Scrapeless MCP Server
官方將即時 Scrapeless Google SERP(Google 搜尋、Google 航班、Google 地圖、Google 職缺等)結果整合至您的 LLM 應用程式中。此伺服器可為 AI 工作流程、聊天機器人及研究工具提供動態上下文檢索功能。
文件

Scrapeless MCP 伺服器
歡迎使用官方 Scrapeless 模型上下文協定 (MCP) 伺服器 — 這是一個強大的整合層,讓 LLM、AI 代理和 AI 應用程式能夠即時與網路互動。
Scrapeless MCP 伺服器建立在開放的 MCP 標準之上,能將 ChatGPT、Claude 等模型,以及 Cursor 和 Windsurf 等工具,無縫連接到廣泛的外部功能,包括:
- Google 服務整合(搜尋、趨勢)
- 瀏覽器自動化,用於頁面層級的導覽和互動
- 擷取動態、大量使用 JS 的網站——匯出為 HTML、Markdown 或螢幕截圖
無論您正在建立 AI 研究助理、程式碼輔助工具,還是自主網路代理,此伺服器都能提供您工作流程所需的動態上下文和真實世界資料——而且不會被封鎖。
使用範例
- 使用 Claude 進行自動化網路互動和資料提取
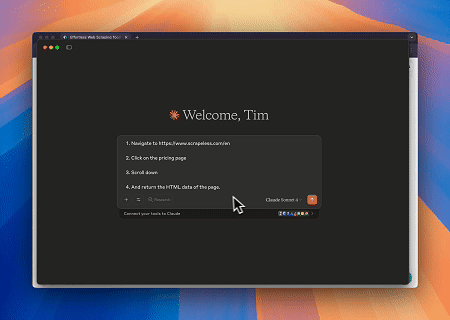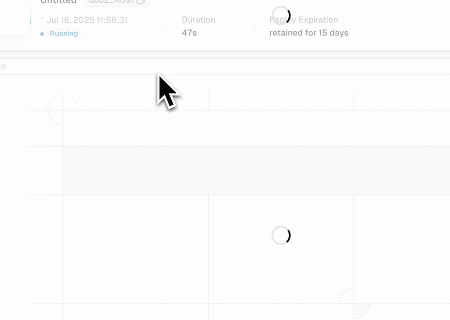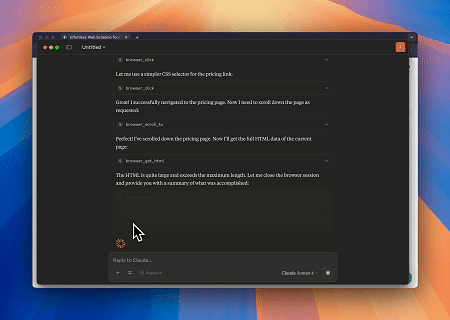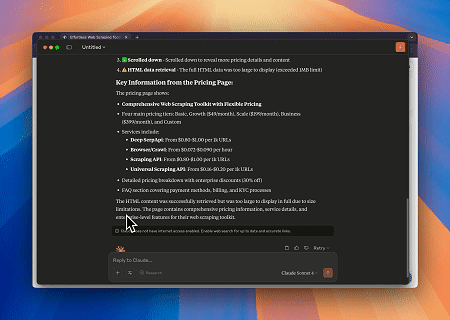
透過 Scrapeless MCP 瀏覽器,Claude 可以執行複雜的任務,例如透過對話指令進行網頁導覽、點擊、捲動和擷取,並透過 live sessions 即時預覽網路互動結果。
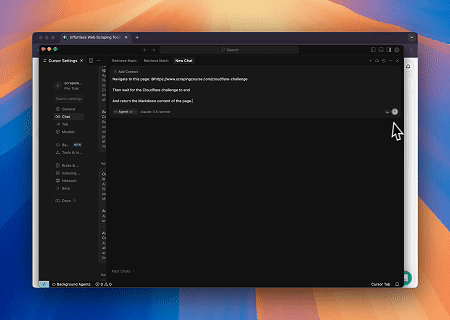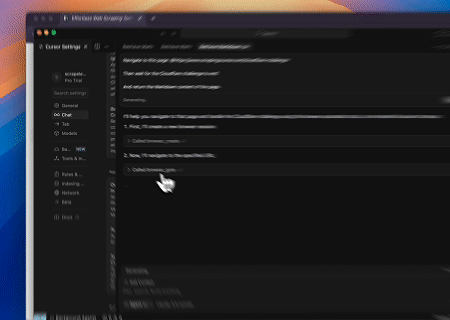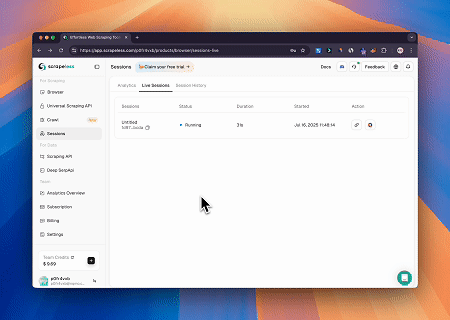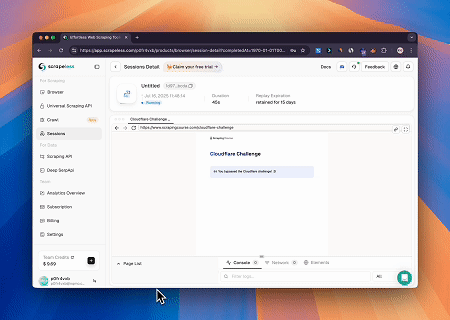
- 繞過 Cloudflare 以擷取目標頁面內容
使用 Scrapeless MCP 瀏覽器服務,自動存取 Cloudflare 頁面,並在流程完成後,提取頁面內容並以 Markdown 格式回傳。
