Vault MCP
An Obsidian plugin that embeds an MCP server to interact with your notes using AI.
Documentation
Vault MCP
![]()


This Obsidian plugin embeds an MCP (Model Context Protocol) server directly within Obsidian, providing a streamlined way for applications to interact with your vault.
Desktop Only
Installation • Features • Usage • Development • Schema Guide Notes
Features
- Embedded MCP Server: Hosts the MCP server within Obsidian itself as a plugin, simplifying setup and improving performance
- Vault Access via MCP: Exposes your vault through standardized tools
- Structured Data Support: Define custom schemas for structured note creation and validation
- File Operations:
- Read and write files
- Fuzzy search across your vault
- Navigate vault structure programmatically
- Structured data storage and access
- Configurable: Customize server settings, tool availability, and authentication
- Optional Authentication: Secure your server with optional Bearer token authentication.
Background
Vault MCP started as a small component of a larger project that needed an alternative to traditional RAG methods. It needed something LLMs could use to reliably retrieve and update structured, human-readable data, without relying on unpredictable vector databases or embedding fuzziness.
Existing Obsidian MCP servers weren't a great fit. They were REST-heavy, complex, and not well-suited for language models to interact with naturally. So this plugin was spun off to solve that: a lightweight interface for working with Obsidian vaults in a way that's natural for LLMs and transparent for humans.
Installation
Community Plugins (Recommended)
- Open Obsidian Settings > Community Plugins
- Search for "Vault MCP"
- Click Install, then Enable
- Configure settings as needed
Manual Installation
- Download the latest release zip
- Extract to
<vault>/.obsidian/plugins/ - Enable in Obsidian settings
Usage
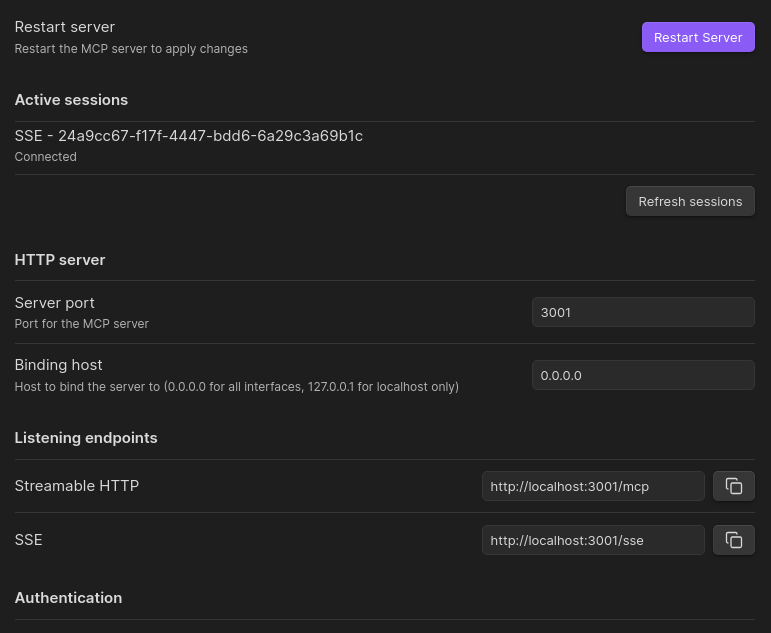
Basic Setup
- Enable the plugin in Obsidian's Community Plugins section
- Open plugin settings to configure:
- Server Port (default:
3000) - Binding Host (default: 127.0.0.1; use 0.0.0.0 for LAN access)
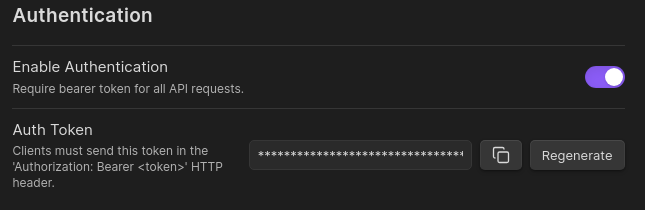
- (Optional) Enable Authentication:
- Toggle Enable Authentication
- Copy the provided Auth Token
- Include the token in HTTP headers:
Authorization: Bearer <your_token>
- Click Restart Server to apply changes
Connection Methods
The plugin currently only supports Server-Sent Events (SSE) and StreamHTTP connections. For applications that require stdio connections (like Claude Desktop), you'll need to use a proxy. You can follow Cloudflare's guide on setting up a local proxy using mcp-remote.
