Local RAG
Performs a local RAG search on your query using live web search for context extraction.
Documentation
mcp-local-rag
"primitive" RAG-like web search model context protocol (MCP) server that runs locally. ✨ no APIs ✨
A RAG-based web search and deep research model context protocol (MCP) server that runs entirely locally. Features multi-engine research across 9+ search backends with semantic similarity ranking, and requires no API keys.
![]()

![]()
- Features
- Installation
- Agent Skills
- Security audits
- MCP Clients
- Examples on Claude Desktop
- Contributing
- License
%%{init: {'theme': 'base'}}%%
flowchart TD
A[User] -->|1.Submits LLM Query| B[Language Model]
B -->|2.Sends Query| C[mcp-local-rag Tool]
subgraph mcp-local-rag Processing
C -->|Search DuckDuckGo| D[Fetch 10 search results]
D -->|Fetch Embeddings| E[Embeddings from Google's MediaPipe Text Embedder]
E -->|Compute Similarity| F[Rank Entries Against Query]
F -->|Select top k results| G[Context Extraction from URL]
end
G -->|Returns Markdown from HTML content| B
B -->|3.Generated response with context| H[Final LLM Output]
H -->|5.Present result to user| A
classDef default stroke:#333,stroke-width:2px;
classDef process stroke:#333,stroke-width:2px;
classDef input stroke:#333,stroke-width:2px;
classDef output stroke:#333,stroke-width:2px;
class A input;
class B,C process;
class G output;
Features
Multi-Engine Deep Research
The server supports comprehensive multi-engine research capabilities that go beyond simple single-query searches:
- 9+ Search Backends: DuckDuckGo, Google, Bing, Brave, Wikipedia, Yahoo, Yandex, Mojeek, Grokipedia
- Multi-Topic Research: Search multiple related queries simultaneously
- Semantic Ranking: RAG-like similarity scoring ranks the most relevant results
- Privacy Options: Choose privacy-focused engines (DuckDuckGo, Brave) or comprehensive ones (Google)
- No API Keys Required: All processing runs locally with embedded models
Deep Research Tools
-
deep_research- Comprehensive multi-engine research- Search across multiple engines simultaneously
- Ideal for complex topics requiring diverse perspectives
- Customizable backends and result limits
-
deep_research_google- Google-focused deep dive- Leverage Google's comprehensive index
- Best for technical/scientific queries
-
deep_research_ddgs- Privacy-first deep research- Use DuckDuckGo for private, extensive research
- Great for general topics without tracking
-
rag_search_ddgs&rag_search_google- Quick single searches- Fast, focused searches when you need quick answers
Installation
Locate your MCP config path here or check your MCP client settings.
Run Directly via uvx
This is the easiest and quickest method. You need to install uv for this to work.
Add this to your MCP server configuration:
{
"mcpServers": {
"mcp-local-rag":{
"command": "uvx",
"args": [
"--python=3.10",
"--from",
"git+https://github.com/nkapila6/mcp-local-rag",
"mcp-local-rag"
]
}
}
}
Using Docker (recommended)
Ensure you have Docker installed.
Add this to your MCP server configuration:
{
"mcpServers": {
"mcp-local-rag": {
"command": "docker",
"args": [
"run",
"--rm",
"-i",
"--init",
"-e",
"DOCKER_CONTAINER=true",
"ghcr.io/nkapila6/mcp-local-rag:v1.0.2"
]
}
}
}
Agent Skills
This repository includes Agent Skills that teach Claude how to effectively use the mcp-local-rag tools for intelligent web searches and deep research. Skills are folders of instructions that Claude loads dynamically to improve performance on specialized tasks.
Available Skills
local-rag-search - Teaches Claude best practices for:
- Smart tool selection: Choosing between quick searches or comprehensive deep research
- Multi-engine research: Using multiple search backends for diverse perspectives
- Effective query formulation: Writing natural language queries that yield better results
- Parameter tuning: Adjusting
num_results,top_k, and backend selection for different use cases - Privacy-aware searching: Defaulting to privacy-focused engines while allowing comprehensive searches when needed
Deep Research Use Cases
The skill enables comprehensive topic research using multiple search terms and engines. It's particularly useful for technical deep dives that leverage Google's documentation coverage, multi-perspective analysis that compares information across different search engines, privacy-focused research using DuckDuckGo or Brave, and factual verification by cross-referencing Wikipedia and other authoritative sources.
