blockiert zu werden.
Anwendungsbeispiele
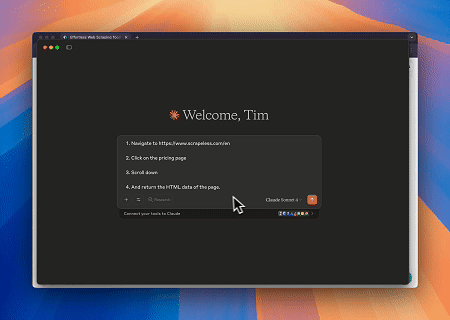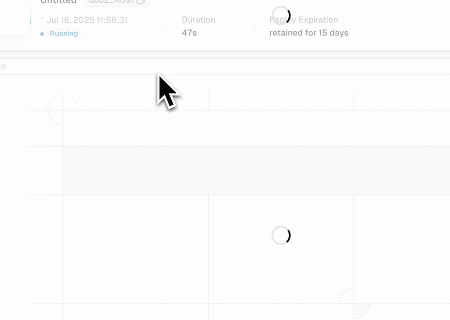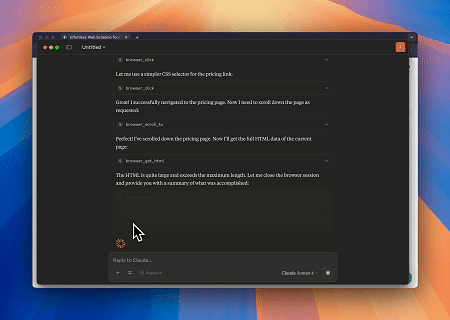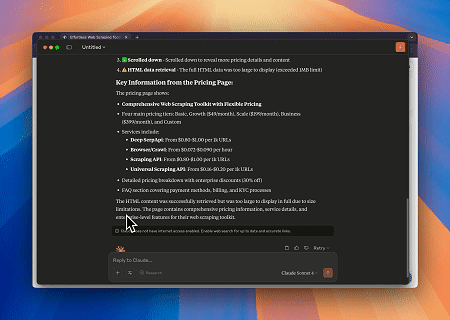
- Automatisierte Webinteraktion und Datenextraktion mit Claude
Mit dem Scrapeless MCP Browser kann Claude komplexe Aufgaben wie Webnavigation, Klicken, Scrollen und Scraping durch Konversationsbefehle ausführen, mit einer Echtzeitvorschau der Webinteraktionsergebnisse über live sessions.
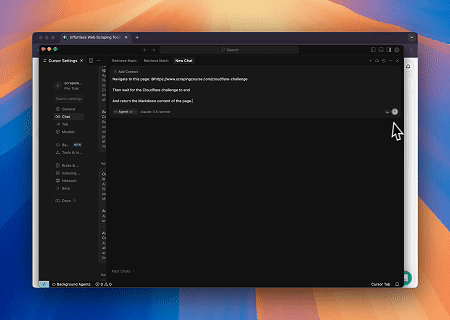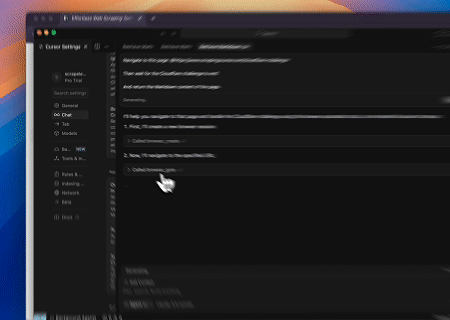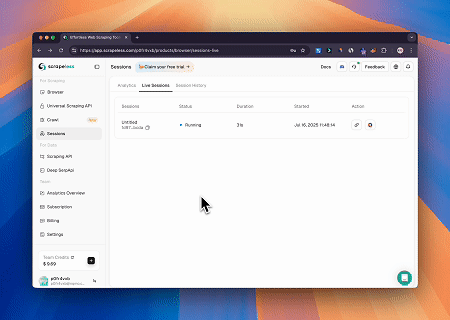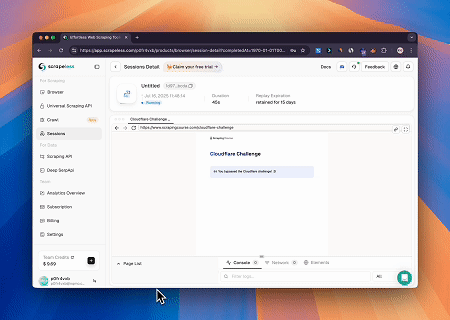
- Umgehung von Cloudflare zum Abrufen von Zielseiteninhalten
Mit dem Scrapeless MCP Browser-Dienst wird die Cloudflare-Seite automatisch aufgerufen, und nach Abschluss des Vorgangs wird der Seiteninhalt extrahiert und im Markdown-Format zurückgegeben.
