Urlbox Full Page Screenshots
oficialUn servidor MCP para la API de capturas de pantalla de Urlbox. Permite a tu cliente tomar capturas de pantalla, generar PDFs, extraer HTML/markdown y más desde sitios web.
¿Qué puedes hacer con Urlbox Full Page Screenshots MCP?
- Capturar capturas de pantalla de sitios web — Usa la herramienta
renderpara tomar capturas de pantalla en PNG, PDF o MP4 de cualquier URL. - Extraer contenido de la página como HTML o Markdown — Recupera el HTML completo de una página o conviértelo a Markdown para su posterior procesamiento.
- Generar PDFs etiquetados con esquemas — Renderiza un PDF de página completa con etiquetado de accesibilidad y esquemas de documento.
- Bloquear anuncios y banners de cookies — Configura la herramienta
renderpara ocultar anuncios y descartar los banners de consentimiento de cookies en las capturas de pantalla. - Guardar renders localmente — Establece
store_renders: truepara descargar capturas de pantalla, PDFs o contenido extraído directamente a tu computadora.
Documentación
Servidor MCP de Urlbox
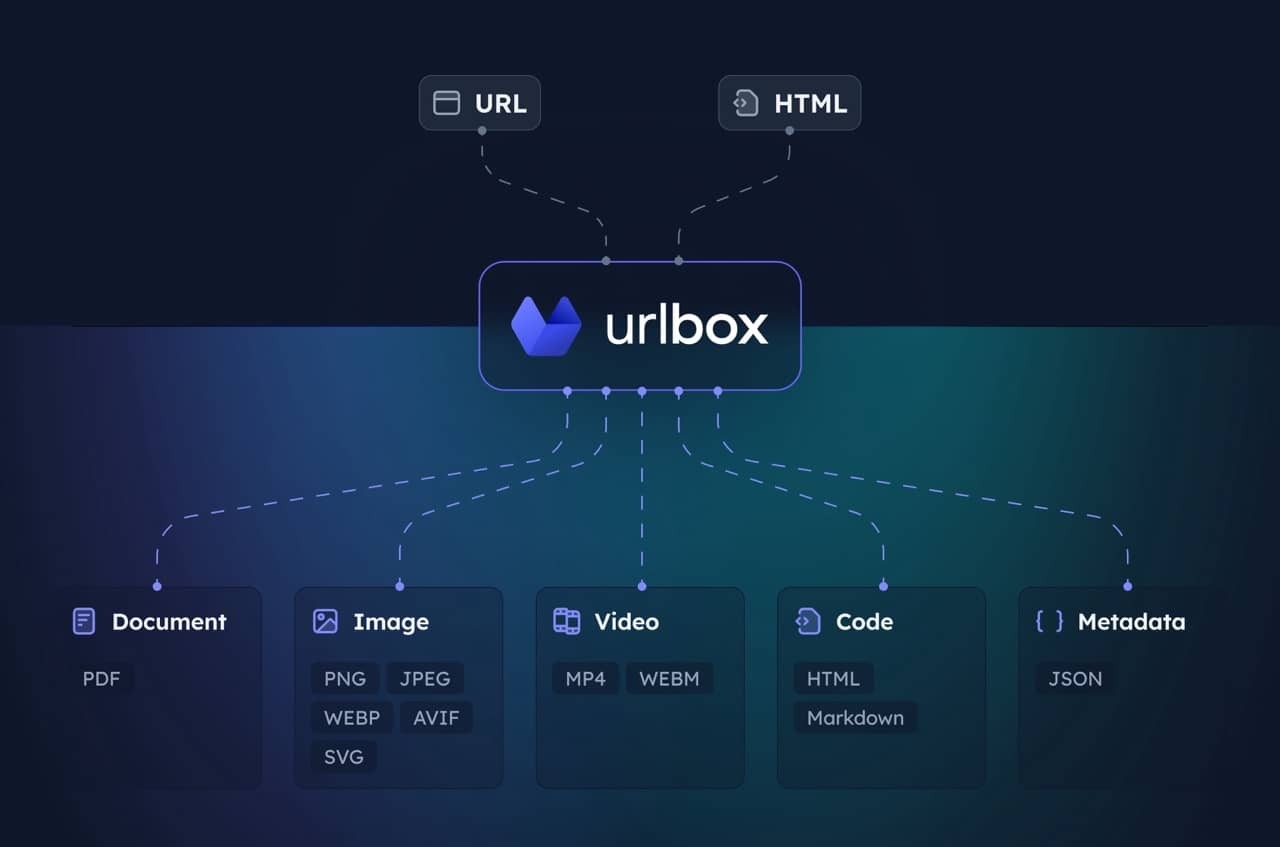
Servidor MCP para la Urlbox API de Capturas de Pantalla. Permite a tu cliente tomar capturas de pantalla, generar PDFs, extraer HTML/markdown y más desde sitios web.
Visita Urlbox para más información, y lee nuestra documentación o chatea con tu LLM después de la instalación para entender bien sus opciones y capacidades.
Configuración
-
Instalar dependencias y compilar:
npm install npm run build -
Obtener credenciales de la API de Urlbox:
- Regístrate en urlbox.com
- Obtén tu Secreto de API desde el panel de control
-
Establecer variables de entorno:
claude_desktop_config.json
{
"mcpServers": {
"screenshot": {
"command": "npx",
"args": ["-y", "@urlbox/screenshot-mcp"],
"env": {
"SECRET_KEY": "your_api_key_here"
}
}
}
}
Uso
El servidor proporciona una herramienta render que puede:
- Tomar capturas de pantalla en múltiples formatos (PNG, PDF, MP4 y más)
- Convertir páginas a HTML, markdown
- Extraer metadatos y cookies
- Guardar archivos localmente en tus descargas con
store_renders: true
Claude usará esto automáticamente cuando le pidas que capture sitios web o convierta contenido web.
Prompts útiles
Tomar una captura de pantalla limpia sin anuncios ni banners de cookies:
Take a screenshot of https://example.com but block ads and hide cookie banners
Capturar y guardar representaciones secundarias como HTML/markdown:
Take a screenshot of https://example.com and also save it as HTML and markdown. Download the result to my computer.
Generar un PDF de la página completa:
Convert https://urlbox.com to a PDF and save it to my computer. Make sure to generate a PDF that has an outline and is tagged.