Reexpress MCP Server
chính thứcCho phép xác minh thống kê theo Khoảng cách Tương đồng-Độ lớn cho các quy trình tìm kiếm, phần mềm và khoa học dữ liệu của bạn.
Tài liệu
Máy chủ Mô hình-Ngữ cảnh-Giao thức (MCP) Reexpress
Dành cho các LLM gọi công cụ (ví dụ: Claude Opus 4.7) và các máy khách MCP chạy trên macOS (Tahoe 26 trở lên trên Apple silicon) hoặc Linux
Tổng quan video1: Tại đây

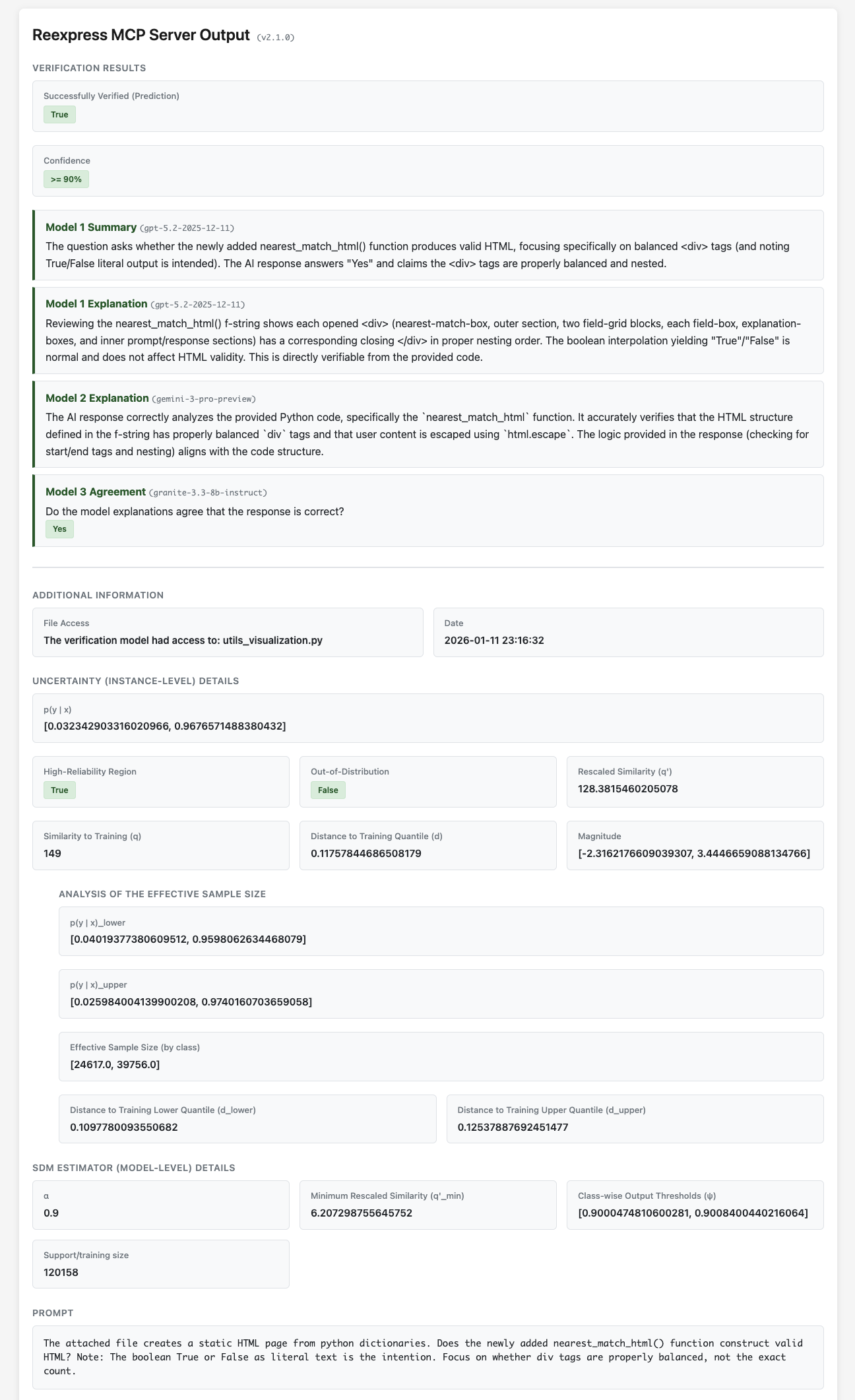

Máy chủ Reexpress MCP là một giải pháp cắm-và-chạy để thêm xác minh thống kê tiên tiến vào các pipeline LLM phức tạp của bạn, cũng như việc sử dụng LLM hàng ngày cho tìm kiếm và Hỏi-Đáp trong các bối cảnh phát triển phần mềm và khoa học dữ liệu. Đây là ý kiến thứ hai AI đáng tin cậy, mạnh mẽ về mặt thống kê đầu tiên cho các quy trình làm việc AI của bạn.