Using the Skills
In Claude Desktop:
- Go to Settings → Skills
- Click Add Skill → Add from folder
- Select
skills/local-rag-search/
In conversations: Once loaded, simply ask Claude to search for information and it will automatically apply the skill's best practices. Try queries like:
- "Do deep research on recent quantum computing developments"
- "Search multiple sources for sustainable energy solutions"
- "Find comprehensive technical documentation about Kubernetes optimization"
Learn more about Agent Skills at the Anthropic Skills Repository.
See the skills/README.md for detailed usage instructions and skill development guidelines.
Security audits
MseeP does security audits on every MCP server, you can see the security audit of this MCP server by clicking here.
![]()
MCP Clients
The MCP server should work with any MCP client that supports tool calling. Has been tested on the below clients.
- Claude Desktop
- Cursor
- Goose
- Others? You try!
Examples on Claude Desktop
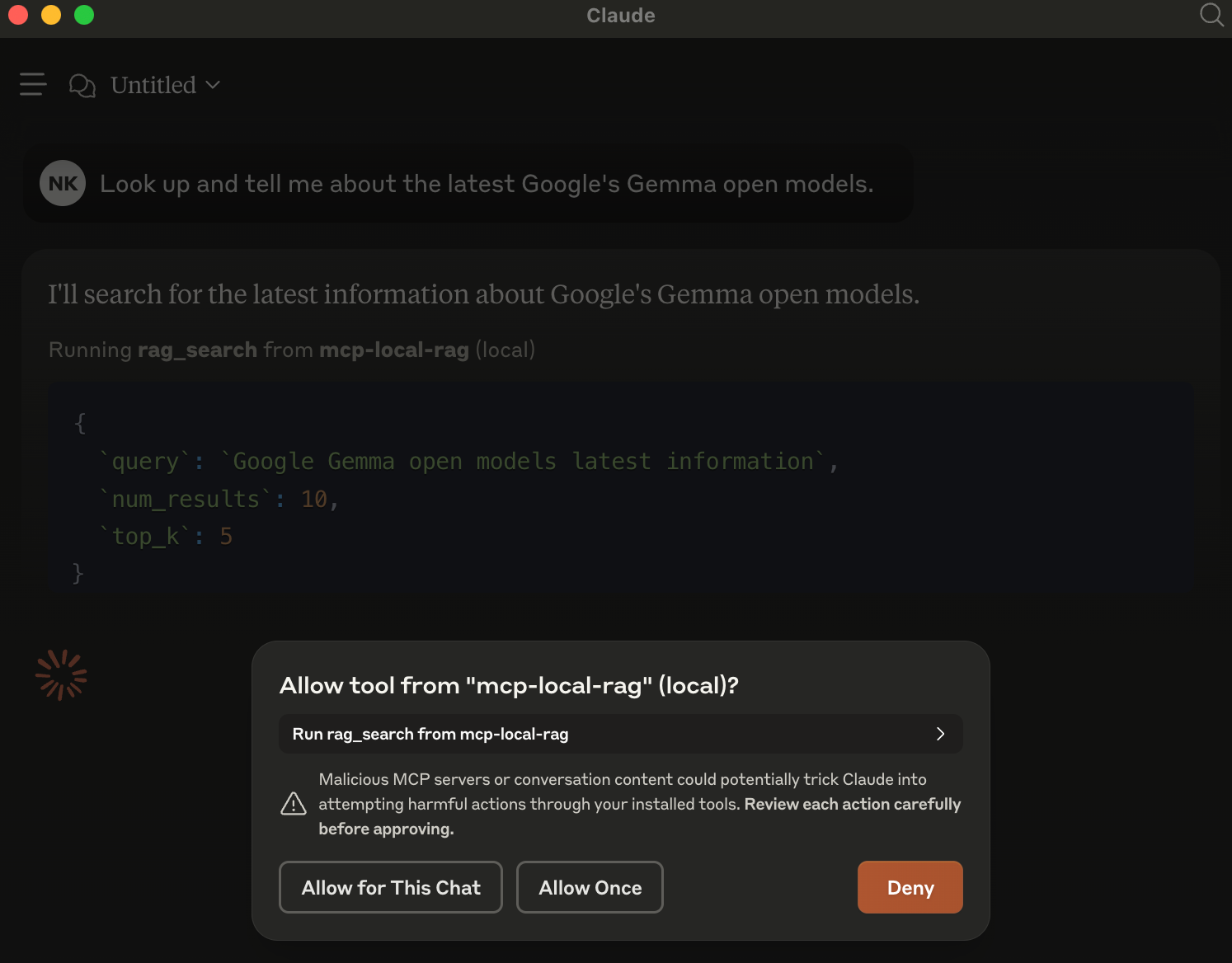
When an LLM (like Claude) is asked a question requiring recent web information, it will trigger mcp-local-rag.
