Scrapeless MCP Server
chính thứcTích hợp kết quả Scrapeless Google SERP thời gian thực (Google Search, Google Flight, Google Map, Google Jobs...) vào các ứng dụng LLM của bạn. Máy chủ này cho phép truy xuất ngữ cảnh động cho các quy trình AI, chatbot và công cụ nghiên cứu.
Tài liệu

Máy chủ Scrapeless MCP
Chào mừng bạn đến với Máy chủ Giao thức Ngữ cảnh Mô hình (MCP) chính thức của Scrapeless — một lớp tích hợp mạnh mẽ trao quyền cho các LLM, Tác nhân AI và ứng dụng AI tương tác với web theo thời gian thực.
Được xây dựng trên tiêu chuẩn MCP mở, Máy chủ Scrapeless MCP kết nối liền mạch các mô hình như ChatGPT, Claude và các công cụ như Cursor và Windsurf với nhiều khả năng bên ngoài, bao gồm:
- Tích hợp dịch vụ Google (Tìm kiếm, Xu hướng)
- Tự động hóa trình duyệt để điều hướng và tương tác ở cấp độ trang
- Thu thập các trang web động, nhiều JavaScript—xuất dưới dạng HTML, Markdown hoặc ảnh chụp màn hình
Cho dù bạn đang xây dựng trợ lý nghiên cứu AI, trợ lý lập trình hay tác nhân web tự động, máy chủ này cung cấp ngữ cảnh động và dữ liệu thế giới thực mà quy trình làm việc của bạn cần—mà không bị chặn.
Ví dụ sử dụng
- Tương tác Web Tự động và Trích xuất Dữ liệu với Claude
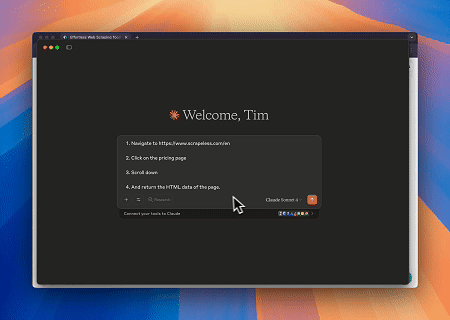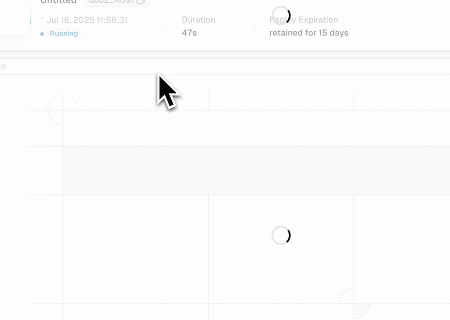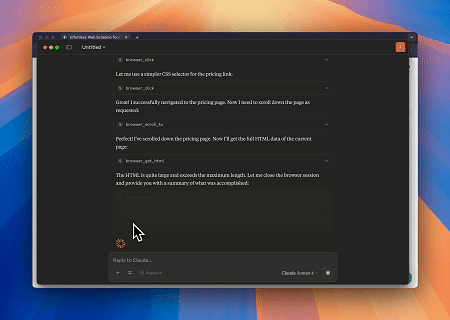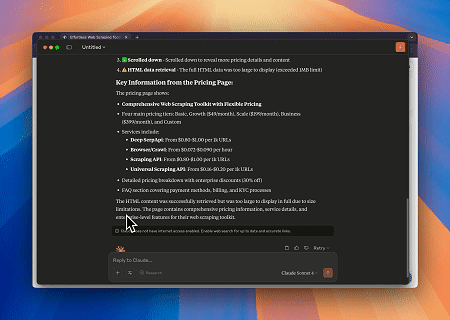
Sử dụng Trình duyệt Scrapeless MCP, Claude có thể thực hiện các tác vụ phức tạp như điều hướng web, nhấp chuột, cuộn trang và thu thập dữ liệu thông qua các lệnh hội thoại, với bản xem trước thời gian thực kết quả tương tác web qua live sessions.