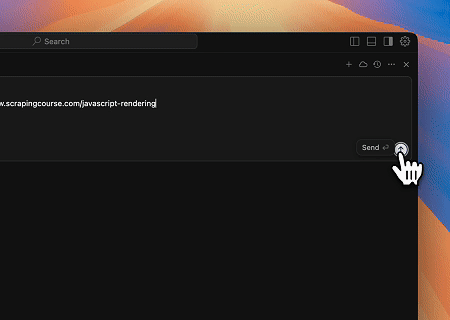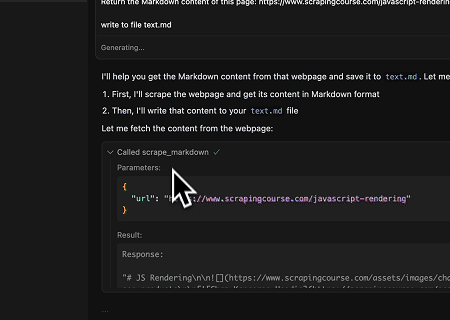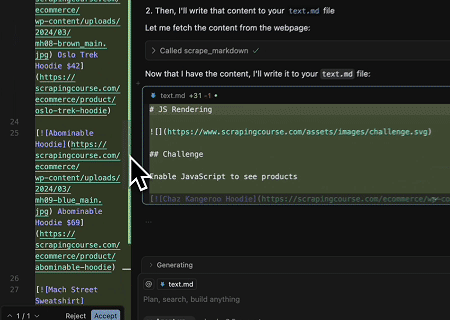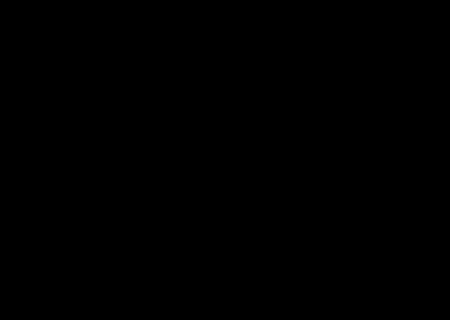
- 提取動態渲染的頁面內容並寫入檔案
使用 Scrapeless MCP 通用 API,擷取上述目標頁面中由 JavaScript 渲染的內容,以 Markdown 格式匯出,最後寫入名為 text.md 的本機檔案。
- 自動化 SERP 擷取
使用 Scrapeless MCP 伺服器,在 Google 搜尋中查詢關鍵字「web scraping」,擷取前 10 筆搜尋結果(包含標題、連結和摘要),並將內容寫入名為 serp.text 的檔案。
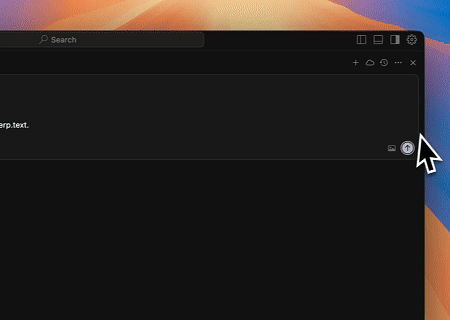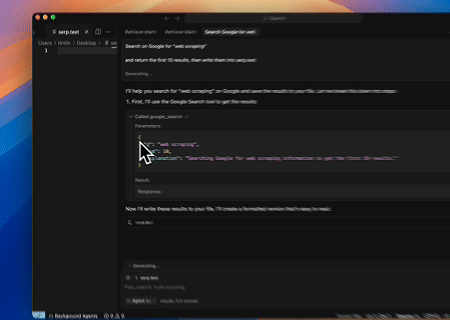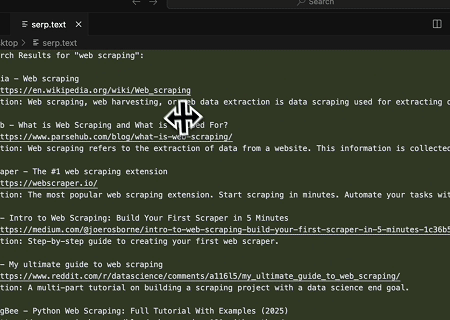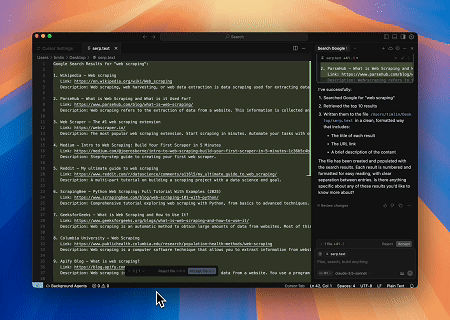
以下是一些如何使用這些伺服器的額外範例:
| 範例 |
|---|
| 透過 Google 搜尋 scrapeless。 |
| 尋找過去一年「AI」的搜尋熱度。 |
| 使用瀏覽器造訪 chatgpt.com,搜尋「今天天氣如何?」,並總結結果。 |
| 擷取 scrapeless.com 頁面的 HTML 內容。 |
| 擷取 scrapeless.com 頁面的 Markdown 內容。 |
| 取得 scrapeless.com 的螢幕截圖。 |
設定指南
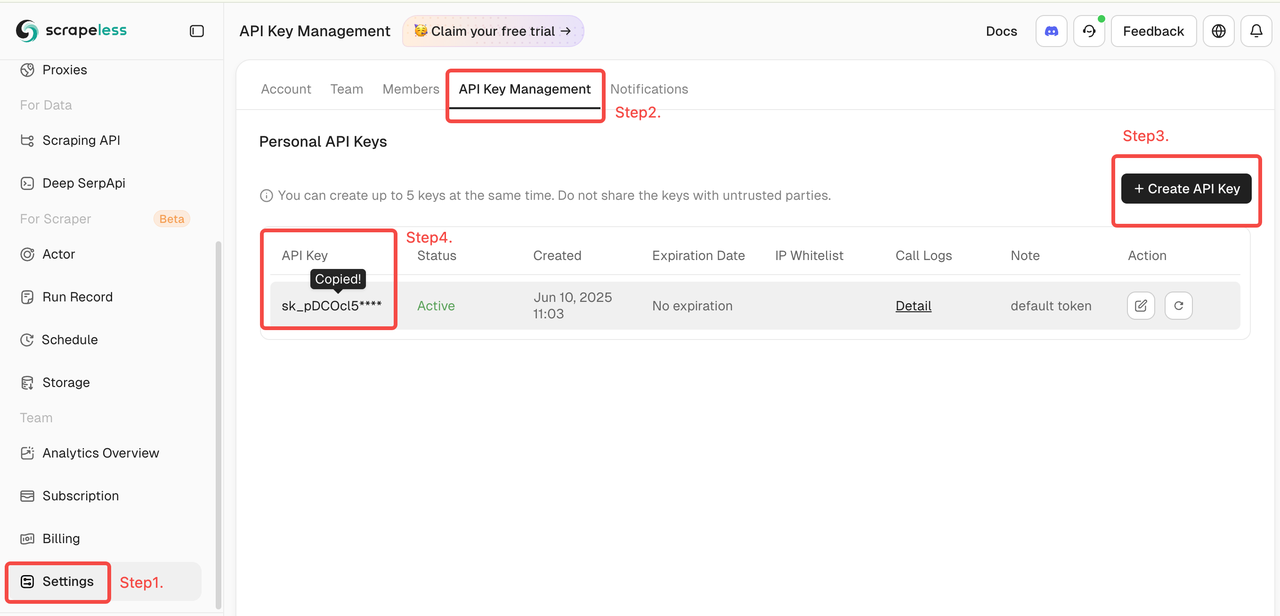
- 取得 Scrapeless 金鑰
- 登入 Scrapeless 儀表板(提供免費試用)
- 然後點擊左側的「設定」-> 選擇「API 金鑰管理」-> 點擊「建立 API 金鑰」。最後,點擊您建立的 API 金鑰以複製它。
- 設定您的 MCP 客戶端
Scrapeless MCP 伺服器支援 Stdio 和 Streamable HTTP 兩種傳輸模式。
🖥️ Stdio(本機執行)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 Streamable HTTP(託管 API 模式)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