Here is an example claude_desktop_config.json to use mcp-remote local proxy.
{
"mcpServers": {
"obsidian": {
"command": "npx",
"args": ["mcp-remote", "http://localhost:<your_server_port>/sse"]
}
}
}
You can find the correct url from the plugin's setting panel under endpoints.
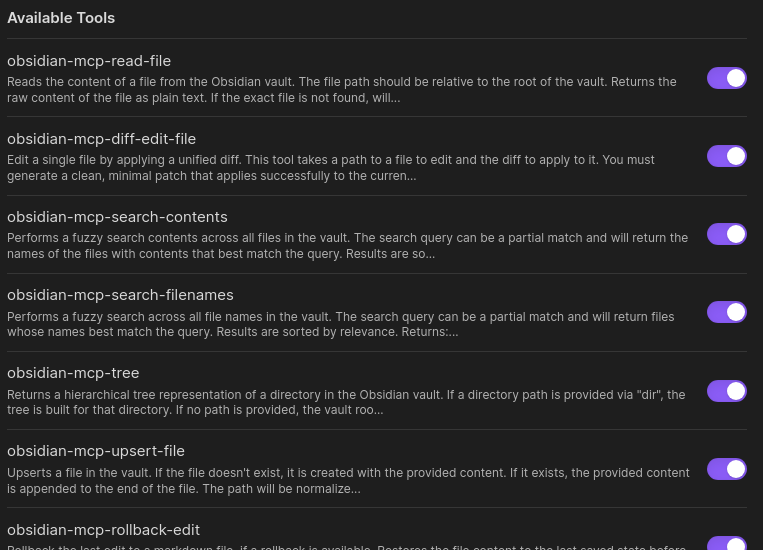
Available Tools
obsidian-mcp-read-file: Get file contentsobsidian-mcp-diff-edit-file: Edit files using simplified udiff (see below)obsidian-mcp-search-contents: Fuzzy search across the contents of all files in your vaultobsidian-mcp-search-filenames: Fuzzy search across all file names in your vaultobsidian-mcp-list-files: List files and directories in your vault with customizable depth and result limitsobsidian-mcp-upsert-file: Create or update filesobsidian-mcp-rollback-edit: Roll back the last edit to a markdown file (reverts the last change made by supported tools)
Highlighted tools
obsidian-mcp-diff-edit-file
This tool edits a single file by applying a simplified udiff. This is basically how Cursor and other LLM based code editors work. It is best for smarter models, as smaller ones tend to struggle to create the diffs accurately. To help with this problem, the tool returns a diff of the actual changes applied to the file. This helps the model determine whether the changes applied matched its expectations.
An example of this simplified udiff format is as follows:
--- example.md
+++ example.md
@@ ... @@
-Old line of text
+New line of text
This simplified diff system is inspired by Aider's simplified diff format, you can read more about their work here
obsidian-mcp-rollback-edit
This tool allows you to revert the last change made to a markdown file by supported file-writing tools (obsidian-mcp-diff-edit-file, obsidian-mcp-upsert-file, or structured update tools). Before any of these tools modify a file, the previous content is saved in a rollback store. You can use obsidian-mcp-rollback-edit to restore the file to its previous state.
If a rollback is available, the file will be restored to its previous content, and you'll get a message with the timestamp and reason for the last change. If not, you'll get an error message.
Structured Data Edits (dynamic tools)
Create and update structured content in a typesafe manner using tools.
TL;DR LLMs are unreliable at directly editing structured formats like JSON or YAML. They break formatting or forget fields. Instead, Vault MCP defines a schema for your data and exposes it as a tool. The model then edits the structure via tool calls.
If you want to write a schema go here: Write Your Own Schemas
How it works
LLMs are just bad at working with structured data. They break formatting, inject their own formatting, forget things, etc.
Vault MCP takes a somewhat novel approach to dealing with structured data, it creates a tool that the LLM can call to make updates to a data structure.
When the LLM wants to edit the structured data, it makes a tool call where the parameters of the tool call correspond to the fields of the data structure.
Most "good" models are trained specifically to make tool calls so this is a much more stable system.
This mapping of the structured data to the tool is done in a few steps
- You define a schema using JSON Schema (draft-07), written in YAML.
- Vault MCP validates it using a built-in metaschema
- The schema is converted to a zod
- A tool is dynamically created from that schema
Schemas
Each schema has two sections:
metadataDefines file naming and storage detailsfieldsDefines the structure of your data (used to generate the Zod tool)
The schemas are json schema draft 07, but written in yaml for better usability. To be able to do this dynamic tool generation, the plugin needs to know both the structure of the structured data, but also some metadata about file names, locations etc.
