dbt MCP Server
offiziellOffizieller MCP-Server für dbt (data build tool) mit Integration in die dbt Core/Cloud CLI, Projektmetadaten-Erkennung, Modellinformationen und Abfragefunktionen für die semantische Schicht.
Dokumentation
dbt MCP Server
Dieser MCP-Server (Model Context Protocol) stellt verschiedene Werkzeuge zur Interaktion mit dbt bereit. Sie können diesen MCP-Server nutzen, um KI-Agenten Kontext zu Ihrem Projekt in dbt Core, dbt Fusion und dbt Platform zu geben.
Lesen Sie unsere Dokumentation hier, um mehr zu erfahren. Dieser Blogbeitrag bietet weitere Details zu den Möglichkeiten des dbt MCP-Servers.
Experimentelles MCP-Bundle
Wir veröffentlichen mit jedem Release ein experimentelles Model Context Protocol Bundle (dbt-mcp.mcpb), damit MCPB-fähige Clients diesen Server ohne zusätzliche Einrichtung importieren können. Laden Sie das Bundle aus den Assets des neuesten Releases herunter und folgen Sie der Anthropic mcpb CLI-Dokumentation, um es zu installieren oder zu inspizieren.
Feedback
Wenn Sie Anmerkungen oder Fragen haben, erstellen Sie ein GitHub Issue oder besuchen Sie uns im Community-Slack im Kanal #tools-dbt-mcp.
Architektur
Die Architektur des dbt MCP-Servers ermöglicht es Ihrem Agenten, sich mit einer Vielzahl von Werkzeugen zu verbinden.
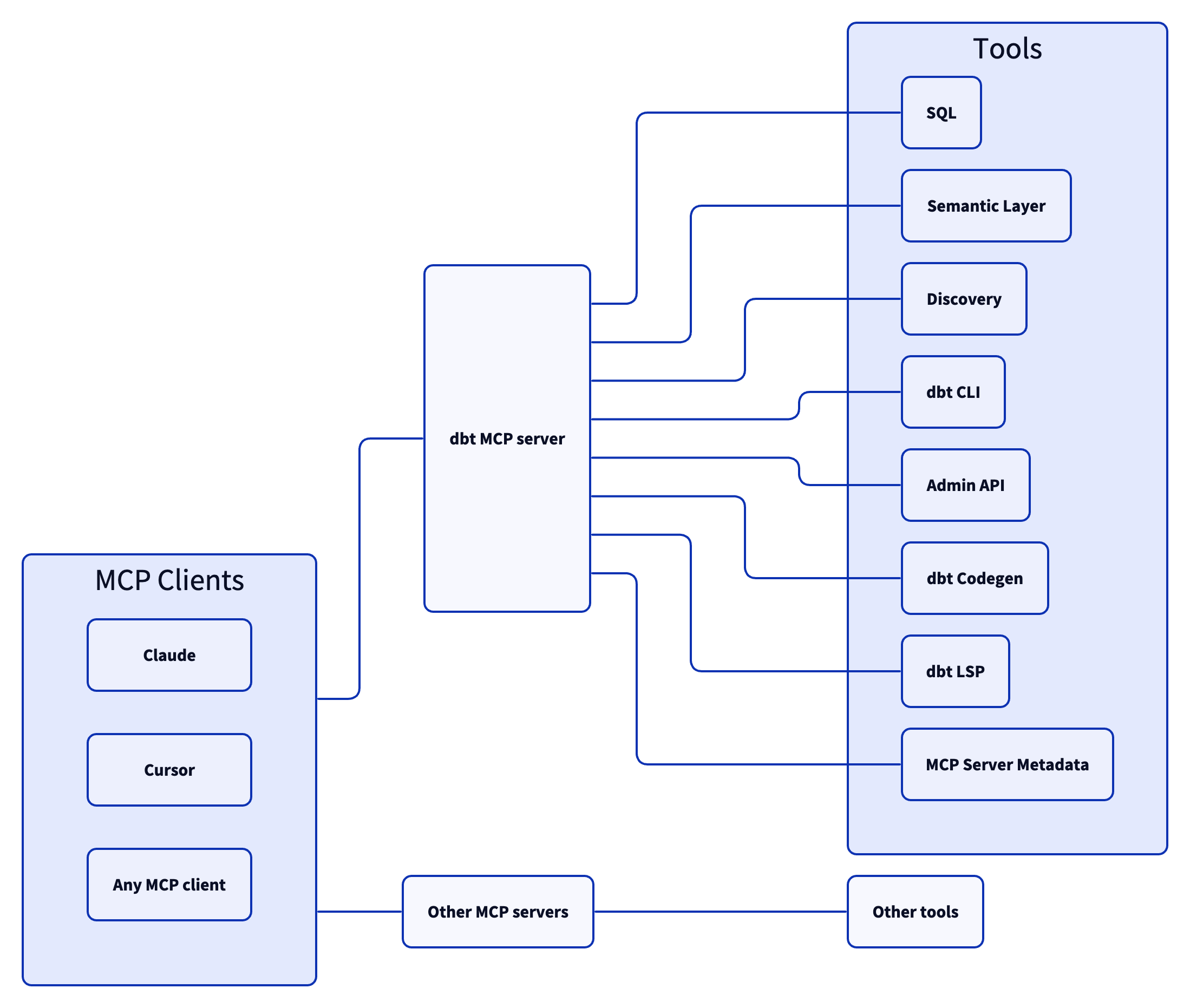
Werkzeuge
SQL
Werkzeuge zum Ausführen und Generieren von SQL auf der dbt Platform-Infrastruktur.