When asked to fetch/lookup/search the web, the model prompts you to use MCP server for the chat.
In the example, have asked it about Google's latest Gemma models released yesterday. This is new info that Claude is not aware about.
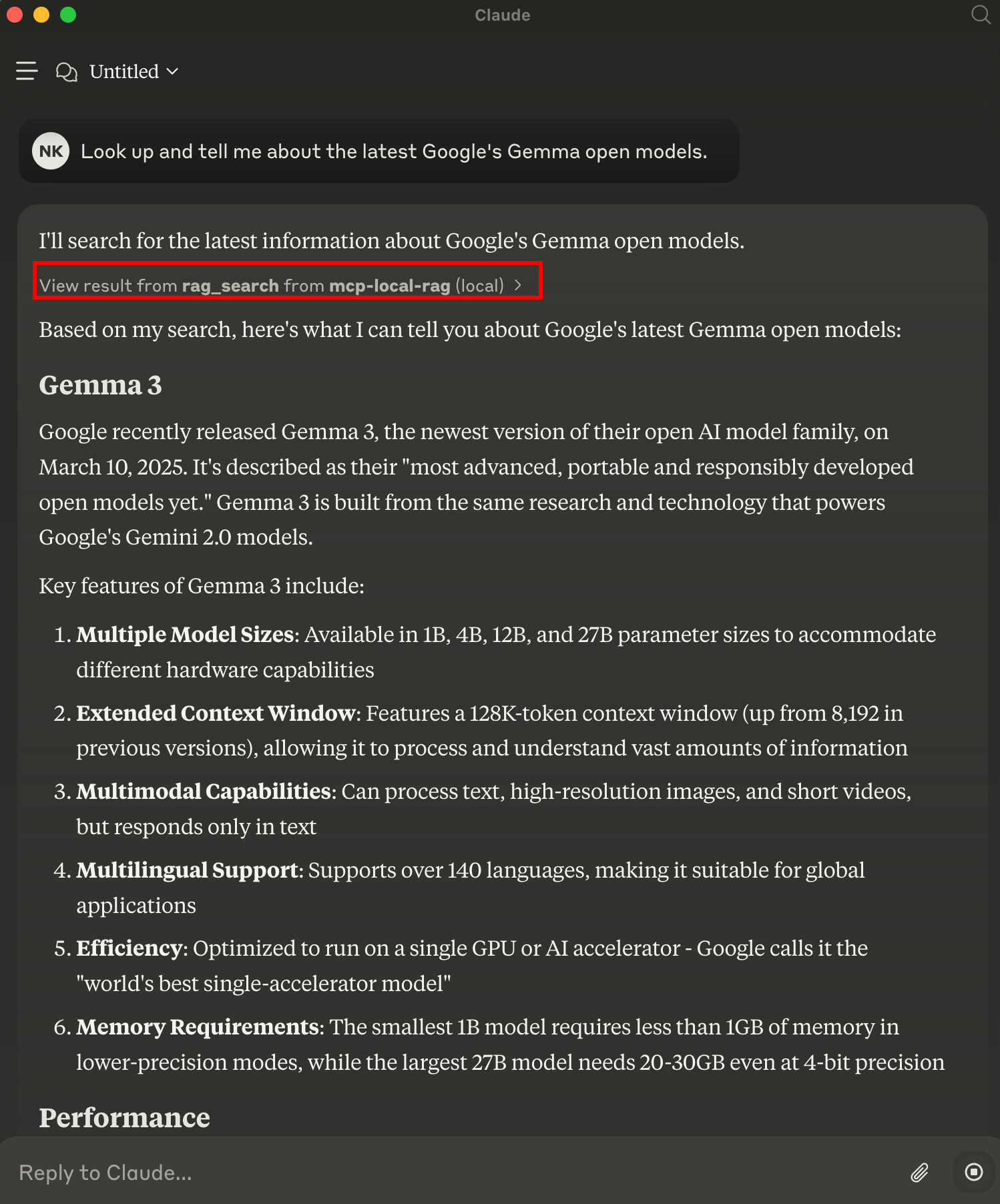
Result
mcp-local-rag performs a live web search, extracts context, and sends it back to the model—giving it fresh knowledge:
Buy Me A Coffee
If the software I've built has been helpful to you. Please do buy me a coffee, would really appreciate it! 😄

Contributing
Have ideas or want to improve this project? Issues and pull requests are welcome!
License
This project is licensed under the MIT License.