User Schemas
Here is an example of a user defined schema for storing recipes
metadata:
schemaName: "Recipe"
description: |
Updates a recipe file given a schema and identifiers. Creates the file if it doesn't exist.
Uses the Recipe Schema. It merges new non-default data into existing frontmatter.
identifierField: "recipe_id"
pathTemplate: "Recipes/${category}/${recipe_id}/Recipe.md"
pathComponents:
- category
- recipe_id
fields:
recipe_id:
type: "string"
description: "Unique identifier for the recipe (e.g., `chocolate_chip_cookies`)."
optional: false
category:
type: "string"
description: "Recipe category for organizing files (e.g., `Desserts`)."
optional: false
title:
type: "string"
description: "Name of the recipe (e.g., `Chocolate Chip Cookies`)."
optional: true
description:
type: "string"
description: "Brief description of the recipe and its highlights."
optional: true
servings:
type: "number"
description: "Number of servings the recipe yields (must be at least 1)."
optional: true
minimum: 1
maximum: 100
default: 4
ingredients:
type: "array"
description: "List of ingredients required for the recipe."
optional: true
items:
type: "object"
properties:
name:
type: "string"
description: "The name of the ingredient (e.g., `all-purpose flour`)."
optional: false
quantity:
type: "string"
description: "Amount needed (e.g., `2 cups`, `1 tsp`)."
optional: true
---
This generates an MCP tool that looks like this:
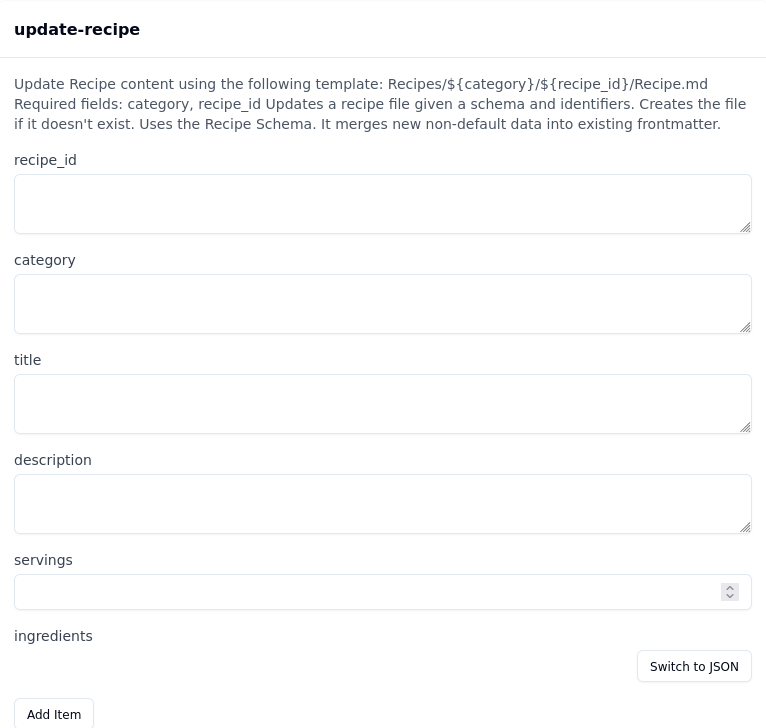
When you use it to put data into Obsidian the result looks like this:
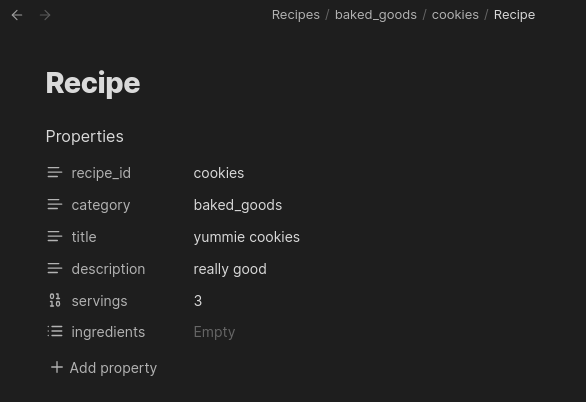
Meta Schema
To validate that the user defined schema contains the required components we have a meta schema defined in json schema. You can read the file here
It also helps narrow the types to something that can be converted into zod more clearly.