execute_sql: Führt SQL auf der dbt Platform-Infrastruktur mit Semantic-Layer-Unterstützung aus.text_to_sql: Generiert SQL aus natürlicher Sprache unter Verwendung des Projektkontexts.
Semantic Layer
Um mehr über den dbt Semantic Layer zu erfahren, klicken Sie hier.
get_dimension_values: Ruft eindeutige Werte für eine Dimension ab; optional auf bestimmte Metriken einschränkbar.get_dimensions: Ruft Dimensionen für angegebene Metriken ab.get_entities: Ruft Entitäten für angegebene Metriken ab.get_metrics_compiled_sql: Gibt kompiliertes SQL für Metriken zurück, ohne die Abfrage auszuführen.list_metrics: Ruft alle definierten Metriken ab.list_saved_queries: Ruft alle gespeicherten Abfragen ab.query_metrics: Führt Metrikabfragen mit Filter- und Gruppierungsoptionen aus.
Discovery
Um mehr über die dbt Discovery API zu erfahren, klicken Sie hier.
get_all_macros: Ruft Makros ab; optional nach Paket filtern oder nur Paketnamen zurückgeben.get_all_models: Ruft Name und Beschreibung aller Modelle ab.get_all_sources: Ruft alle Quellen mit Aktualitätsstatus ab; optional nach Quellname filtern.get_exposure_details: Ruft Exposure-Details ab, einschließlich Besitzer, Eltern und Aktualitätsstatus.get_exposures: Ruft alle Exposures ab (nachgelagerte Dashboards, Apps oder Analysen).get_lineage: Ruft den vollständigen Abstammungsgraphen (Vorfahren und Nachkommen) mit Typ- und Tiefenfilterung ab.get_macro_details: Ruft Details zu einem bestimmten Makro ab.get_mart_models: Ruft alle Mart-Modelle ab.get_model_children: Ruft nachgelagerte Abhängigkeiten eines Modells ab.get_model_details: Ruft Modelldetails ab, einschließlich kompiliertem SQL, Spalten und Schema.get_model_health: Ruft Gesundheitssignale ab: Ausführungsstatus, Testergebnisse und Aktualität vorgelagerter Quellen.get_model_parents: Ruft vorgelagerte Abhängigkeiten eines Modells ab.get_model_performance: Ruft den Ausführungsverlauf eines Modells ab; optional mit Testergebnissen.get_related_models: Findet ähnliche Modelle mittels semantischer Suche.get_seed_details: Ruft Details zu einem bestimmten Seed ab.get_semantic_model_details: Ruft Details zu einem bestimmten semantischen Modell ab.get_snapshot_details: Ruft Details zu einem bestimmten Snapshot ab.get_source_details: Ruft Quelldetails ab, einschließlich Spalten und Aktualität.get_test_details: Ruft Details zu einem bestimmten Test ab.search: [Alpha] Durchsucht Ressourcen im gesamten dbt-Projekt (nicht allgemein verfügbar).
dbt CLI
Wenn Sie Ihrem Client erlauben, dbt-Befehle über die MCP-Werkzeuge zu nutzen, könnte dies Ihre Datenmodelle, Quellen und Warehouse-Objekte verändern. Fahren Sie nur fort, wenn Sie dem Client vertrauen und die potenziellen Auswirkungen verstehen.