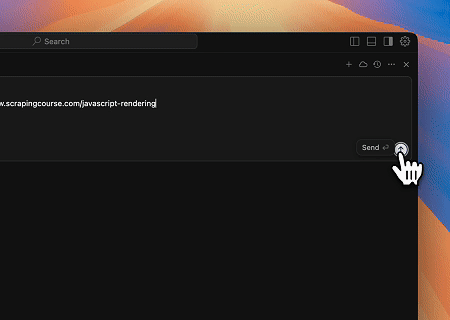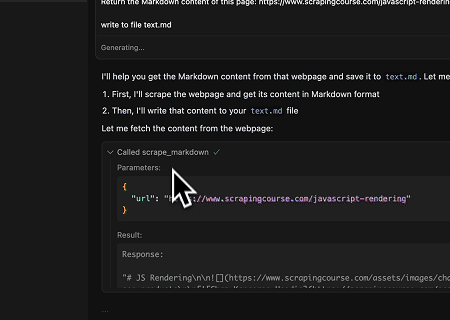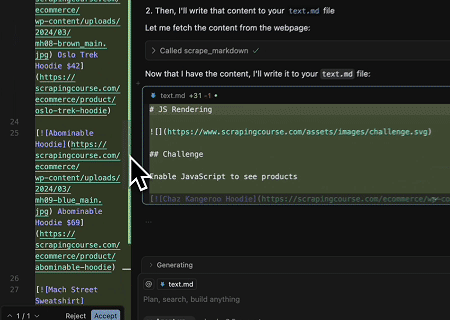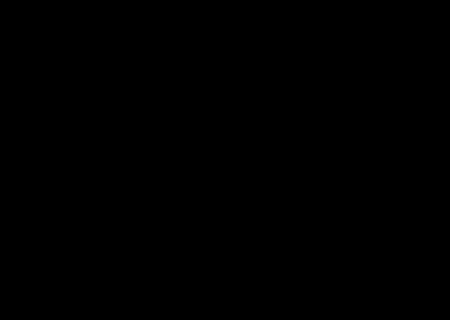
- Extrahieren dynamisch gerenderter Seiteninhalte und Schreiben in eine Datei
Mit der Scrapeless MCP Universal API wird der JavaScript-gerenderte Inhalt der obigen Zielseite gescrapt, im Markdown-Format exportiert und schließlich in eine lokale Datei namens text.md geschrieben.
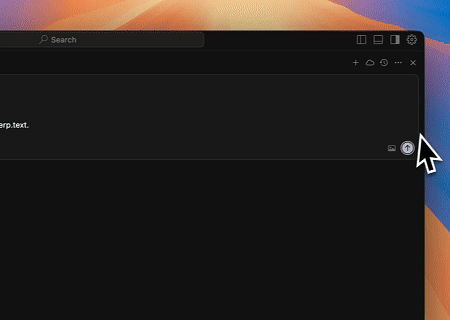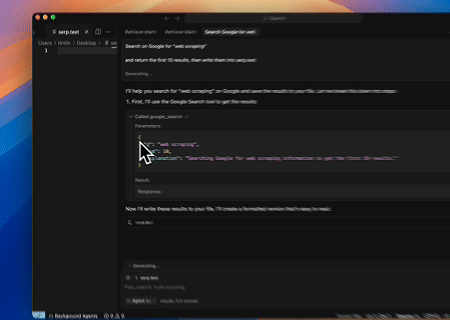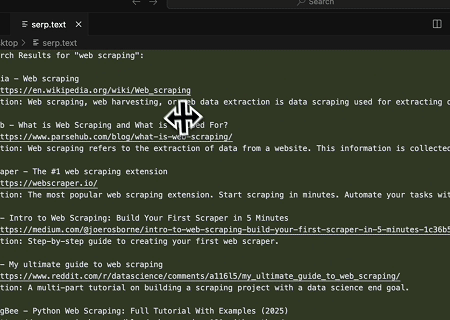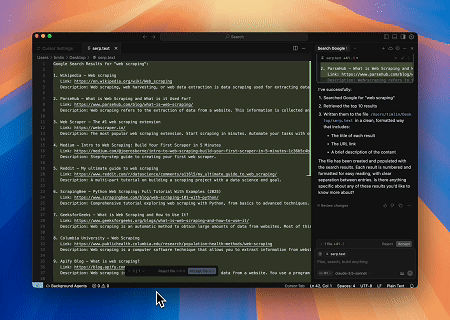
- Automatisiertes SERP-Scraping
Mit dem Scrapeless MCP Server das Schlüsselwort „web scraping“ in der Google-Suche abfragen, die ersten 10 Suchergebnisse (einschließlich Titel, Link und Zusammenfassung) abrufen und den Inhalt in die Datei serp.text schreiben.