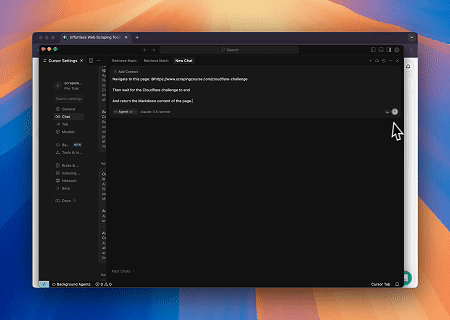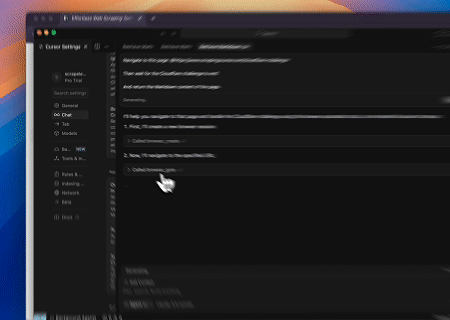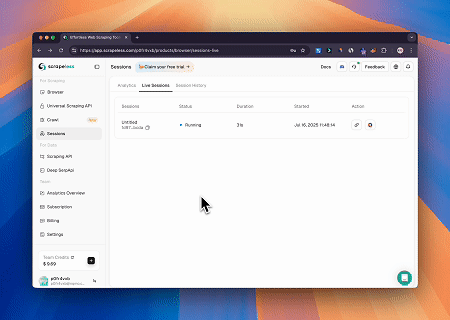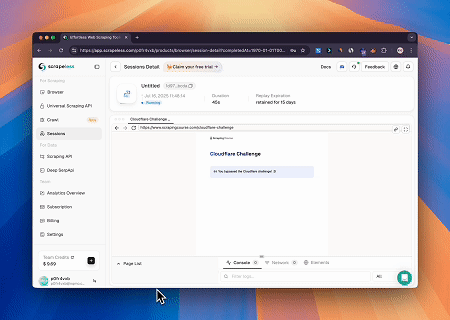
- Vượt qua Cloudflare để Truy xuất Nội dung Trang Mục tiêu
Sử dụng dịch vụ Trình duyệt Scrapeless MCP, trang Cloudflare được tự động truy cập và sau khi quá trình hoàn tất, nội dung trang được trích xuất và trả về ở định dạng Markdown.
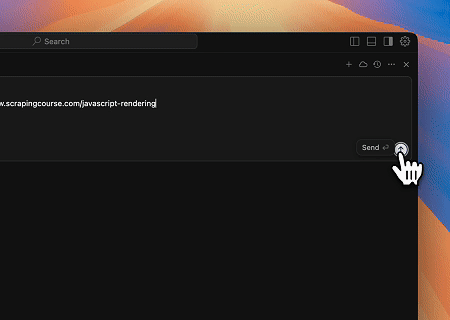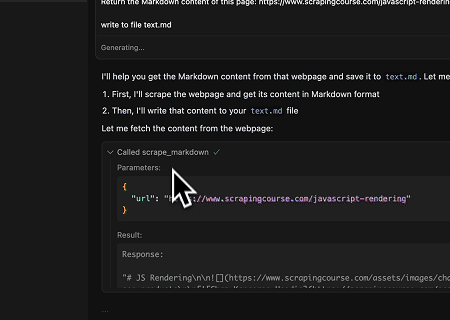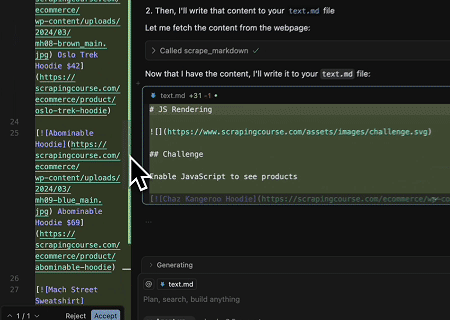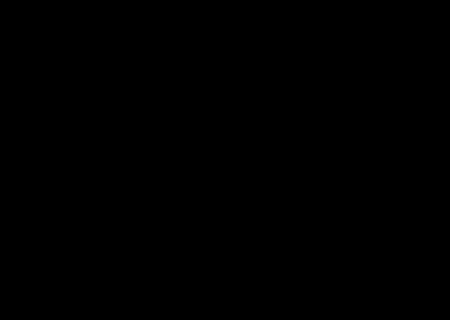
- Trích xuất Nội dung Trang Được Kết xuất Động và Ghi vào Tệp
Sử dụng API Chung Scrapeless MCP, nội dung được kết xuất bằng JavaScript của trang mục tiêu ở trên được thu thập, xuất ở định dạng Markdown và cuối cùng được ghi vào tệp cục bộ có tên text.md.
