Scrapeless MCP Server
oficialIntegra resultados en tiempo real de Scrapeless Google SERP (Google Search, Google Flight, Google Map, Google Jobs...) en tus aplicaciones LLM. Este servidor permite la recuperación dinámica de contexto para flujos de trabajo de IA, chatbots y herramientas de investigación.
Documentación

Servidor MCP de Scrapeless
Bienvenido al Servidor oficial de Protocolo de Contexto de Modelo (MCP) de Scrapeless — una potente capa de integración que permite a los LLMs, Agentes de IA y aplicaciones de IA interactuar con la web en tiempo real.
Construido sobre el estándar abierto MCP, el Servidor MCP de Scrapeless conecta de forma fluida modelos como ChatGPT, Claude y herramientas como Cursor y Windsurf a una amplia gama de capacidades externas, incluyendo:
- Integración de servicios de Google (Search, Trends)
- Automatización de navegador para navegación e interacción a nivel de página
- Extracción de sitios dinámicos con mucho JavaScript: exporta como HTML, Markdown o capturas de pantalla
Ya sea que estés construyendo un asistente de investigación de IA, un copiloto de codificación o agentes web autónomos, este servidor proporciona el contexto dinámico y los datos del mundo real que tus flujos de trabajo necesitan—sin ser bloqueado.
Ejemplos de Uso
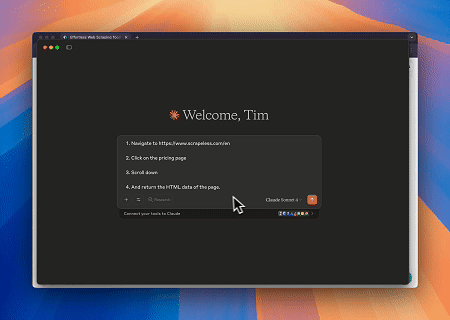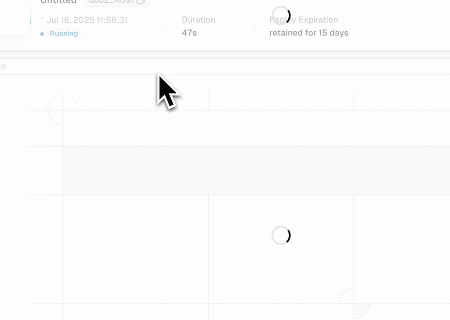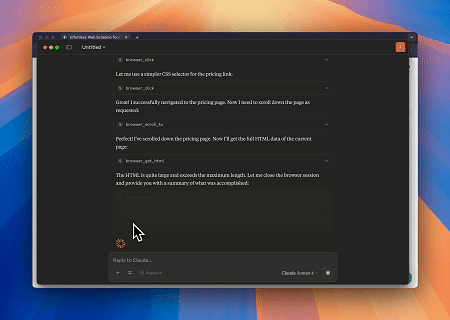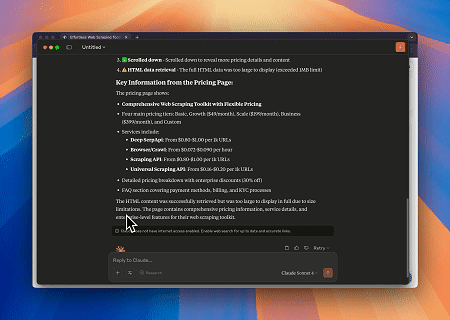
- Interacción Web Automatizada y Extracción de Datos con Claude
Usando el Navegador MCP de Scrapeless, Claude puede realizar tareas complejas como navegación web, clics, desplazamiento y extracción mediante comandos conversacionales, con vista previa en tiempo real de los resultados de la interacción web a través de live sessions.