Chỉ cần cài đặt máy chủ MCP và sau đó thêm lời nhắc Reexpress vào cuối văn bản trò chuyện của bạn. LLM gọi công cụ (ví dụ: mô hình LLM Claude Opus 4.7 của Anthropic) sau đó sẽ kiểm tra phản hồi của nó với bộ ước lượng Khoảng cách-Tương đồng-Độ lớn (SDM) đã được huấn luyện trước của Reexpress, kết hợp gpt-5.5-2026-04-23, gemini-3.1-pro-preview, và gemini-embedding-2, cùng với đầu ra từ LLM gọi công cụ, và tính toán một ước lượng mạnh mẽ về độ không chắc chắn dự đoán dựa trên cơ sở dữ liệu các ví dụ huấn luyện và hiệu chuẩn từ tập dữ liệu OpenVerification1. Điểm độc đáo của phương pháp Reexpress là bạn có thể dễ dàng điều chỉnh mô hình cho các tác vụ của mình: Chỉ cần gọi các công cụ ReexpressAddTrue hoặc ReexpressAddFalse sau khi quá trình xác minh hoàn tất, và sau đó các lần gọi công cụ Reexpress trong tương lai sẽ tự động xem xét các cập nhật của bạn khi tính toán xác suất xác minh. Chúng tôi cũng bao gồm các tập lệnh huấn luyện cho mô hình, để bạn có thể chạy huấn luyện lại toàn bộ khi cần những thay đổi quan trọng hơn, hoặc bạn muốn sử dụng các LLM cơ sở thay thế.
[!LƯU Ý] Ngoài việc cung cấp cho bạn (người dùng) một ước lượng có nguyên tắc về độ tin cậy của đầu ra dựa trên hướng dẫn của bạn, chính LLM gọi công cụ có thể sử dụng đầu ra xác minh để tinh chỉnh dần câu trả lời, xác định xem nó có cần thêm tài nguyên hoặc công cụ bên ngoài hay không, hoặc đã đi vào ngõ cụt và cần hỏi bạn để làm rõ hoặc cung cấp thêm thông tin. Đó là cái mà chúng tôi gọi là lập luận với xác minh SDM --- một khả năng hoàn toàn mới trong bộ công cụ AI mà chúng tôi nghĩ sẽ mở ra một phạm vi rộng lớn hơn nhiều các trường hợp sử dụng cho LLM và các tác nhân LLM, cho cả cá nhân và doanh nghiệp.
Dữ liệu chỉ được gửi qua các lệnh gọi API LLM tiêu chuẩn đến Azure/OpenAI và Google, với các lệnh gọi gemini-3.1-pro-preview được cấp quyền truy cập tìm kiếm web tiêu chuẩn thông qua API; tất cả quá trình xử lý cho bộ ước lượng SDM được thực hiện cục bộ trên máy tính của bạn. Reexpress MCP có một hệ thống truy cập tệp đơn giản và bảo thủ, nhưng hiệu quả: Bạn kiểm soát những tệp bổ sung nào (nếu có) được gửi đến các API LLM bằng cách chỉ định rõ ràng các tệp thông qua các công cụ truy cập tệp ReexpressDirectorySet() và ReexpressFileSet().
Có gì mới trong phiên bản 2.4.0
Thẻ mô hình có sẵn tại đây.
Phiên bản 2.4.0 sử dụng gpt-5.5-2026-04-23 và gemini-3.1-pro-preview làm các mô hình sinh. Giống như 2.3.0.preview, gemini-embedding-2 thay thế mô hình granite-3.3-8b-instruct cục bộ làm mô hình biểu diễn sự đồng thuận. Điều này đơn giản hóa đáng kể việc chạy Máy chủ, vì bạn không còn cần phải chạy cục bộ một mô hình hàng tỷ tham số nữa. Ngoài ra, chúng tôi cũng đã mở rộng tập dữ liệu OpenVerification1 với các ví dụ mới. Xem thẻ mô hình để biết chi tiết.