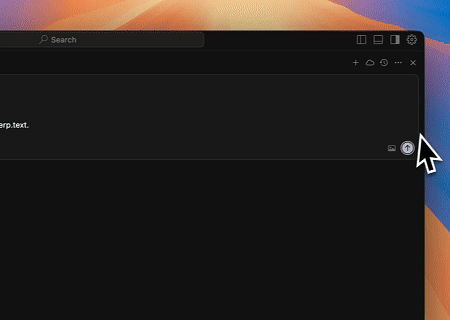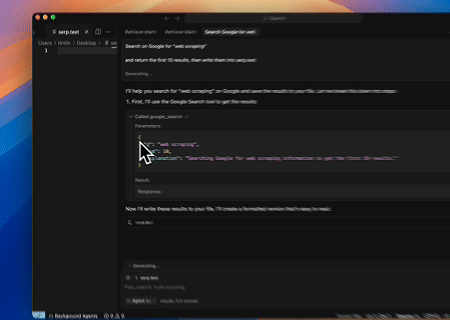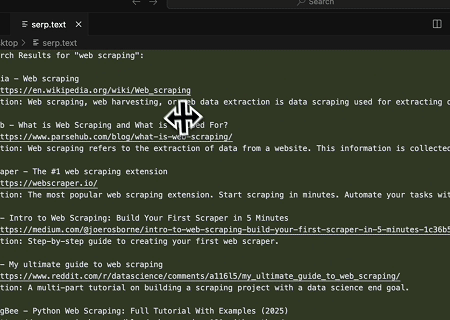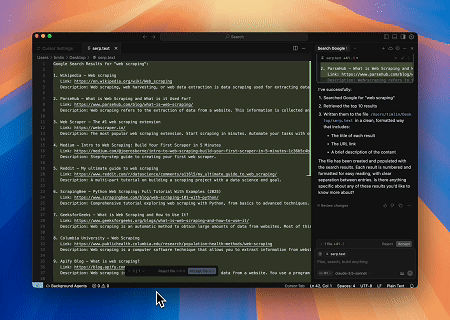
- Thu thập SERP Tự động
Sử dụng Máy chủ Scrapeless MCP, truy vấn từ khóa “web scraping” trên Google Tìm kiếm, truy xuất 10 kết quả tìm kiếm đầu tiên (bao gồm tiêu đề, liên kết và tóm tắt) và ghi nội dung vào tệp có tên serp.text.
Dưới đây là một số ví dụ bổ sung về cách sử dụng các máy chủ này:
| Ví dụ |
|---|
| Tìm kiếm scrapeless bằng Google tìm kiếm. |
| Tìm mức độ quan tâm tìm kiếm cho "AI" trong năm qua. |
| Sử dụng trình duyệt để truy cập chatgpt.com, tìm kiếm "Thời tiết hôm nay thế nào?" và tóm tắt kết quả. |
| Thu thập nội dung HTML của trang scrapeless.com. |
| Thu thập nội dung Markdown của trang scrapeless.com. |
| Chụp ảnh màn hình của scrapeless.com. |
Hướng dẫn Thiết lập
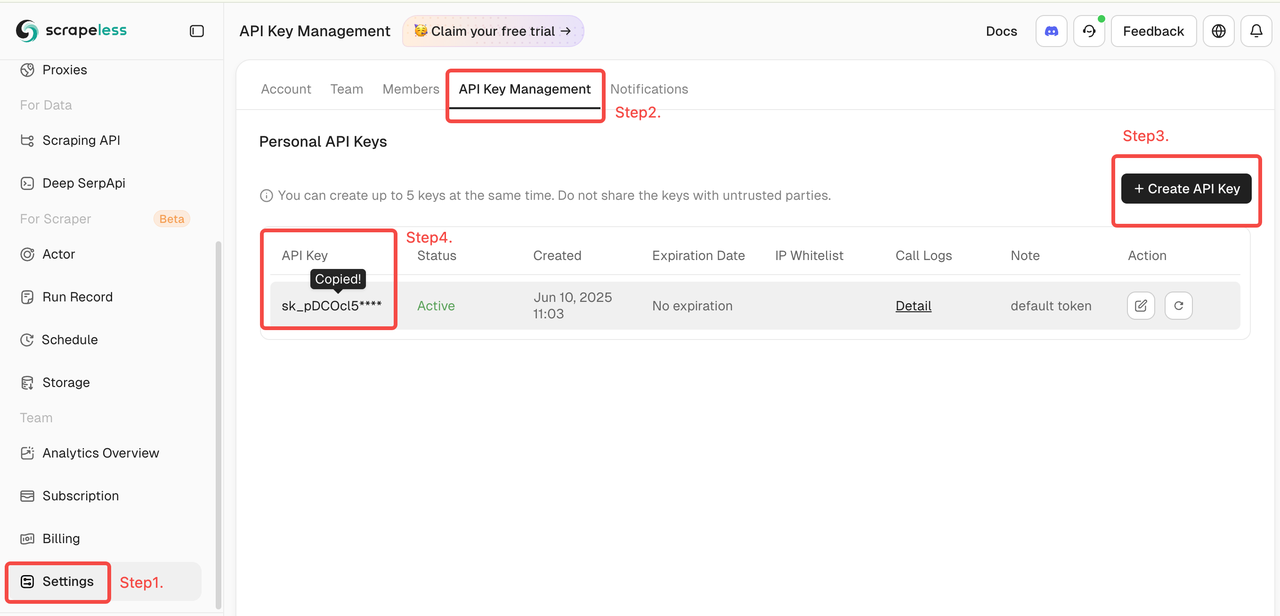
- Lấy Khóa Scrapeless
- Đăng nhập vào Bảng điều khiển Scrapeless (Có bản dùng thử miễn phí)
- Sau đó nhấp "Cài đặt" ở bên trái -> chọn "Quản lý Khóa API" -> nhấp "Tạo Khóa API". Cuối cùng, nhấp vào Khóa API bạn đã tạo để sao chép nó.
- Cấu hình Máy khách MCP của Bạn
Máy chủ Scrapeless MCP hỗ trợ cả hai chế độ truyền tải Stdio và HTTP Có thể Truyền phát.
🖥️ Stdio (Thực thi Cục bộ)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 HTTP Có thể Truyền phát (Chế độ API Lưu trữ)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
