Context-Fabric
Corpus search and linguistic analysis for AI Agents

Context-Fabric
Production-ready corpus analysis for the age of AI




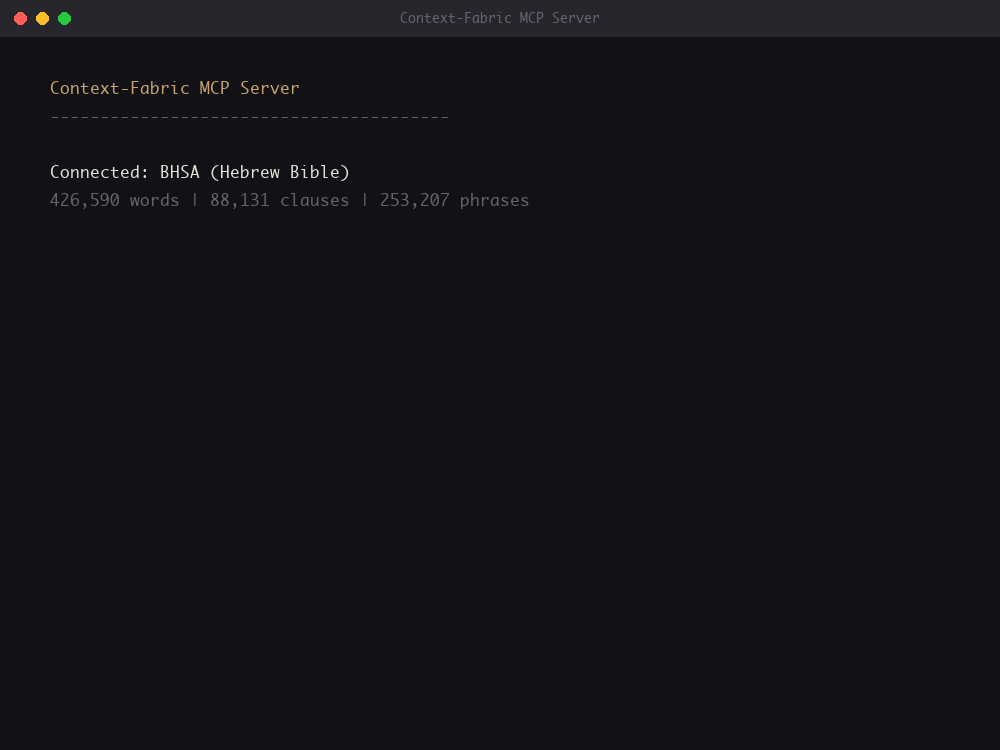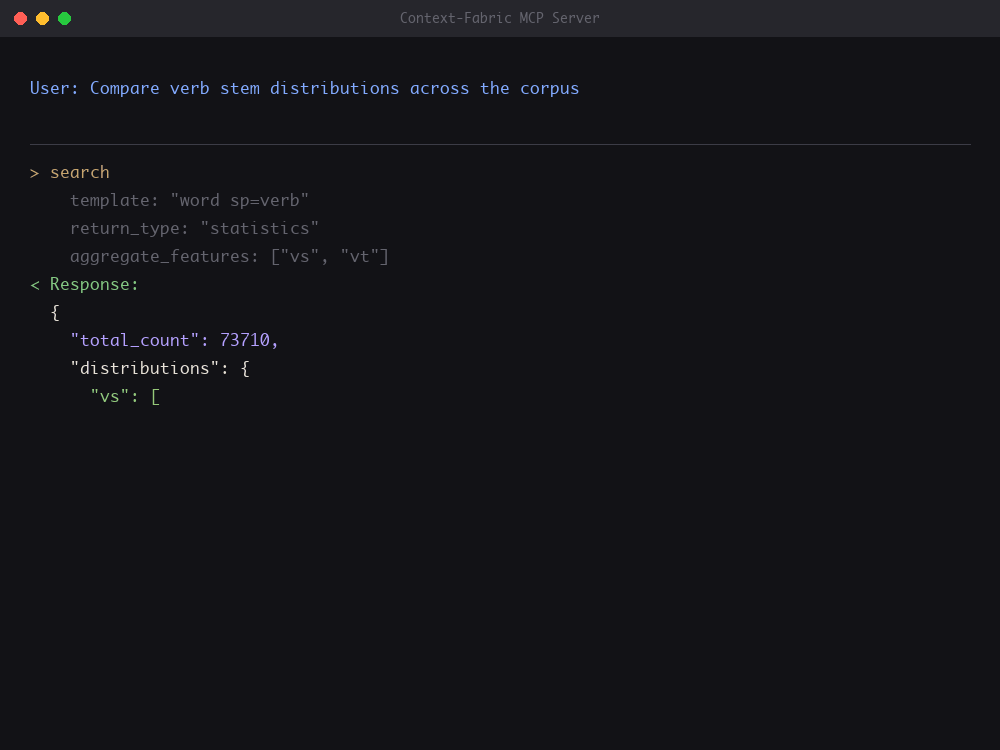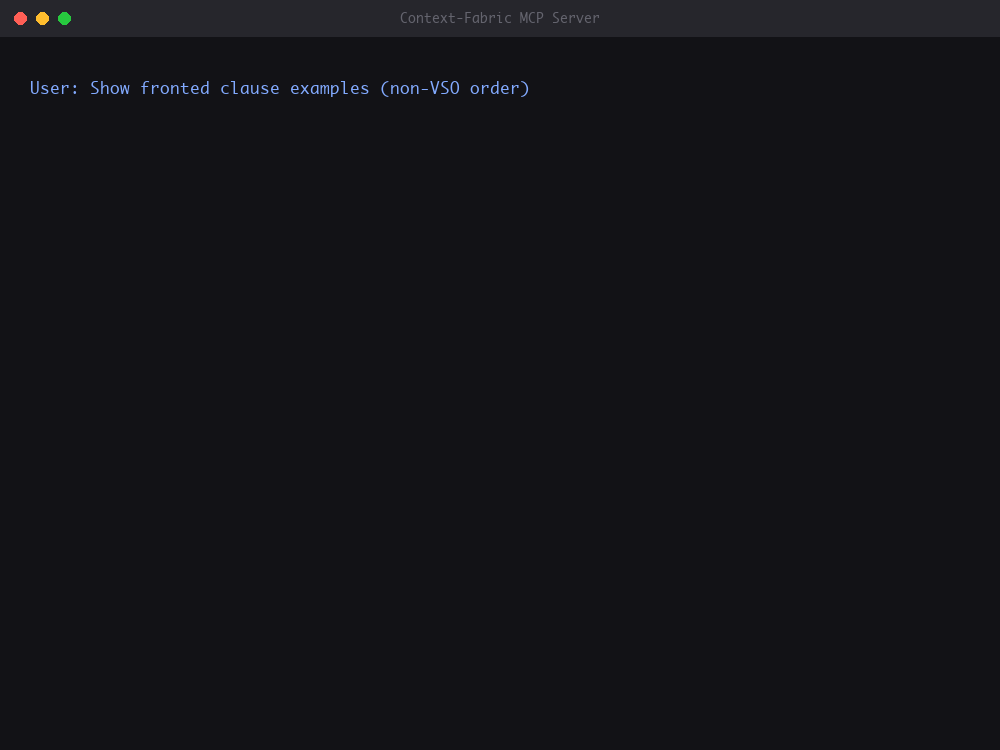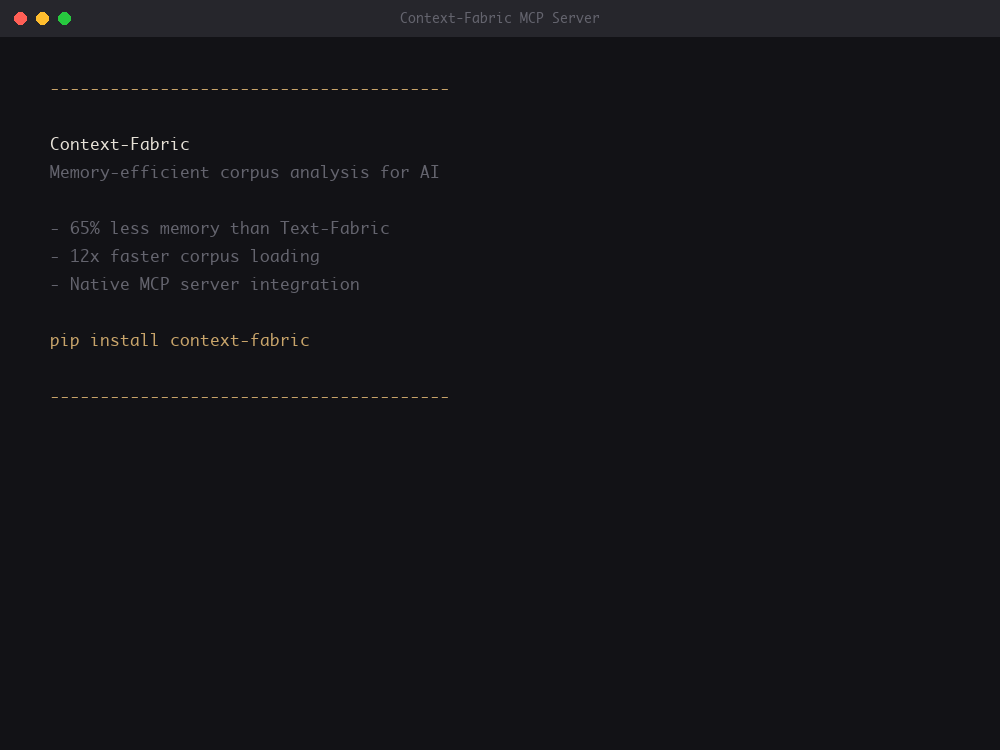
AI agents running advanced grammatical queries via the Model Context Protocol
Overview
Context-Fabric brings corpus analysis into the AI era. Built on the proven Text-Fabric data model, it introduces a memory-mapped architecture enabling parallel processing for production deployments—REST APIs, multi-worker services, and AI agent tools via MCP.