Ghi chú bổ sung trong changelog.md.
Yêu cầu Hệ thống
Máy chủ MCP chạy trên Linux và macOS. Yêu cầu chính là máy chạy máy chủ MCP cần có khả năng chạy cục bộ một mô hình PyTorch nhỏ 3 triệu tham số, vì vậy yêu cầu tính toán là tối thiểu. (Đúng như đã viết: Chỉ 3 triệu tham số; không phải 3 tỷ tham số. Mô hình bao gồm một kích hoạt SDM trên gemini-embedding-2 và đầu ra phân loại của hai mô hình ngôn ngữ API.)
Cài đặt
Xem INSTALL.md.
[!MẸO] Máy chủ Reexpress MCP dễ thiết lập so với các máy chủ MCP khác, nhưng chúng tôi giả định bạn có chút quen thuộc với LLM, MCP và các công cụ dòng lệnh. Đối tượng mục tiêu của chúng tôi là các nhà phát triển và nhà khoa học dữ liệu. Chỉ thêm các máy chủ MCP khác từ các nguồn mà bạn tin tưởng, và lưu ý rằng các công cụ MCP khác có thể thay đổi hành vi của máy chủ MCP của chúng tôi theo những cách không mong đợi.
Tùy chọn cấu hình
Xem CONFIG.md.
Cách Sử dụng
Xem documentation/HOW_TO_USE.md.
Tạo HTML tĩnh với đầu ra từ lệnh gọi công cụ
Xem documentation/OUTPUT_HTML.md.
Hướng dẫn
Xem documentation/GUIDELINES.md.
Câu hỏi Thường gặp
Xem documentation/FAQ.md.
Dữ liệu Huấn luyện và Hiệu chuẩn
Đánh giá trên OpenVerification1
Bài báo Trình diễn Hệ thống
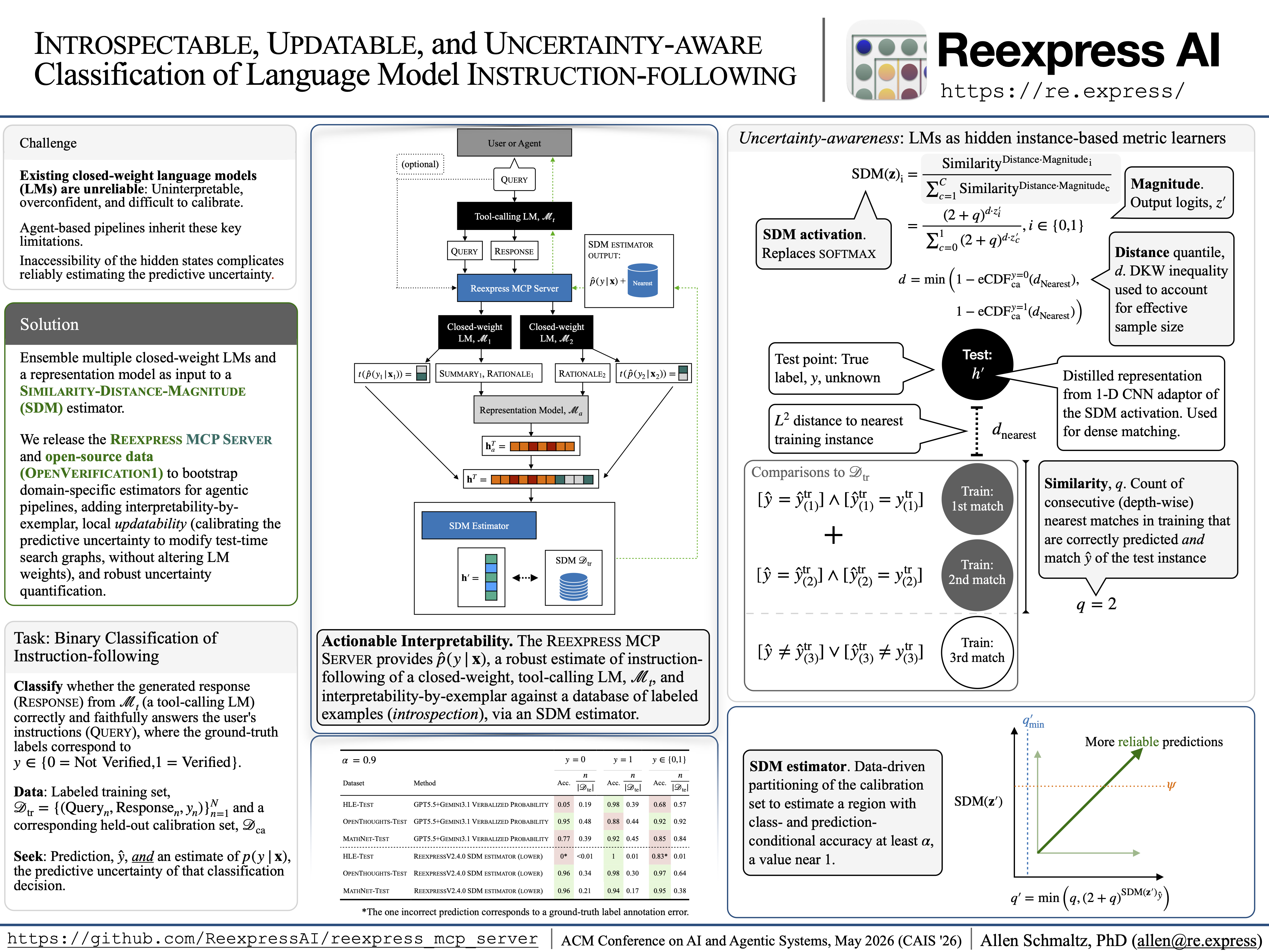
Một bản sao của bài báo trình diễn hệ thống của chúng tôi "Introspectable, Updatable, and Uncertainty-aware Classification of Language Model Instruction-following", tập trung đặc biệt vào phiên bản 2.1.0 của Máy chủ Reexpress MCP, được bao gồm tại đây. Các tập lệnh hỗ trợ để tái tạo phân tích được bao gồm tại đây.
Thẻ mô hình cho phiên bản 2.4.0, làm nổi bật những thay đổi kể từ bài báo trình diễn hệ thống, có sẵn tại đây.
Trích dẫn
Nếu bạn thấy phần mềm này hữu ích, hãy cân nhắc trích dẫn các bài báo đã được bình duyệt sau:
@misc{Schmaltz-2025-SimilarityDistanceMagnitudeActivations,
title={Similarity-Distance-Magnitude Activations},
author={Allen Schmaltz},
year={2025},
eprint={2509.12760},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2509.12760},
note={To appear in \emph{Findings of the Association for Computational Linguistics: ACL 2026}, San Diego, CA, USA.},