build: Führt Modelle, Tests, Snapshots und Seeds in DAG-Reihenfolge aus.clone: Klont ausgewählte Knoten vom angegebenen Zustand in die Zielschema(s).compile: Generiert ausführbares SQL aus Modellen/Tests/Analysen; nützlich zur Validierung von Jinja-Logik.docs: Generiert Dokumentation für das dbt-Projekt.get_lineage_dev: Ruft die Abstammung aus der lokalen manifest.json mit Typ- und Tiefenfilterung ab.get_node_details_dev: Ruft Knotendetails aus der lokalen manifest.json ab (Modelle, Seeds, Snapshots, Quellen).list: Listet Ressourcen im dbt-Projekt nach Typ mit Selektorunterstützung auf.parse: Analysiert und validiert Projektdateien auf syntaktische Korrektheit.run: Führt Modelle aus, um sie in der Datenbank zu materialisieren.show: Führt SQL gegen die Datenbank aus und gibt Ergebnisse zurück.test: Führt Tests aus, um Daten- und Modellintegrität zu validieren.
Admin API
Um mehr über die dbt Administrative API zu erfahren, klicken Sie hier.
cancel_job_run: Bricht einen laufenden Job ab.get_job_details: Ruft die Jobkonfiguration ab, einschließlich Triggern, Zeitplan und dbt-Befehlen.get_job_run_details: Ruft Ausführungsdetails ab, einschließlich Status, Zeitplan, Schritte und Artefakte.get_job_run_error: Ruft Fehler- und/oder Warndetails für eine Jobausführung ab; optional nur Warnungen anzeigen oder einschließen.list_job_run_artifacts: Listet verfügbare Artefakte einer Jobausführung auf.list_jobs: Listet Jobs in einem dbt Platform-Konto auf; optional nach Projekt oder Umgebung filtern.list_jobs_runs: Listet Jobausführungen auf; optional nach Job, Status oder Sortierfeld filtern.list_projects: Listet alle Projekte im dbt Platform-Konto auf.retry_job_run: Wiederholt eine fehlgeschlagene Jobausführung.trigger_job_run: Löst eine Jobausführung aus; optional Git-Branch, Schema oder andere Einstellungen überschreiben.
dbt Codegen
Diese Werkzeuge helfen, die Generierung von Boilerplate-Code für dbt-Projektdateien zu automatisieren.
generate_model_yaml: Generiert Modell-YAML mit Spalten; optional vorgelagerte Beschreibungen übernehmen.generate_source: Generiert Quell-YAML durch Introspektion von Datenbankschemata; optional Spalten einschließen.generate_staging_model: Generiert Staging-Modell-SQL aus einer Quelltabelle.
dbt LSP
Eine Reihe von Werkzeugen, die die Fusion-Engine für fortgeschrittene SQL-Kompilierung und spaltenbezogene Abstammungsanalyse nutzen.
fusion.compile_sql: Kompiliert SQL im Projektkontext über dbt Platform.fusion.get_column_lineage: Verfolgt die spaltenbezogene Abstammung über dbt Platform.get_column_lineage: Verfolgt die spaltenbezogene Abstammung lokal (erfordert dbt-lsp über dbt Labs VSCE).
Produktdokumentation
Werkzeuge zum Suchen und Abrufen von Inhalten aus der offiziellen dbt-Dokumentation unter docs.getdbt.com.
get_product_doc_pages: Ruft den vollständigen Markdown-Inhalt einer oder mehrerer docs.getdbt.com-Seiten nach Pfad oder URL ab.search_product_docs: Durchsucht docs.getdbt.com nach Seiten, die einer Suchanfrage entsprechen; gibt Titel, URLs und Beschreibungen nach Relevanz sortiert zurück. Verwenden Sie get_product_doc_pages, um den vollständigen Inhalt abzurufen.
MCP-Server-Metadaten
Diese Werkzeuge liefern Informationen über den MCP-Server selbst.
get_mcp_server_branch: Gibt den aktuellen Git-Branch des laufenden dbt MCP-Servers zurück.get_mcp_server_version: Gibt die aktuelle Version des dbt MCP-Servers zurück.
Beispiele
Häufig verbinden Sie den dbt MCP-Server mit einem Agentenprodukt wie Claude oder Cursor. Wenn Sie jedoch Ihren eigenen Agenten erstellen möchten, sehen Sie sich das Beispielverzeichnis an, um zu erfahren, wie Sie beginnen können.
Abhängigkeiten
Abhängigkeiten sind an bestimmte Versionen gebunden und werden nicht automatisch aktualisiert. Nur sicherheitsrelevante Abhängigkeitsaktualisierungen werden über automatisierte Pull Requests eingereicht.
Mitwirken
Lesen Sie CONTRIBUTING.md für Anweisungen, wie Sie sich beteiligen können!