Scrapeless MCP Server
oficialIntegre resultados em tempo real do Scrapeless Google SERP (Google Search, Google Flight, Google Map, Google Jobs...) em suas aplicações LLM. Este servidor permite a recuperação dinâmica de contexto para fluxos de trabalho de IA, chatbots e ferramentas de pesquisa.
Documentação

Servidor MCP Scrapeless
Bem-vindo ao Servidor oficial de Protocolo de Contexto de Modelo (MCP) Scrapeless — uma poderosa camada de integração que capacita LLMs, Agentes de IA e aplicações de IA a interagir com a web em tempo real.
Construído sobre o padrão MCP aberto, o Servidor MCP Scrapeless conecta perfeitamente modelos como ChatGPT, Claude e ferramentas como Cursor e Windsurf a uma ampla gama de capacidades externas, incluindo:
- Integração com serviços Google (Pesquisa, Trends)
- Automação de navegador para navegação e interação em nível de página
- Scrape de sites dinâmicos com muito JavaScript — exporte como HTML, Markdown ou capturas de tela
Seja você esteja construindo um assistente de pesquisa de IA, um copiloto de codificação ou agentes web autônomos, este servidor fornece o contexto dinâmico e os dados do mundo real que seus fluxos de trabalho precisam — sem ser bloqueado.
Exemplos de Uso
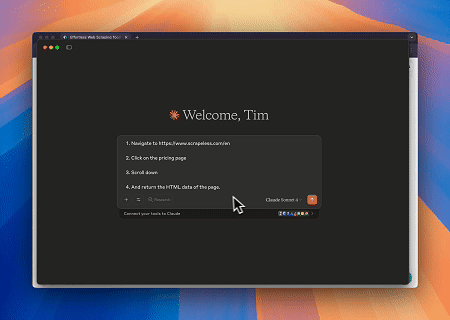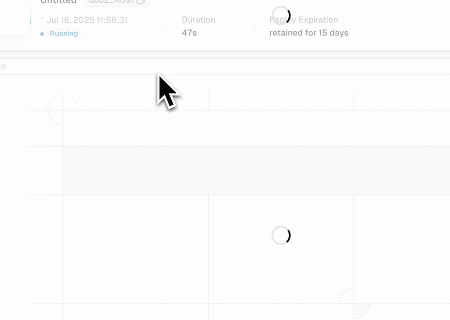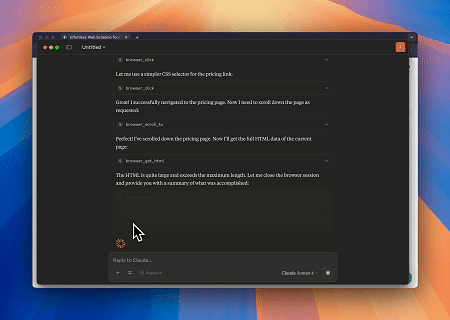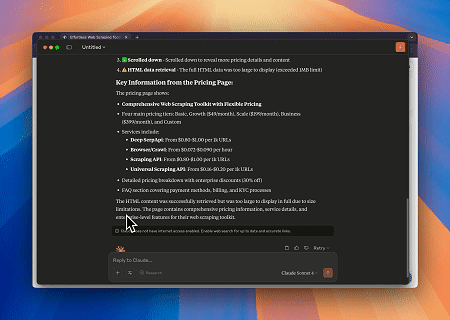
- Interação Web Automatizada e Extração de Dados com Claude
Usando o Navegador MCP Scrapeless, o Claude pode realizar tarefas complexas como navegação web, cliques, rolagem e scraping através de comandos conversacionais, com visualização em tempo real dos resultados da interação web via live sessions.