進階選項
使用可選參數自訂瀏覽器工作階段行為。這些可以透過環境變數(用於 Stdio)或 HTTP 標頭(用於 Streamable HTTP)設定:
| Stdio(環境變數) | Streamable HTTP(HTTP 標頭) | 說明 |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | 指定可重複使用的瀏覽器設定檔 ID,以維持工作階段連續性。 |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | 為 cookie、localStorage 等啟用持久性儲存。 |
| BROWSER_SESSION_TTL | x-browser-session-ttl | 定義最大工作階段逾時時間(以秒為單位)。在此非活動持續時間後,工作階段將自動過期。 |
與 Claude Desktop 整合
- 開啟 Claude Desktop
- 導覽至:
Settings→Tools→MCP Servers - 點擊「新增 MCP 伺服器」
- 貼上上述的
Stdio或Streamable HTTP設定 - 儲存並啟用伺服器
- Claude 現在將能夠使用 Scrapeless 發出網路查詢、提取內容並與頁面互動
與 Cursor IDE 整合
- 開啟 Cursor
- 按下
Cmd + Shift + P並搜尋:Configure MCP Servers - 使用上述格式新增 Scrapeless MCP 設定
- 儲存檔案並重新啟動 Cursor(如有需要)
- 現在您可以向 Cursor 詢問類似以下的內容:
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- 它將在背景使用 Scrapeless。
支援的 MCP 工具
| 名稱 | 說明 |
|---|---|
| google_search | 通用資訊搜尋引擎。 |
| google_trends | 從 Google Trends 取得熱門搜尋資料。 |
| browser_create | 使用 Scrapeless 建立或重複使用雲端瀏覽器工作階段。 |
| browser_close | 透過中斷雲端瀏覽器連線來關閉目前工作階段。 |
| browser_goto | 將瀏覽器導覽至指定的 URL。 |
| browser_go_back | 在瀏覽器歷程記錄中後退一步。 |