}
@inproceedings{Schmaltz-2026-ReexpressMCPServer,
author = {Schmaltz, Allen},
title = {Introspectable, Updatable, and Uncertainty-aware Classification of Language Model Instruction-following},
year = {2026},
isbn = {9798400724152},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3786335.3813214},
doi = {10.1145/3786335.3813214},
abstract = {In this system demonstration paper, we introduce an open-source implementation for training and testing Similarity-Distance-Magnitude (SDM) estimators for the task of binary classification of instruction-following of closed-weight language models (LMs). This SDM estimator provides an approximately conditional estimate of the predictive uncertainty over instruction-following, conditional on multiple closed-weight LMs and the representation space of an open-weight model. While it would be more robust to use as input to the SDM estimator the hidden-states of the underlying models, this indirect, compositional proxy is more reliable than verbalized uncertainty and adds a means of auditing the predictions against data with known labels. We release the code as an MCP Server to simplify adding interpretability-by-exemplar and locally updatable, uncertainty-aware instruction-following to agent-based pipelines. We further release OpenVerification1, a balanced set of over two million examples of instruction-following and associated rationales from recent closed-weight LMs, for bootstrapping domain-specific estimators. Finally, we discuss limitations of estimating the predictive uncertainty without access to the hidden-states of the tool-calling LM and provide practical guidance for applications.},
booktitle = {Proceedings of the ACM Conference on AI and Agentic Systems},
pages = {1259–1269},
numpages = {11},
keywords = {Approximately conditional calibration, Interpretability-by-exemplar, Classification of instruction-following, Model ensembles},
location = {
},
series = {CAIS '26}
}
Footnotes
-
The định dạng đầu ra đã thay đổi kể từ v1.0.0 được sử dụng trong video. Xem changelog.md. ↩