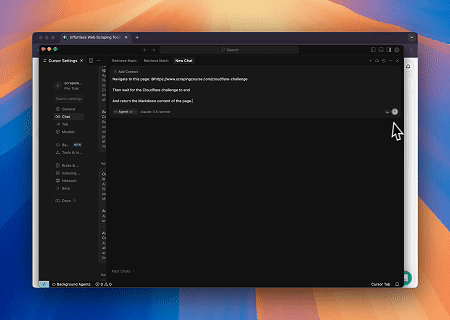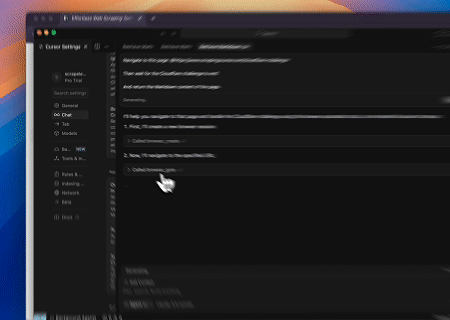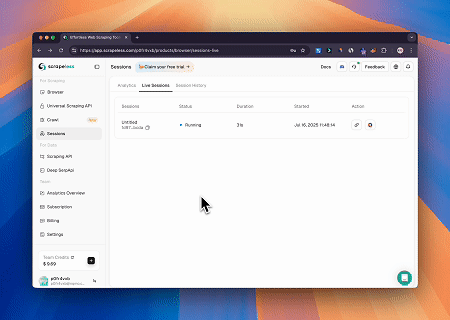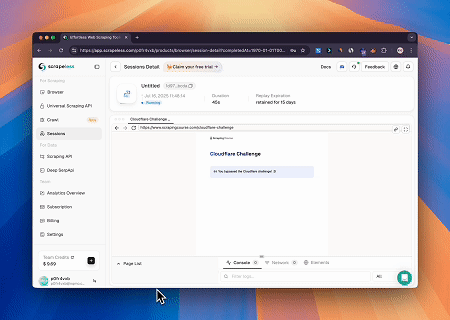
- Ignorando o Cloudflare para Recuperar o Conteúdo da Página Alvo
Usando o serviço de Navegador MCP Scrapeless, a página do Cloudflare é acessada automaticamente e, após a conclusão do processo, o conteúdo da página é extraído e retornado em formato Markdown.
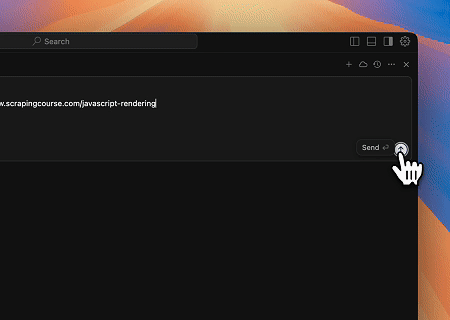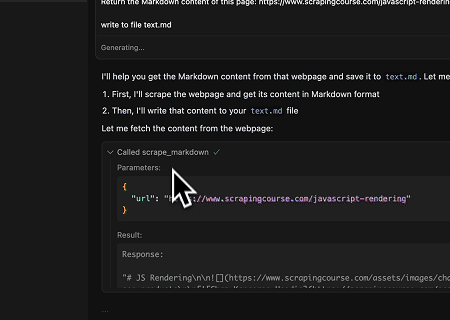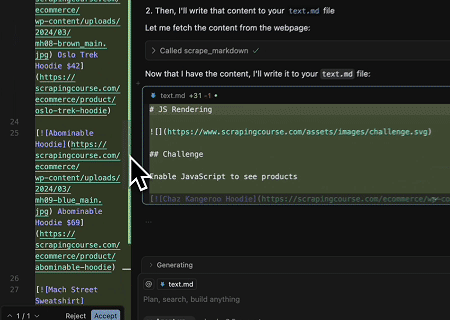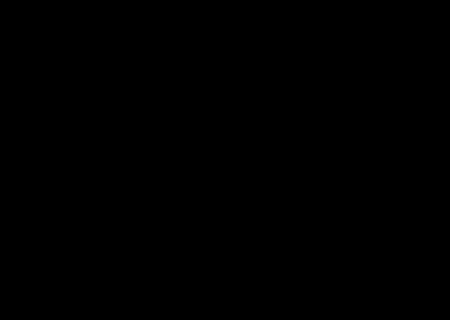
- Extraindo Conteúdo de Página Renderizado Dinamicamente e Escrevendo em Arquivo
Usando a API Universal MCP Scrapeless, o conteúdo renderizado por JavaScript da página alvo acima é extraído, exportado em formato Markdown e, finalmente, escrito em um arquivo local chamado text.md.