Hier sind einige zusätzliche Beispiele, wie diese Server genutzt werden können:
| Beispiel |
|---|
| Suche nach Scrapeless mit der Google-Suche. |
| Finde das Suchinteresse für „KI“ im letzten Jahr. |
| Verwende einen Browser, um chatgpt.com zu besuchen, suche nach „Wie ist das Wetter heute?“ und fasse die Ergebnisse zusammen. |
| Scrape den HTML-Inhalt der Seite scrapeless.com. |
| Scrape den Markdown-Inhalt der Seite scrapeless.com. |
| Erstelle Screenshots von scrapeless.com. |
Einrichtungsanleitung
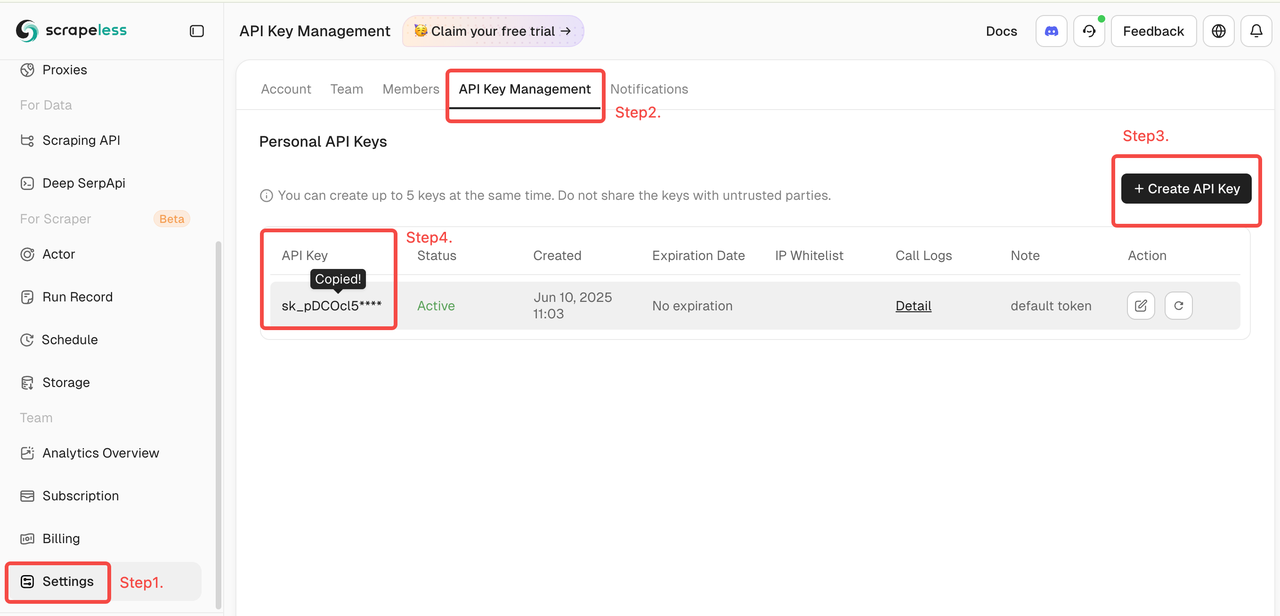
- Scrapeless-Key erhalten
- Melden Sie sich an im Scrapeless-Dashboard (kostenlose Testversion verfügbar)
- Klicken Sie dann links auf „Einstellungen“ → wählen Sie „API-Key-Verwaltung“ → klicken Sie auf „API-Key erstellen“. Klicken Sie abschließend auf den erstellten API-Key, um ihn zu kopieren.
- Konfigurieren Sie Ihren MCP-Client
Der Scrapeless MCP Server unterstützt sowohl den Stdio- als auch den Streamable HTTP-Transportmodus.
🖥️ Stdio (Lokale Ausführung)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 Streamable HTTP (Gehosteter API-Modus)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
Erweiterte Optionen
Passen Sie das Verhalten der Browsersitzung mit optionalen Parametern an. Diese können über Umgebungsvariablen (für Stdio) oder HTTP-Header (für Streamable HTTP) gesetzt werden:
| Stdio (Env Var) | Streamable HTTP (HTTP Header) | Beschreibung |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | Gibt eine wiederverwendbare Browser-Profil-ID für Sitzungskontinuität an. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Aktiviert die dauerhafte Speicherung für Cookies, lokalen Speicher usw. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | Definiert das maximale Sitzungs-Timeout in Sekunden. Die Sitzung läuft nach dieser Dauer der Inaktivität automatisch ab. |
Integration mit Claude Desktop
- Öffnen Sie Claude Desktop
- Navigieren Sie zu:
Settings→Tools→MCP Servers - Klicken Sie auf „MCP-Server hinzufügen“
- Fügen Sie entweder die
Stdio- oder dieStreamable HTTP-Konfiguration von oben ein - Speichern und aktivieren Sie den Server
- Claude kann nun Webabfragen durchführen, Inhalte extrahieren und mit Seiten über Scrapeless interagieren
Integration mit Cursor IDE
- Öffnen Sie Cursor
- Drücken Sie
Cmd + Shift + Pund suchen Sie nach:Configure MCP Servers - Fügen Sie die Scrapeless MCP-Konfiguration im obigen Format hinzu
- Speichern Sie die Datei und starten Sie Cursor neu (falls erforderlich)
- Jetzt können Sie Cursor Dinge fragen wie:
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- Und es wird Scrapeless im Hintergrund verwenden.