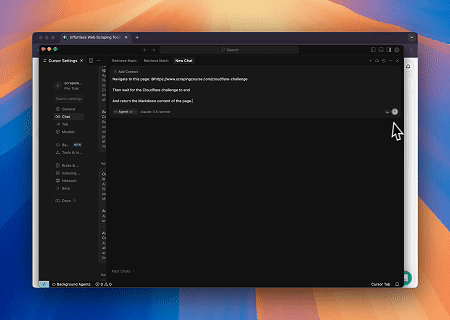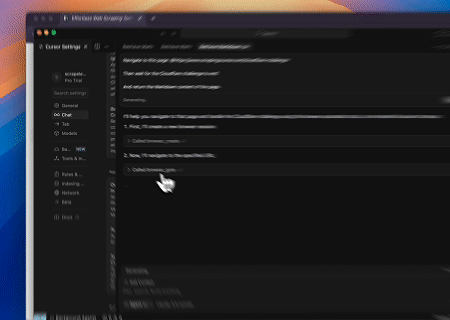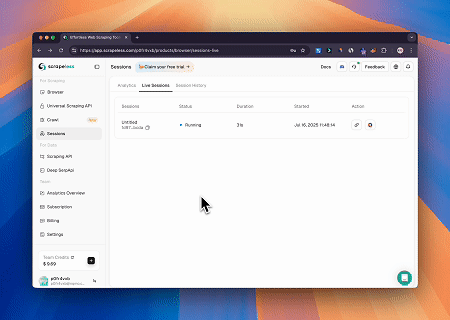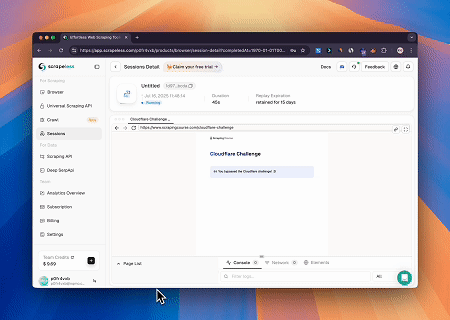
- Evitar Cloudflare para Recuperar el Contenido de la Página Objetivo
Usando el servicio de Navegador MCP de Scrapeless, se accede automáticamente a la página de Cloudflare y, una vez completado el proceso, se extrae el contenido de la página y se devuelve en formato Markdown.
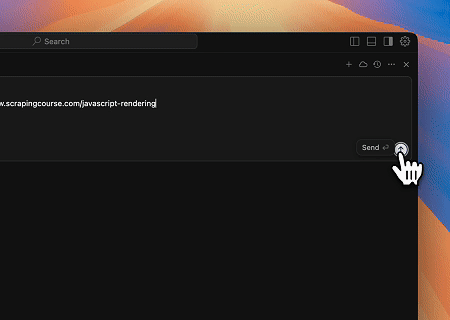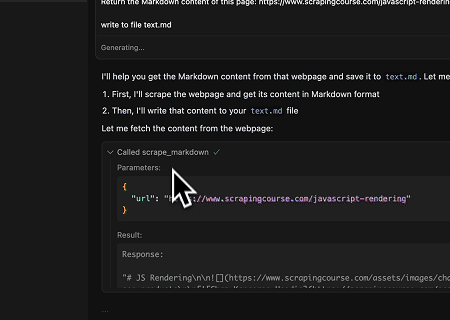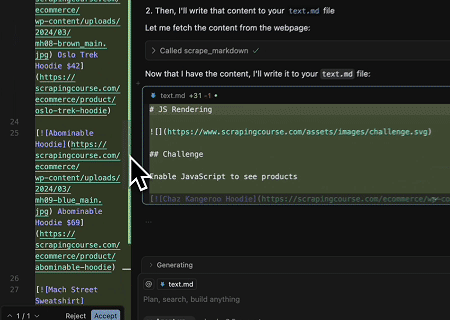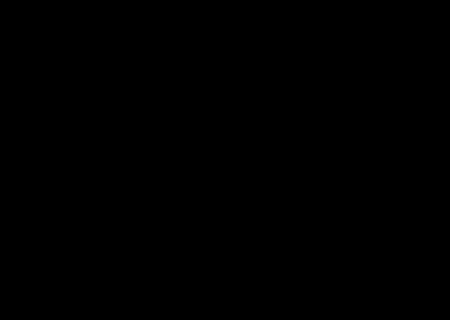
- Extraer Contenido de Página Renderizado Dinámicamente y Escribirlo en un Archivo
Usando la API Universal MCP de Scrapeless, se extrae el contenido renderizado con JavaScript de la página objetivo anterior, se exporta en formato Markdown y finalmente se escribe en un archivo local llamado text.md.
- Extracción Automatizada de SERP
Usando el Servidor MCP de Scrapeless, consulta la palabra clave “web scraping” en Google Search, recupera los primeros 10 resultados de búsqueda (incluyendo título, enlace y resumen) y escribe el contenido en el archivo llamado serp.text.