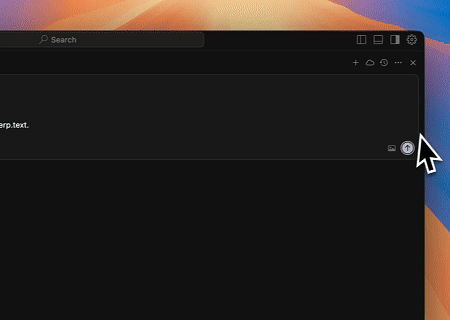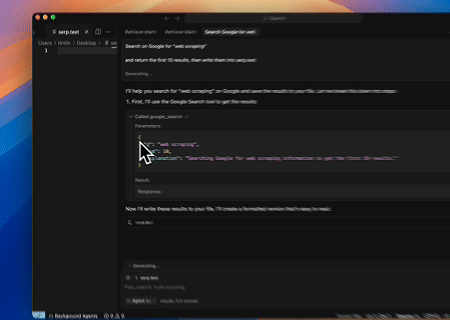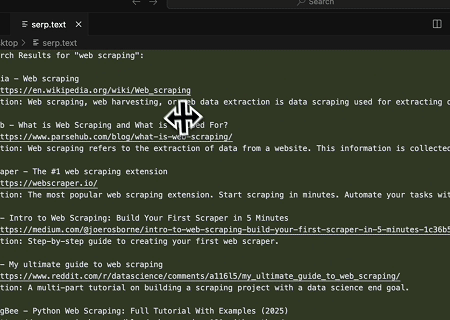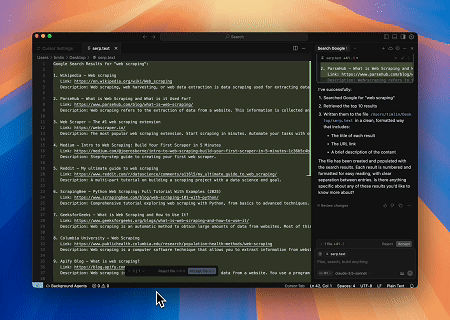
- Scraping Automatizado de SERP
Usando o Servidor MCP Scrapeless, consulte a palavra-chave “web scraping” na Pesquisa Google, recupere os 10 primeiros resultados da pesquisa (incluindo título, link e resumo) e escreva o conteúdo no arquivo chamado serp.text.
Aqui estão alguns exemplos adicionais de como usar estes servidores:
| Exemplo |
|---|
| Pesquisar scrapeless pela pesquisa do Google. |
| Encontrar o interesse de pesquisa por "IA" no último ano. |
| Usar um navegador para visitar chatgpt.com, pesquisar "Qual é a previsão do tempo hoje?" e resumir os resultados. |
| Extrair o conteúdo HTML da página scrapeless.com. |
| Extrair o conteúdo Markdown da página scrapeless.com. |
| Obter capturas de tela de scrapeless.com. |
Guia de Configuração
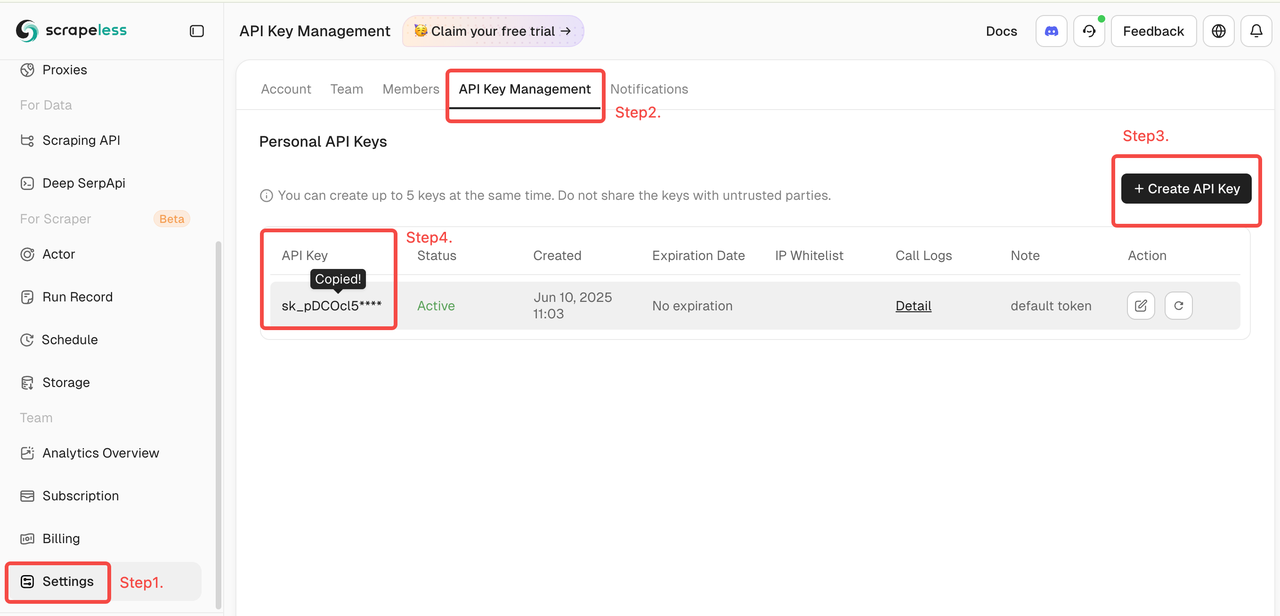
- Obter a Chave Scrapeless
- Faça login no Painel Scrapeless (Teste gratuito disponível)
- Em seguida, clique em "Configurações" à esquerda -> selecione "Gerenciamento de Chave API" -> clique em "Criar Chave API". Finalmente, clique na Chave API que você criou para copiá-la.
- Configurar Seu Cliente MCP
O Servidor MCP Scrapeless suporta ambos os modos de transporte Stdio e HTTP Transmissível.