Tùy chọn Nâng cao
Tùy chỉnh hành vi phiên trình duyệt với các tham số tùy chọn. Chúng có thể được đặt qua biến môi trường (cho Stdio) hoặc tiêu đề HTTP (cho HTTP Có thể Truyền phát):
| Stdio (Biến Môi trường) | HTTP Có thể Truyền phát (Tiêu đề HTTP) | Mô tả |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | Chỉ định ID hồ sơ trình duyệt có thể tái sử dụng để duy trì phiên liên tục. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Bật lưu trữ liên tục cho cookie, bộ nhớ cục bộ, v.v. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | Xác định thời gian chờ phiên tối đa tính bằng giây. Phiên sẽ tự động hết hạn sau khoảng thời gian không hoạt động này. |
Tích hợp với Claude Desktop
- Mở Claude Desktop
- Điều hướng đến:
Settings→Tools→MCP Servers - Nhấp "Thêm Máy chủ MCP"
- Dán cấu hình
StdiohoặcStreamable HTTPở trên - Lưu và kích hoạt máy chủ
- Claude giờ đây sẽ có thể đưa ra truy vấn web, trích xuất nội dung và tương tác với các trang bằng Scrapeless
Tích hợp với Cursor IDE
- Mở Cursor
- Nhấn
Cmd + Shift + Pvà tìm kiếm:Configure MCP Servers - Thêm cấu hình Scrapeless MCP bằng định dạng ở trên
- Lưu tệp và khởi động lại Cursor (nếu cần)
- Bây giờ bạn có thể hỏi Cursor những điều như:
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- Và nó sẽ sử dụng Scrapeless ở chế độ nền.