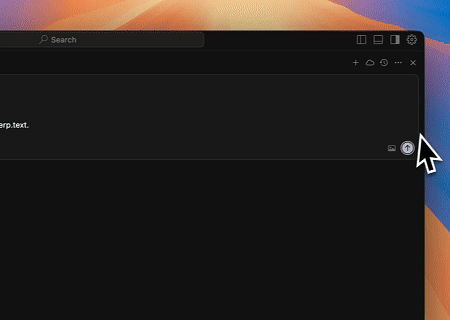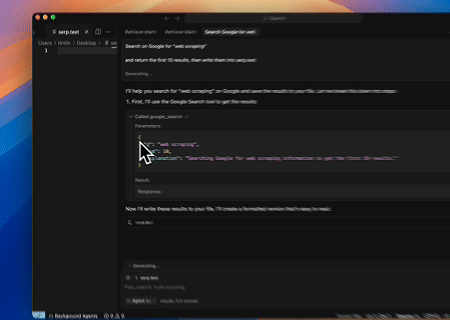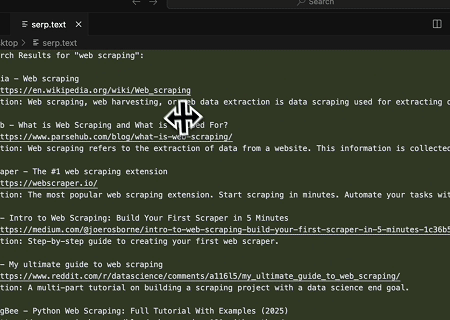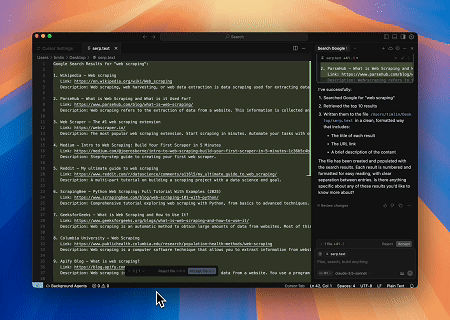
Aquí hay algunos ejemplos adicionales de cómo usar estos servidores:
| Ejemplo |
|---|
| Buscar scrapeless mediante búsqueda de Google. |
| Encontrar el interés de búsqueda para "IA" durante el último año. |
| Usar un navegador para visitar chatgpt.com, buscar "¿Qué tiempo hace hoy?" y resumir los resultados. |
| Extraer el contenido HTML de la página scrapeless.com. |
| Extraer el contenido Markdown de la página scrapeless.com. |
| Obtener capturas de pantalla de scrapeless.com. |
Guía de Configuración
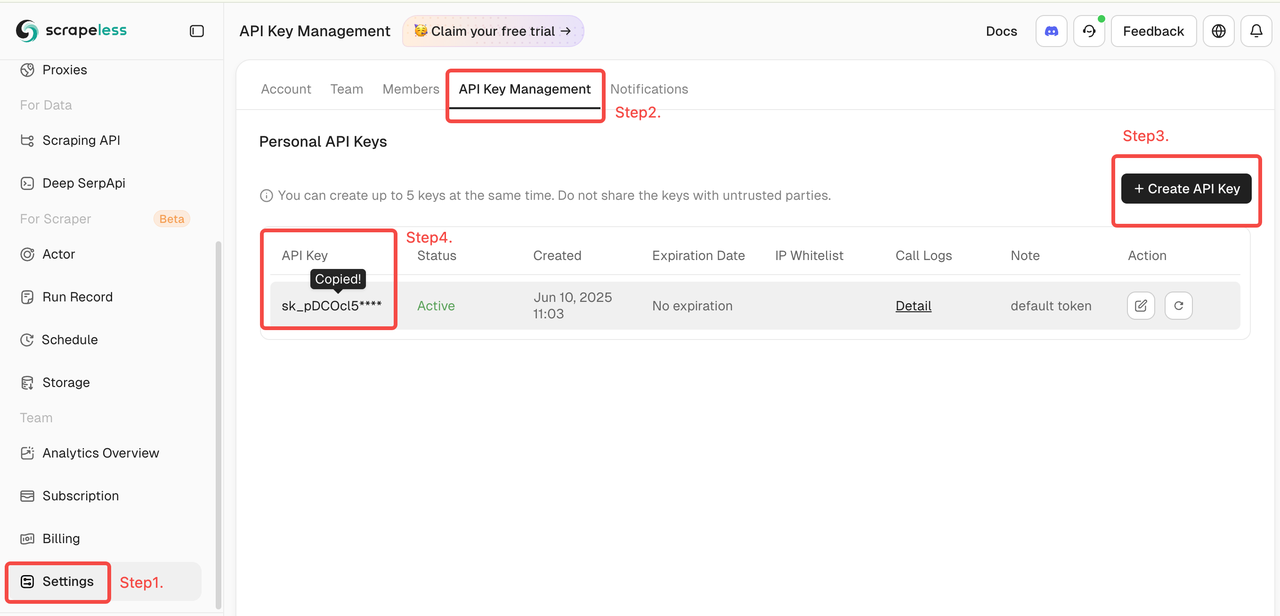
- Obtener la Clave de Scrapeless
- Inicia sesión en el Panel de Scrapeless (Prueba gratuita disponible)
- Luego haz clic en "Configuración" a la izquierda -> selecciona "Gestión de Claves API" -> haz clic en "Crear Clave API". Finalmente, haz clic en la Clave API que creaste para copiarla.
- Configurar tu Cliente MCP
El Servidor MCP de Scrapeless soporta los modos de transporte Stdio y HTTP Transmisible.