| browser_go_forward | 在瀏覽器歷程記錄中前進一步。 |
| browser_click | 點擊頁面上的特定元素。 |
| browser_type | 在指定的輸入欄位中輸入文字。 |
| browser_press_key | 模擬按鍵按下。 |
| browser_wait_for | 等待特定頁面元素出現。 |
| browser_wait | 暫停執行一段固定時間。 |
| browser_screenshot | 擷取目前頁面的螢幕截圖。 |
| browser_get_html | 取得目前頁面的完整 HTML。 |
| browser_get_text | 從目前頁面取得所有可見文字。 |
| browser_scroll | 捲動到頁面底部。 |
| browser_scroll_to | 將特定元素捲動到可視範圍內。 |
| scrape_html | 擷取 URL 並回傳其完整 HTML 內容。 |
| scrape_markdown | 擷取 URL 並將其內容回傳為 Markdown。 |
| scrape_screenshot | 擷取任何網頁的高品質螢幕截圖。 |
安全性最佳實務
將 Scrapeless MCP 伺服器與 LLM(如 ChatGPT、Claude 或 Cursor)搭配使用時,務必謹慎處理所有擷取或提取的網頁內容。網頁資料預設為不可信任,不當處理可能會使您的應用程式暴露於提示注入或其他安全漏洞的風險中。
✅ 建議做法
- 切勿將原始擷取內容直接傳遞到 LLM 提示中。 原始 HTML、JavaScript 或使用者產生的文字可能包含隱藏的注入酬載。
- 消毒並驗證所有提取的內容。 在下游邏輯或 AI 模型中使用內容之前,先移除或轉義潛在有害的標籤和腳本。
- 優先使用結構化提取,而非自由格式文字。 使用如
scrape_html、scrape_markdown或具有已知安全選擇器的目標browser_get_text等工具,僅提取您信任的內容。 - 在擷取動態產生的頁面時,套用網域或選擇器白名單,以將資料流限制在已知且信任的來源。
- 記錄並監控所有透過瀏覽器或擷取工具發出的傳出請求,尤其是在處理敏感資料、權杖或內部網路存取時。
🚫 避免
- 將擷取的 HTML 直接注入提示中
- 讓使用者在未經驗證的情況下指定任意 URL 或 CSS 選擇器
- 儲存未過濾的擷取內容以供未來提示使用
社群
聯絡我們
如有任何問題、建議或合作查詢,歡迎透過以下方式與我們聯繫: