Scrapeless MCP Server
resmiIntegrasikan hasil Google SERP real-time dari Scrapeless (Google Search, Google Flight, Google Map, Google Jobs, dll.) ke dalam aplikasi LLM Anda. Server ini memungkinkan pengambilan konteks dinamis untuk alur kerja AI, chatbot, dan alat riset.
Dokumentasi

Scrapeless MCP Server
Selamat datang di Scrapeless Model Context Protocol (MCP) Server resmi — lapisan integrasi canggih yang memberdayakan LLM, Agen AI, dan aplikasi AI untuk berinteraksi dengan web secara real time.
Dibangun berdasarkan standar MCP terbuka, Scrapeless MCP Server menghubungkan model seperti ChatGPT, Claude, serta alat seperti Cursor dan Windsurf ke berbagai kemampuan eksternal, termasuk:
- Integrasi layanan Google (Search, Trends)
- Otomasi browser untuk navigasi dan interaksi tingkat halaman
- Scrape situs dinamis dengan JavaScript berat—ekspor sebagai HTML, Markdown, atau tangkapan layar
Baik Anda membangun asisten riset AI, copilot pengkodean, atau agen web otonom, server ini menyediakan konteks dinamis dan data dunia nyata yang dibutuhkan alur kerja Anda—tanpa diblokir.
Contoh Penggunaan
- Interaksi Web Otomatis dan Ekstraksi Data dengan Claude
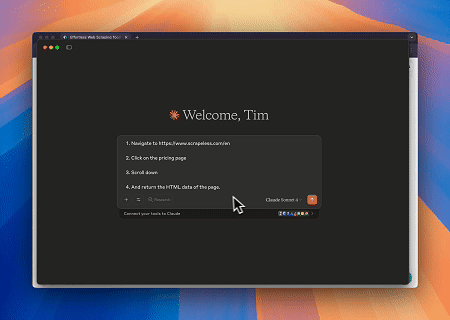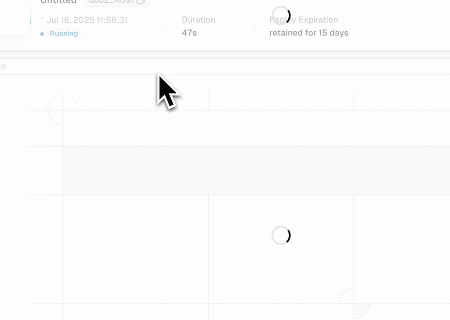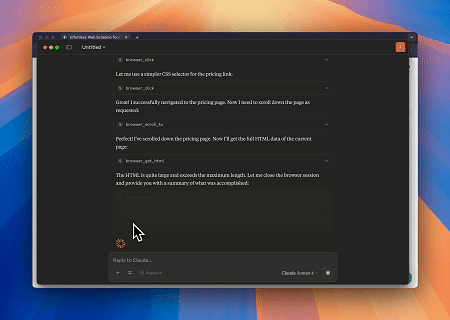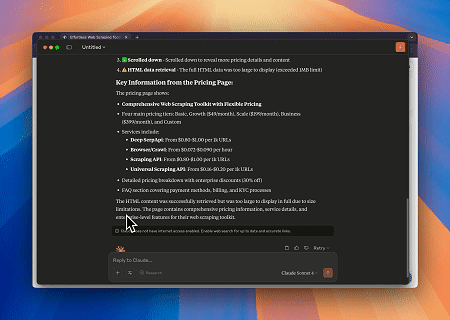
Menggunakan Scrapeless MCP Browser, Claude dapat melakukan tugas kompleks seperti navigasi web, mengklik, menggulir, dan scraping melalui perintah percakapan, dengan pratinjau real-time hasil interaksi web melalui live sessions.
- Melewati Cloudflare untuk Mengambil Konten Halaman Target
Menggunakan layanan Scrapeless MCP Browser, halaman Cloudflare diakses secara otomatis, dan setelah proses selesai, konten halaman diekstraksi dan dikembalikan dalam format Markdown.
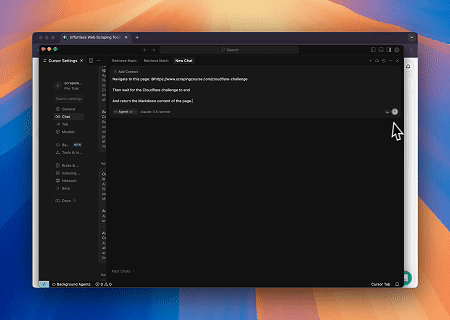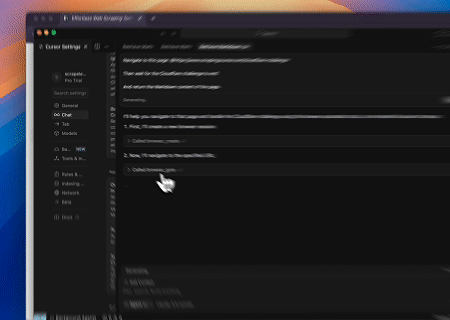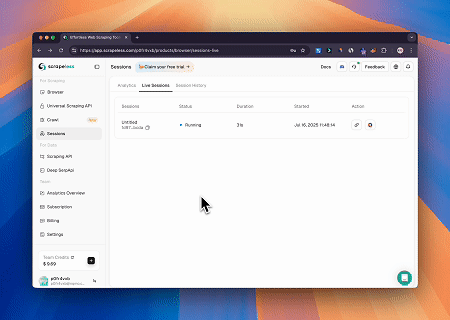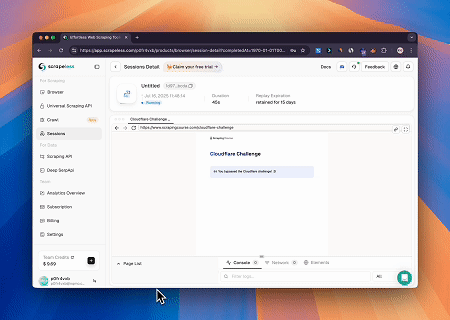
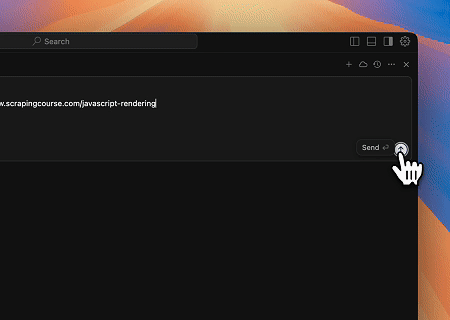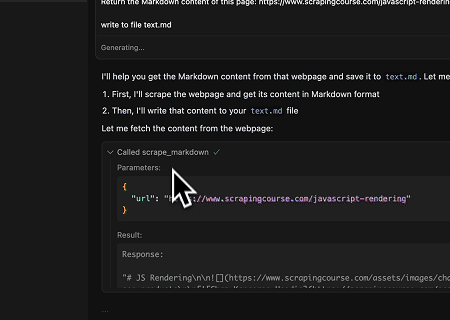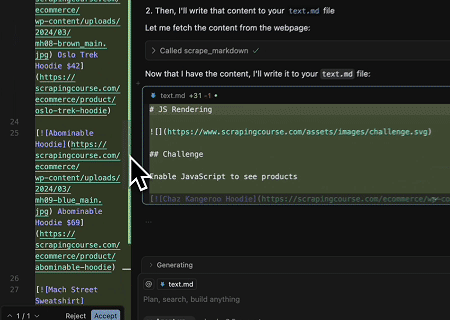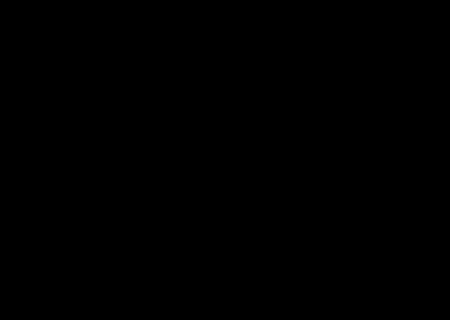
- Mengekstrak Konten Halaman yang Dirender Dinamis dan Menulis ke File
Menggunakan Scrapeless MCP Universal API, konten yang dirender JavaScript dari halaman target di atas di-scrape, diekspor dalam format Markdown, dan akhirnya ditulis ke file lokal bernama text.md.
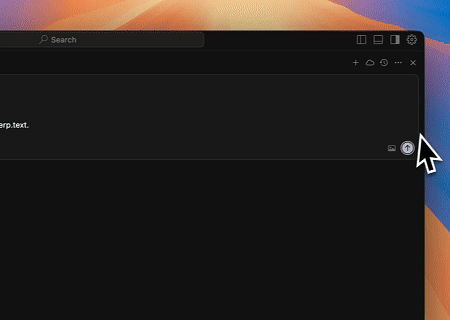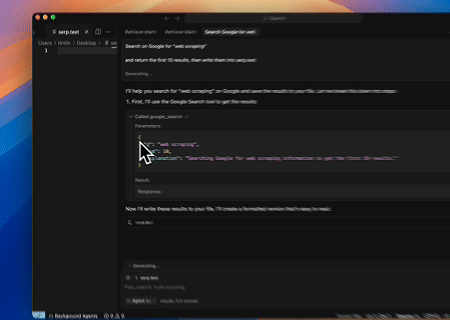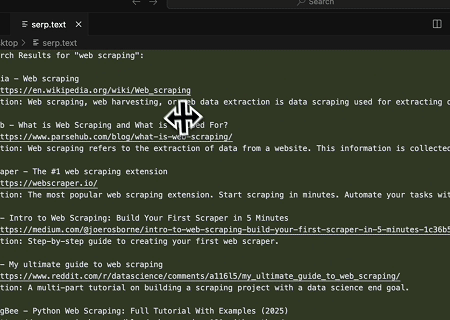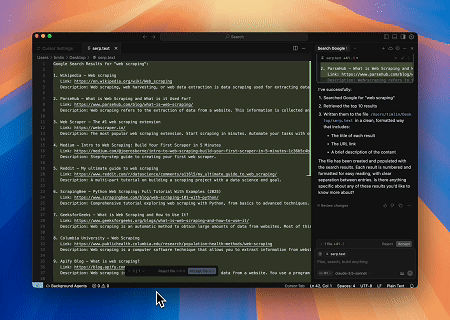
- Scraping SERP Otomatis
Menggunakan Scrapeless MCP Server, kueri kata kunci “web scraping” di Google Search, ambil 10 hasil pencarian pertama (termasuk judul, tautan, dan ringkasan), dan tulis kontennya ke file bernama serp.text.
Berikut beberapa contoh tambahan tentang cara menggunakan server ini:
| Contoh |
|---|
| Cari scrapeless dengan pencarian Google. |
| Temukan minat pencarian untuk "AI" selama setahun terakhir. |
| Gunakan browser untuk mengunjungi chatgpt.com, cari "Bagaimana cuaca hari ini?", dan ringkas hasilnya. |
| Scrape konten HTML halaman scrapeless.com. |
| Scrape konten Markdown halaman scrapeless.com. |
| Dapatkan tangkapan layar scrapeless.com. |
Panduan Pengaturan
- Dapatkan Kunci Scrapeless
- Masuk ke Dasbor Scrapeless (Uji coba gratis tersedia)
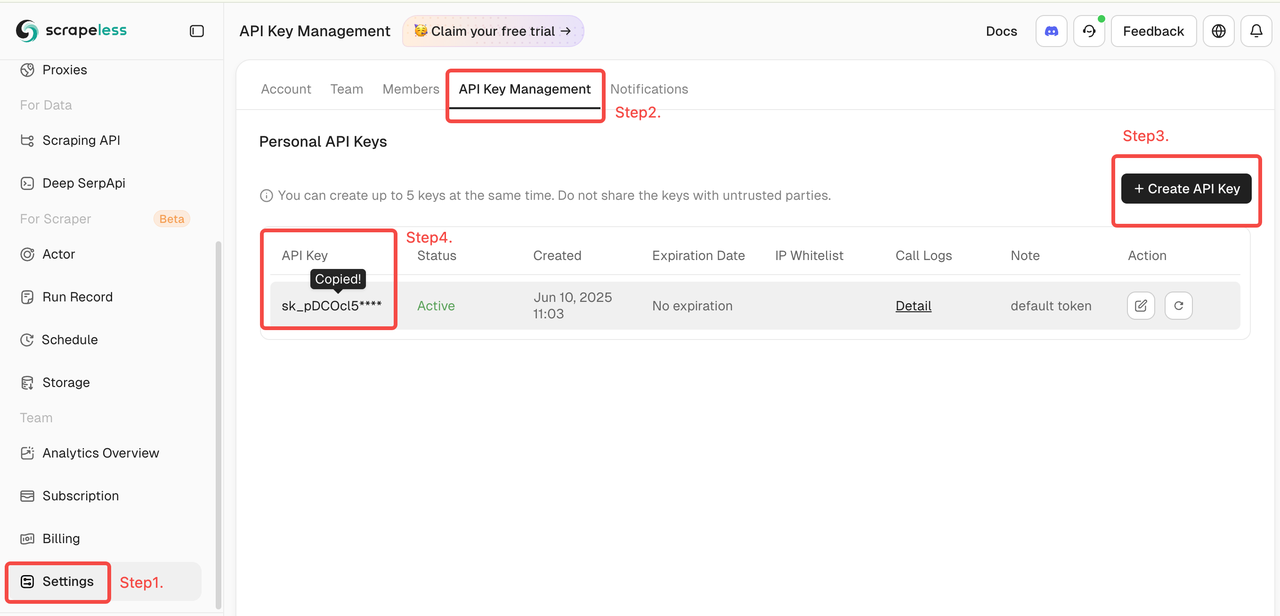
- Lalu klik "Pengaturan" di sebelah kiri -> pilih "Manajemen Kunci API" -> klik "Buat Kunci API". Terakhir, klik Kunci API yang Anda buat untuk menyalinnya.
- Konfigurasikan Klien MCP Anda
Scrapeless MCP Server mendukung mode transport Stdio dan Streamable HTTP.
🖥️ Stdio (Eksekusi Lokal)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 Streamable HTTP (Mode API Terhosting)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
Opsi Lanjutan
Sesuaikan perilaku sesi browser dengan parameter opsional. Ini dapat diatur melalui variabel lingkungan (untuk Stdio) atau header HTTP (untuk Streamable HTTP):
| Stdio (Var Lingkungan) | Streamable HTTP (Header HTTP) | Deskripsi |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | Menentukan ID profil browser yang dapat digunakan kembali untuk kontinuitas sesi. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Mengaktifkan penyimpanan persisten untuk cookie, penyimpanan lokal, dll. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | Menentukan batas waktu sesi maksimum dalam detik. Sesi akan otomatis berakhir setelah durasi tidak aktif ini. |
Integrasi dengan Claude Desktop
- Buka Claude Desktop
- Arahkan ke:
Settings→Tools→MCP Servers - Klik "Tambahkan MCP Server"
- Tempelkan konfigurasi
StdioatauStreamable HTTPdi atas - Simpan dan aktifkan server
- Claude sekarang dapat mengeluarkan kueri web, mengekstrak konten, dan berinteraksi dengan halaman menggunakan Scrapeless
Integrasi dengan Cursor IDE
- Buka Cursor
- Tekan
Cmd + Shift + Pdan cari:Configure MCP Servers - Tambahkan konfigurasi Scrapeless MCP menggunakan format di atas
- Simpan file dan mulai ulang Cursor (jika perlu)
- Sekarang Anda dapat menanyakan hal-hal seperti ini kepada Cursor:
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- Dan itu akan menggunakan Scrapeless di latar belakang.