Công cụ MCP được Hỗ trợ
| Tên | Mô tả |
|---|---|
| google_search | Công cụ tìm kiếm thông tin chung. |
| google_trends | Lấy dữ liệu tìm kiếm thịnh hành từ Google Xu hướng. |
| browser_create | Tạo hoặc tái sử dụng phiên trình duyệt đám mây bằng Scrapeless. |
| browser_close | Đóng phiên hiện tại bằng cách ngắt kết nối trình duyệt đám mây. |
| browser_goto | Điều hướng trình duyệt đến một URL được chỉ định. |
| browser_go_back | Quay lại một bước trong lịch sử trình duyệt. |
| browser_go_forward | Tiến lên một bước trong lịch sử trình duyệt. |
| browser_click | Nhấp vào một phần tử cụ thể trên trang. |
| browser_type | Nhập văn bản vào trường nhập liệu được chỉ định. |
| browser_press_key | Mô phỏng một lần nhấn phím. |
| browser_wait_for | Chờ một phần tử trang cụ thể xuất hiện. |
| browser_wait | Tạm dừng thực thi trong một khoảng thời gian cố định. |
| browser_screenshot | Chụp ảnh màn hình của trang hiện tại. |
| browser_get_html | Lấy toàn bộ HTML của trang hiện tại. |
| browser_get_text | Lấy tất cả văn bản hiển thị từ trang hiện tại. |
| browser_scroll | Cuộn xuống cuối trang. |
| browser_scroll_to | Cuộn một phần tử cụ thể vào tầm nhìn. |
| scrape_html | Thu thập một URL và trả về toàn bộ nội dung HTML của nó. |
| scrape_markdown | Thu thập một URL và trả về nội dung của nó dưới dạng Markdown. |
| scrape_screenshot | Chụp ảnh màn hình chất lượng cao của bất kỳ trang web nào. |
Thực hành Bảo mật Tốt nhất
Khi sử dụng Máy chủ Scrapeless MCP với các LLM (như ChatGPT, Claude hoặc Cursor), điều quan trọng là phải xử lý cẩn thận tất cả nội dung web được thu thập hoặc trích xuất. Dữ liệu web mặc định là không đáng tin cậy và việc xử lý không đúng cách có thể khiến ứng dụng của bạn gặp phải lỗ hổng chèn lệnh hoặc các lỗ hổng bảo mật khác.
✅ Thực hành được Khuyến nghị
- Không bao giờ truyền trực tiếp nội dung thu thập thô vào lời nhắc LLM. HTML, JavaScript thô hoặc văn bản do người dùng tạo có thể chứa các tải trọng chèn lệnh ẩn.
- Làm sạch và xác thực tất cả nội dung được trích xuất. Loại bỏ hoặc thoát các thẻ và tập lệnh có khả năng gây hại trước khi sử dụng nội dung trong logic hạ nguồn hoặc mô hình AI.
- Ưu tiên trích xuất có cấu trúc hơn văn bản dạng tự do. Sử dụng các công cụ như
scrape_html,scrape_markdownhoặcbrowser_get_textcó mục tiêu với các bộ chọn an toàn đã biết để chỉ trích xuất nội dung bạn tin tưởng. - Áp dụng danh sách trắng tên miền hoặc bộ chọn khi thu thập các trang được tạo động, để hạn chế luồng dữ liệu đến các nguồn đã biết và đáng tin cậy.
- Ghi nhật ký và giám sát tất cả các yêu cầu đi được thực hiện qua trình duyệt hoặc công cụ thu thập, đặc biệt nếu bạn đang xử lý dữ liệu nhạy cảm, mã thông báo hoặc quyền truy cập mạng nội bộ.
🚫 Tránh
- Chèn HTML đã thu thập trực tiếp vào lời nhắc
- Cho phép người dùng chỉ định URL hoặc bộ chọn CSS tùy ý mà không xác thực
- Lưu trữ nội dung thu thập chưa lọc để sử dụng cho lời nhắc trong tương lai
Cộng đồng
Liên hệ Chúng tôi
Nếu có câu hỏi, đề xuất hoặc yêu cầu hợp tác, vui lòng liên hệ với chúng tôi qua:
- Email: [email protected]
- Trang web Chính thức: https://www.scrapeless.com
- Diễn đàn Cộng đồng: https://discord.gg/Np4CAHxB9a