- Built for Production — Memory-mapped arrays enable true parallelization. Multiple workers share data instead of duplicating it.
- AI-Native — MCP server exposes corpus operations to Claude, GPT, and other LLM-powered tools.
- Powerful Data Model — Standoff annotation, graph traversal, pattern search, and arbitrary feature annotations.
- Dramatic Efficiency — 3.5x faster loads, 65% less memory in single process, 62% less with parallel workers.
MCP Server for AI Agents
Context-Fabric includes cfabric-mcp, a Model Context Protocol server that exposes corpus operations to AI agents:
# Start the MCP server
cfabric-mcp --corpus /path/to/bhsa
# Or with SSE transport for remote clients
cfabric-mcp --corpus /path/to/bhsa --sse 8000
The server provides 10 tools for discovery, search, and data access—designed for iterative, token-efficient agent workflows.
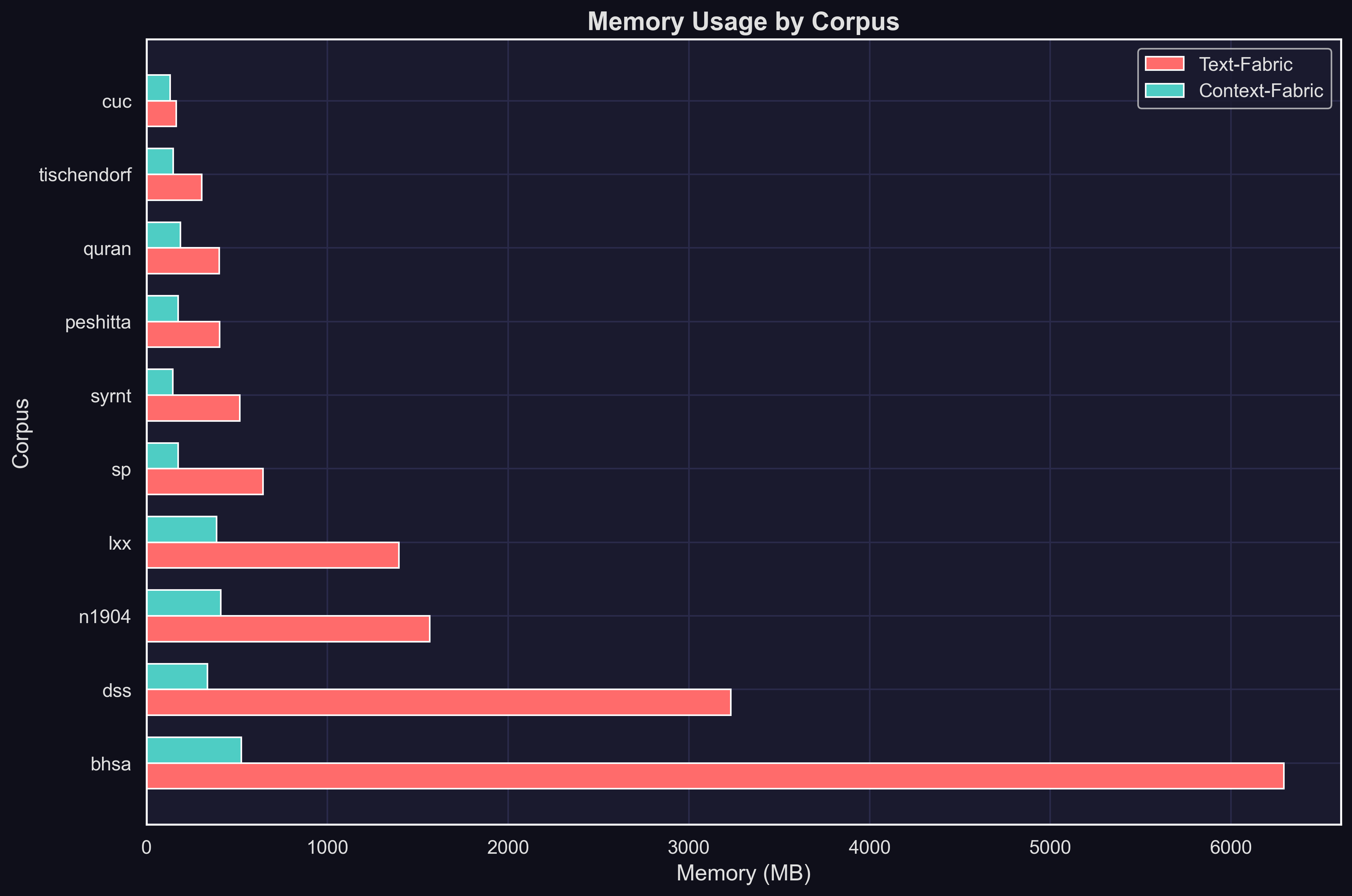
Memory Efficiency
Text-Fabric loads entire corpora into memory—effective for single-user research, but each parallel worker duplicates that memory footprint. Context-Fabric's memory-mapped arrays change the equation:
| Scenario | Memory Reduction |
|---|---|
| Single process | 65% less |
| 4 workers (spawn) | 62% less |
| 4 workers (fork) | 62% less |
Mean reduction across 10 corpora. Memory measured as total RSS after loading from cache.
Installation
# Core library
pip install context-fabric
# With MCP server
pip install context-fabric[mcp]
Quick Start
from cfabric.core import Fabric
# Load a corpus
CF = Fabric(locations='path/to/corpus')
api = CF.load('feature1 feature2')
# Navigate nodes
for node in api.N.walk():
print(api.F.feature1.v(node))
# Traverse structure
embedders = api.L.u(node) # nodes containing this node
embedded = api.L.d(node) # nodes within this node
# Search patterns
results = api.S.search('''
clause
phrase function=Pred
word sp=verb
''')
Core API
| API | Purpose |
|---|---|
| N | Walk nodes in canonical order |
| F | Access node features |
| E | Access edge features |
| L | Navigate locality (up/down the hierarchy) |
| T | Retrieve text representations |