🖥️ Stdio (Ejecución Local)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 HTTP Transmisible (Modo API Alojado)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
Opciones Avanzadas
Personaliza el comportamiento de la sesión del navegador con parámetros opcionales. Estos se pueden establecer mediante variables de entorno (para Stdio) o cabeceras HTTP (para HTTP Transmisible):
| Stdio (Var. Entorno) | HTTP Transmisible (Cabecera HTTP) | Descripción |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | Especifica un ID de perfil de navegador reutilizable para la continuidad de la sesión. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Habilita el almacenamiento persistente para cookies, almacenamiento local, etc. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | Define el tiempo máximo de espera de sesión en segundos. La sesión expirará automáticamente después de esta duración de inactividad. |
Integración con Claude Desktop
- Abre Claude Desktop
- Navega a:
Settings→Tools→MCP Servers - Haz clic en "Añadir Servidor MCP"
- Pega la configuración
StdiooStreamable HTTPde arriba - Guarda y habilita el servidor
- Claude ahora podrá realizar consultas web, extraer contenido e interactuar con páginas usando Scrapeless
Integración con Cursor IDE
- Abre Cursor
- Presiona
Cmd + Shift + Py busca:Configure MCP Servers - Añade la configuración MCP de Scrapeless usando el formato de arriba
- Guarda el archivo y reinicia Cursor (si es necesario)
- Ahora puedes preguntar a Cursor cosas como:
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- Y usará Scrapeless en segundo plano.
Herramientas MCP Soportadas
| Nombre | Descripción |
|---|---|
| google_search | Motor de búsqueda de información universal. |
| google_trends | Obtener datos de tendencias de búsqueda de Google Trends. |
| browser_create | Crear o reutilizar una sesión de navegador en la nube con Scrapeless. |
| browser_close | Cierra la sesión actual desconectando el navegador en la nube. |
| browser_goto | Navegar el navegador a una URL especificada. |
| browser_go_back | Retroceder un paso en el historial del navegador. |
| browser_go_forward | Avanzar un paso en el historial del navegador. |
| browser_click | Hacer clic en un elemento específico de la página. |
| browser_type | Escribir texto en un campo de entrada especificado. |
| browser_press_key | Simular la pulsación de una tecla. |
| browser_wait_for | Esperar a que aparezca un elemento específico de la página. |
| browser_wait | Pausar la ejecución durante una duración fija. |
| browser_screenshot | Capturar una pantalla de la página actual. |
| browser_get_html | Obtener el HTML completo de la página actual. |
| browser_get_text | Obtener todo el texto visible de la página actual. |
| browser_scroll | Desplazarse hasta el final de la página. |
| browser_scroll_to | Desplazar un elemento específico a la vista. |
| scrape_html | Extraer una URL y devolver su contenido HTML completo. |
| scrape_markdown | Extraer una URL y devolver su contenido como Markdown. |
| scrape_screenshot | Capturar una pantalla de alta calidad de cualquier página web. |
Mejores Prácticas de Seguridad
Al usar el Servidor MCP de Scrapeless con LLMs (como ChatGPT, Claude o Cursor), es crítico manejar todo el contenido web extraído o raspado con cuidado. Los datos web no son de confianza por defecto, y un manejo inadecuado puede exponer tu aplicación a inyección de prompts u otras vulnerabilidades de seguridad.
✅ Prácticas Recomendadas
- Nunca pases contenido extraído sin procesar directamente a los prompts del LLM. El HTML, JavaScript o texto generado por el usuario sin procesar puede contener cargas útiles de inyección ocultas.
- Desinfecta y valida todo el contenido extraído. Elimina o escapa las etiquetas y scripts potencialmente dañinos antes de usar el contenido en la lógica posterior o en modelos de IA.
- Prefiere la extracción estructurada sobre el texto de formato libre. Usa herramientas como
scrape_html,scrape_markdownobrowser_get_textdirigido con selectores de confianza conocida para extraer solo el contenido en el que confías. - Aplica listas blancas de dominio o selector al extraer páginas generadas dinámicamente, para restringir el flujo de datos a fuentes conocidas y de confianza.
- Registra y monitoriza todas las solicitudes salientes realizadas a través del navegador o herramientas de extracción, especialmente si manejas datos sensibles, tokens o acceso a la red interna.
🚫 Evitar
- Inyectar HTML extraído directamente en los prompts
- Permitir que los usuarios especifiquen URLs o selectores CSS arbitrarios sin validación
- Almacenar contenido extraído sin filtrar para uso futuro en prompts
Comunidad
Contáctanos
Para preguntas, sugerencias o consultas de colaboración, no dudes en contactarnos a través de:
- Email: [email protected]
- Sitio Web Oficial: https://www.scrapeless.com
- Foro de la Comunidad: https://discord.gg/Np4CAHxB9a