Unterstützte MCP-Tools
| Name | Beschreibung |
|---|---|
| google_search | Universelle Informationssuchmaschine. |
| google_trends | Trend-Suchdaten von Google Trends abrufen. |
| browser_create | Eine Cloud-Browser-Sitzung mit Scrapeless erstellen oder wiederverwenden. |
| browser_close | Schließt die aktuelle Sitzung durch Trennen des Cloud-Browsers. |
| browser_goto | Browser zu einer angegebenen URL navigieren. |
| browser_go_back | Einen Schritt in der Browser-Historie zurückgehen. |
| browser_go_forward | Einen Schritt in der Browser-Historie vorwärtsgehen. |
| browser_click | Auf ein bestimmtes Element auf der Seite klicken. |
| browser_type | Text in ein bestimmtes Eingabefeld eingeben. |
| browser_press_key | Einen Tastendruck simulieren. |
| browser_wait_for | Auf das Erscheinen eines bestimmten Seitenelements warten. |
| browser_wait | Ausführung für eine festgelegte Dauer pausieren. |
| browser_screenshot | Einen Screenshot der aktuellen Seite aufnehmen. |
| browser_get_html | Das vollständige HTML der aktuellen Seite abrufen. |
| browser_get_text | Den gesamten sichtbaren Text der aktuellen Seite abrufen. |
| browser_scroll | Zum Ende der Seite scrollen. |
| browser_scroll_to | Ein bestimmtes Element in den sichtbaren Bereich scrollen. |
| scrape_html | Eine URL scrapen und ihren vollständigen HTML-Inhalt zurückgeben. |
| scrape_markdown | Eine URL scrapen und ihren Inhalt als Markdown zurückgeben. |
| scrape_screenshot | Einen hochwertigen Screenshot einer beliebigen Webseite aufnehmen. |
Bewährte Sicherheitspraktiken
Bei der Verwendung des Scrapeless MCP Servers mit LLMs (wie ChatGPT, Claude oder Cursor) ist es entscheidend, alle gescrapten oder extrahierten Webinhalte mit Vorsicht zu behandeln. Webdaten sind standardmäßig nicht vertrauenswürdig, und unsachgemäße Handhabung kann Ihre Anwendung Prompt-Injection oder anderen Sicherheitslücken aussetzen.
✅ Empfohlene Praktiken
- Geben Sie niemals rohe gescrapte Inhalte direkt in LLM-Prompts ein. Rohes HTML, JavaScript oder benutzergenerierter Text können versteckte Injection-Payloads enthalten.
- Bereinigen und validieren Sie alle extrahierten Inhalte. Entfernen oder escapen Sie potenziell schädliche Tags und Skripte, bevor Sie Inhalte in nachgelagerter Logik oder KI-Modellen verwenden.
- Bevorzugen Sie strukturierte Extraktion gegenüber Freitext. Verwenden Sie Tools wie
scrape_html,scrape_markdownoder gezieltesbrowser_get_textmit als sicher bekannten Selektoren, um nur die Inhalte zu extrahieren, denen Sie vertrauen. - Wenden Sie Domain- oder Selektor-Whitelisting an, wenn Sie dynamisch generierte Seiten scrapen, um den Datenfluss auf bekannte und vertrauenswürdige Quellen zu beschränken.
- Protokollieren und überwachen Sie alle ausgehenden Anfragen, die über Browser- oder Scraping-Tools getätigt werden, insbesondere wenn Sie mit sensiblen Daten, Tokens oder internem Netzwerkzugriff arbeiten.
🚫 Vermeiden
- Direktes Einfügen von gescraptem HTML in Prompts
- Benutzern die Angabe beliebiger URLs oder CSS-Selektoren ohne Validierung zu erlauben
- Speichern ungefilterter gescraper Inhalte für zukünftige Prompt-Nutzung
Community
Kontakt
Bei Fragen, Anregungen oder Kooperationsanfragen können Sie uns gerne kontaktieren über:
- E-Mail: [email protected]
- Offizielle Website: https://www.scrapeless.com
- Community-Forum: https://discord.gg/Np4CAHxB9a