| S | Search with structural templates |
Performance
Context-Fabric trades one-time compilation cost for dramatic runtime efficiency. Compile once, benefit forever.
| Metric | Mean Improvement |
|---|---|
| Load time | 3.5x faster |
| Memory (single) | 65% less |
| Memory (spawn) | 62% less |
| Memory (fork) | 62% less |
Mean across 10 corpora. The larger cache enables memory-mapped access—no deserialization, instant loads, shared memory across workers.
Run benchmarks yourself:
pip install context-fabric[benchmarks]
cfabric-bench memory --corpus path/to/corpus
Packages
| Package | Description |
|---|---|
| context-fabric | Core graph engine |
| cfabric-mcp | MCP server for AI agents |
| cfabric-benchmarks | Performance benchmarking suite |
Links
Citation
If you use Context-Fabric in your research, please cite:
Kingham, Cody. "Carrying Text-Fabric Forward: Context-Fabric and the Scalable Corpus Ecosystem." January 2026.
Authors
Context-Fabric by Cody Kingham, built on Text-Fabric by Dirk Roorda.
License
MIT
Related Servers
Jilebi
A secure, extensible MCP runtime with JS plugins
News MCP
Provides access to news articles from a PostgreSQL database and offers a tool to summarize them using the OpenAI API.
ShapeBridge
MCP Agent to understand 3D models
Kalshi MCP Server
A simple MCP server to interact with prediction market Kalshi
RequestRepo MCP
A MCP for RequestRepo
Bazi Calculation
A professional Bazi (Chinese astrology) calculation server providing full analysis including four pillars, five elements, zodiac, and lunar dates with timezone support.
Bazi
An MCP server for accessing Bazi (Chinese astrology) data, requiring an API key.
RootVine
Cross-platform music link resolution for AI agents. Connects Claude, ChatGPT, and other AI agents to trusted music data via the Model Context Protocol.
Scrptly Video Generator
An Ai Video Agent that can generate professional and complex videos with simple prompts and context images.
Memory Anchor
Persistent memory MCP server for AI coding assistants with 5-layer cognitive model, hybrid semantic+keyword search, and checkpoint/resume. Zero cloud, local-first.