You can use it to see a list of types and modifiers you can use such as default values, minimum and maximum etc.
Here is the yaml version of the meta schema
"$schema": http://json-schema.org/draft-07/schema#
title: MCP Structured Document Schema (JSON Schema Valid)
description: Strict meta-schema for structured tools using zod compatible fields.
type: object
required:
- metadata
- fields
properties:
metadata:
type: object
required:
- schemaName
- description
- identifierField
- pathTemplate
- pathComponents
properties:
schemaName:
type: string
description:
type: string
identifierField:
type: string
pathTemplate:
type: string
pathComponents:
type: array
items:
type: string
additionalProperties: false
fields:
type: object
patternProperties:
"^[a-zA-Z_][a-zA-Z0-9_]*$":
type: object
required:
- type
properties:
type:
type: string
enum:
- string
- number
- boolean
- date
- array
- object
- literal
- unknown
- any
description:
type: string
default: {}
minimum:
type: number
maximum:
type: number
enum:
type: array
items: {}
items:
type: object
properties:
type: object
required:
type: array
items:
type: string
additionalProperties: true
additionalProperties: false
additionalProperties: false
Writing your own schemas
Start by thinking about two things:
Where and how will the file be stored?
Use metadata to describe filename templates and how to identify a file (e.g. by ID).
What structured data will be in the file?
Use fields to define the structure using types like string, number, array, object, and modifiers like default, minimum, etc.
Once defined, your schema will automatically become a tool the LLM can use to update that file type.
Place the schema that you write into a "schema" directory in your obsidian vault. The schema should be defined in a markdown file contained within a codeblock with the syntax setting like this:
```yaml schema
There can be other text in the same markdown such as notes or descriptions, but Vault MCP will only use the yaml defined in the specified codeblock above.
Place this directory path into the dynamic tools settings in Vault MCP settings and restart the plugin to parse and generate the dynamic tools. They will populate in the settings panel like this:
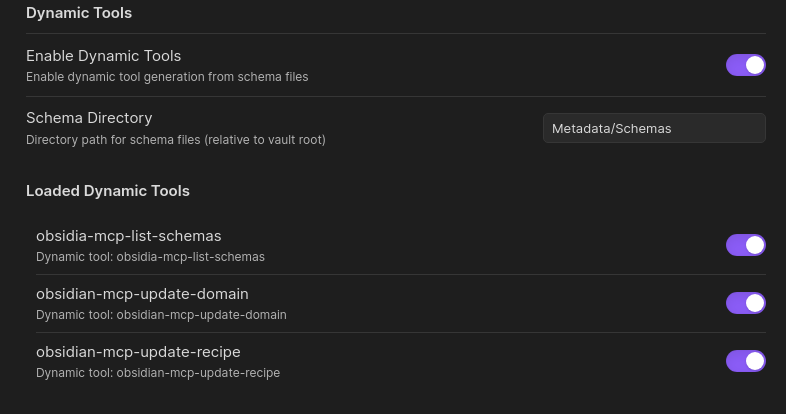
The list-schemas tool is automatically created when the dynamic tools are to allow clients to view the schemas directly if necessary.
Obsidian will render the YAML structure as a nicely formatted frontmatter or embedded block in your markdown.
When writing schemas, I found this tool particularly helpful stefanterdell.github.io/json-schema-to-zod-react. Vault MCP uses this internally to generate the zod but this is a more visual method to help in troubleshooting.
Development
Prerequisites
- Basic knowledge of TypeScript and Obsidian API
A nix flake is provided to create a standardized development environment.
Setup Development Environment
git clone https://github.com/jlevere/obsidian-mcp-plugin.git
cd obsidian-mcp-plugin
nix develop
# for cool people who use direnv
# echo "use flake" > .envrc && direnv allow
pnpm install
pnpm build:dev
Project Structure
src/: Source codemanagers/: Core functionality managersstructured-tools/: Schema validation and toolsutils/: Helper utilitiesvault/: Vault interaction code
tests/: Test files
Build Production
pnpm run build
Notes
- This plugin is only supported on desktop Obsidian.
- Authentication bearer tokens are stored in the plugin data.json file. This token can be rolled on demand.
Contributing
Contributions are welcome! Please feel free to open an issue or pull request.
Credits
- Inspired by obsidian-local-rest-api by coddingtonbear
- Uses Model Context Protocol for AI interactions
License
This project is licensed under the MIT License - see the LICENSE file for details.