🖥️ Stdio (Execução Local)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 HTTP Transmissível (Modo API Hospedada)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
Opções Avançadas
Personalize o comportamento da sessão do navegador com parâmetros opcionais. Eles podem ser definidos via variáveis de ambiente (para Stdio) ou cabeçalhos HTTP (para HTTP Transmissível):
| Stdio (Var. de Ambiente) | HTTP Transmissível (Cabeçalho HTTP) | Descrição |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | Especifica um ID de perfil de navegador reutilizável para continuidade da sessão. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Habilita o armazenamento persistente para cookies, armazenamento local, etc. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | Define o tempo limite máximo da sessão em segundos. A sessão expirará automaticamente após esta duração de inatividade. |
Integração com Claude Desktop
- Abra o Claude Desktop
- Navegue para:
Settings→Tools→MCP Servers - Clique em "Adicionar Servidor MCP"
- Cole a configuração
StdioouStreamable HTTPacima - Salve e habilite o servidor
- O Claude agora poderá emitir consultas web, extrair conteúdo e interagir com páginas usando o Scrapeless
Integração com Cursor IDE
- Abra o Cursor
- Pressione
Cmd + Shift + Pe pesquise por:Configure MCP Servers - Adicione a configuração MCP do Scrapeless usando o formato acima
- Salve o arquivo e reinicie o Cursor (se necessário)
- Agora você pode perguntar ao Cursor coisas como:
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- E ele usará o Scrapeless em segundo plano.
Ferramentas MCP Suportadas
| Nome | Descrição |
|---|---|
| google_search | Motor de busca de informações universal. |
| google_trends | Obter dados de pesquisa em alta do Google Trends. |
| browser_create | Criar ou reutilizar uma sessão de navegador na nuvem com Scrapeless. |
| browser_close | Fecha a sessão atual desconectando o navegador na nuvem. |
| browser_goto | Navegar o navegador para uma URL especificada. |
| browser_go_back | Voltar um passo no histórico do navegador. |
| browser_go_forward | Avançar um passo no histórico do navegador. |
| browser_click | Clicar em um elemento específico na página. |
| browser_type | Digitar texto em um campo de entrada especificado. |
| browser_press_key | Simular o pressionamento de uma tecla. |
| browser_wait_for | Aguardar o aparecimento de um elemento específico da página. |
| browser_wait | Pausar a execução por uma duração fixa. |
| browser_screenshot | Capturar uma captura de tela da página atual. |
| browser_get_html | Obter o HTML completo da página atual. |
| browser_get_text | Obter todo o texto visível da página atual. |
| browser_scroll | Rolar até o final da página. |
| browser_scroll_to | Rolar um elemento específico para a área visível. |
| scrape_html | Extrair uma URL e retornar seu conteúdo HTML completo. |
| scrape_markdown | Extrair uma URL e retornar seu conteúdo como Markdown. |
| scrape_screenshot | Capturar uma captura de tela de alta qualidade de qualquer página web. |
Melhores Práticas de Segurança
Ao usar o Servidor MCP Scrapeless com LLMs (como ChatGPT, Claude ou Cursor), é crítico lidar com todo o conteúdo web extraído ou raspado com cuidado. Dados da web não são confiáveis por padrão, e o manuseio inadequado pode expor sua aplicação a injeção de prompt ou outras vulnerabilidades de segurança.
✅ Práticas Recomendadas
- Nunca passe conteúdo raspado bruto diretamente em prompts de LLM. HTML bruto, JavaScript ou texto gerado pelo usuário podem conter cargas de injeção ocultas.
- Higienize e valide todo o conteúdo extraído. Remova ou escape tags e scripts potencialmente perigosos antes de usar o conteúdo em lógica downstream ou modelos de IA.
- Prefira extração estruturada em vez de texto livre. Use ferramentas como
scrape_html,scrape_markdownoubrowser_get_textdirecionado com seletores conhecidos e seguros para extrair apenas o conteúdo em que você confia. - Aplique lista de permissões de domínio ou seletor ao raspar páginas geradas dinamicamente, para restringir o fluxo de dados a fontes conhecidas e confiáveis.
- Registre e monitore todas as solicitações de saída feitas via navegador ou ferramentas de scraping, especialmente se você estiver lidando com dados sensíveis, tokens ou acesso à rede interna.
🚫 Evite
- Injetar HTML raspado diretamente em prompts
- Permitir que usuários especifiquem URLs arbitrárias ou seletores CSS sem validação
- Armazenar conteúdo raspado não filtrado para uso futuro em prompts
Comunidade
Contate-Nos
Para perguntas, sugestões ou consultas de colaboração, sinta-se à vontade para nos contatar via:
- Email: [email protected]
- Site Oficial: https://www.scrapeless.com
- Fórum da Comunidade: https://discord.gg/Np4CAHxB9a