Alat MCP yang Didukung
| Nama | Deskripsi |
|---|---|
| google_search | Mesin pencari informasi universal. |
| google_trends | Dapatkan data pencarian trending dari Google Trends. |
| browser_create | Buat atau gunakan kembali sesi browser cloud menggunakan Scrapeless. |
| browser_close | Menutup sesi saat ini dengan memutuskan browser cloud. |
| browser_goto | Arahkan browser ke URL yang ditentukan. |
| browser_go_back | Mundur satu langkah dalam riwayat browser. |
| browser_go_forward | Maju satu langkah dalam riwayat browser. |
| browser_click | Klik elemen tertentu di halaman. |
| browser_type | Ketik teks ke dalam bidang input yang ditentukan. |
| browser_press_key | Simulasikan penekanan tombol. |
| browser_wait_for | Tunggu hingga elemen halaman tertentu muncul. |
| browser_wait | Jeda eksekusi untuk durasi tetap. |
| browser_screenshot | Tangkap tangkapan layar halaman saat ini. |
| browser_get_html | Dapatkan HTML lengkap dari halaman saat ini. |
| browser_get_text | Dapatkan semua teks yang terlihat dari halaman saat ini. |
| browser_scroll | Gulir ke bagian bawah halaman. |
| browser_scroll_to | Gulir elemen tertentu ke dalam tampilan. |
| scrape_html | Scrape URL dan kembalikan konten HTML lengkapnya. |
| scrape_markdown | Scrape URL dan kembalikan kontennya sebagai Markdown. |
| scrape_screenshot | Tangkap tangkapan layar berkualitas tinggi dari halaman web mana pun. |
Praktik Terbaik Keamanan
Saat menggunakan Scrapeless MCP Server dengan LLM (seperti ChatGPT, Claude, atau Cursor), sangat penting untuk menangani semua konten web yang di-scrape atau diekstraksi dengan hati-hati. Data web tidak tepercaya secara default, dan penanganan yang tidak tepat dapat mengekspos aplikasi Anda terhadap injeksi prompt atau kerentanan keamanan lainnya.
✅ Praktik yang Direkomendasikan
- Jangan pernah meneruskan konten mentah yang di-scrape langsung ke prompt LLM. HTML mentah, JavaScript, atau teks buatan pengguna mungkin berisi muatan injeksi tersembunyi.
- Sanitasi dan validasi semua konten yang diekstraksi. Hapus atau escape tag dan skrip yang berpotensi berbahaya sebelum menggunakan konten dalam logika hilir atau model AI.
- Utamakan ekstraksi terstruktur daripada teks bebas. Gunakan alat seperti
scrape_html,scrape_markdown, ataubrowser_get_textyang ditargetkan dengan pemilih yang dikenal aman untuk hanya mengekstrak konten yang Anda percayai. - Terapkan whitelisting domain atau pemilih saat scraping halaman yang dihasilkan secara dinamis, untuk membatasi aliran data ke sumber yang dikenal dan tepercaya.
- Catat dan pantau semua permintaan keluar yang dibuat melalui alat browser atau scraping, terutama jika Anda menangani data sensitif, token, atau akses jaringan internal.
🚫 Hindari
- Menyuntikkan HTML yang di-scrape langsung ke prompt
- Membiarkan pengguna menentukan URL arbitrer atau pemilih CSS tanpa validasi
- Menyimpan konten yang di-scrape tanpa filter untuk penggunaan prompt di masa mendatang
Komunitas
Hubungi Kami
Untuk pertanyaan, saran, atau permintaan kolaborasi, jangan ragu untuk menghubungi kami melalui:
- Email: [email protected]
- Situs Web Resmi: https://www.scrapeless.com
- Forum Komunitas: https://discord.gg/Np4CAHxB9a